 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Stochastic Dynamic Post-Disaster Inventory Allocation Problem with Trucks and UAVs
Nov 30, 2023
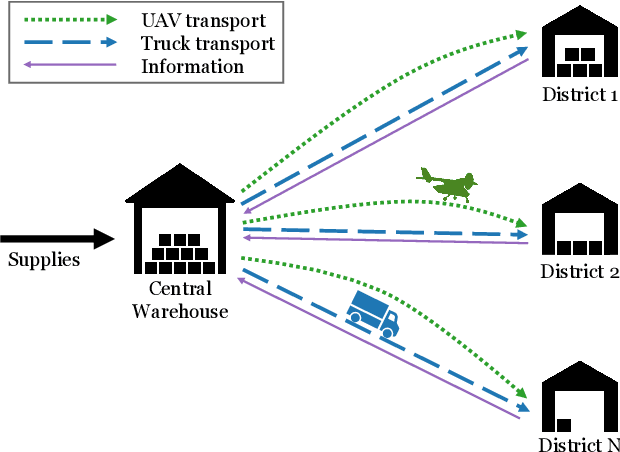
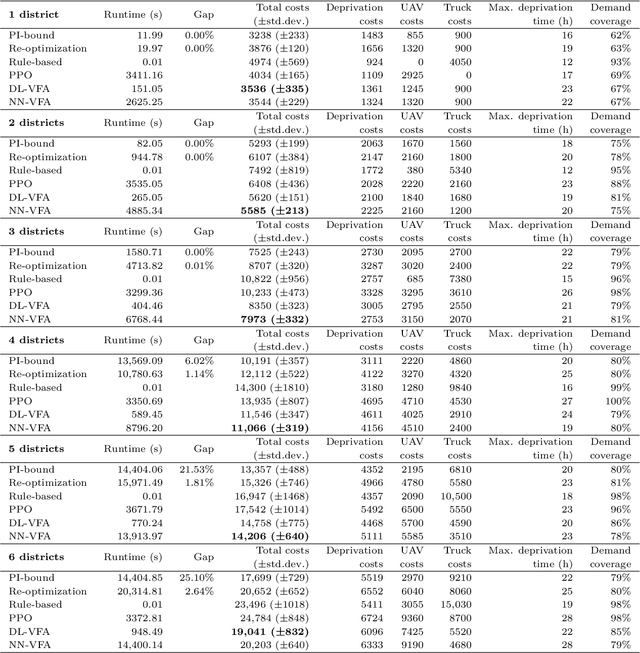
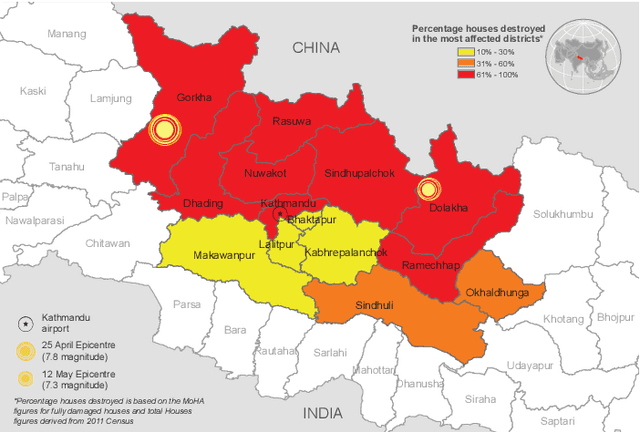
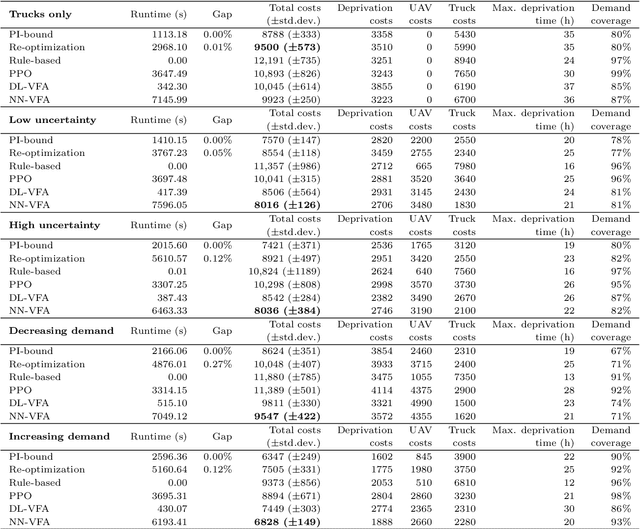
Humanitarian logistics operations face increasing difficulties due to rising demands for aid in disaster areas. This paper investigates the dynamic allocation of scarce relief supplies across multiple affected districts over time. It introduces a novel stochastic dynamic post-disaster inventory allocation problem with trucks and unmanned aerial vehicles delivering relief goods under uncertain supply and demand. The relevance of this humanitarian logistics problem lies in the importance of considering the inter-temporal social impact of deliveries. We achieve this by incorporating deprivation costs when allocating scarce supplies. Furthermore, we consider the inherent uncertainties of disaster areas and the potential use of cargo UAVs to enhance operational efficiency. This study proposes two anticipatory solution methods based on approximate dynamic programming, specifically decomposed linear value function approximation and neural network value function approximation to effectively manage uncertainties in the dynamic allocation process. We compare DL-VFA and NN-VFA with various state-of-the-art methods (exact re-optimization, PPO) and results show a 6-8% improvement compared to the best benchmarks. NN-VFA provides the best performance and captures nonlinearities in the problem, whereas DL-VFA shows excellent scalability against a minor performance loss. The experiments reveal that consideration of deprivation costs results in improved allocation of scarce supplies both across affected districts and over time. Finally, results show that deploying UAVs can play a crucial role in the allocation of relief goods, especially in the first stages after a disaster. The use of UAVs reduces transportation- and deprivation costs together by 16-20% and reduces maximum deprivation times by 19-40%, while maintaining similar levels of demand coverage, showcasing efficient and effective operations.
Pose Estimation and Tracking for ASIST
Nov 30, 2023Aircraft Ship Integrated Secure and Traverse (ASIST) is a system designed to arrest helicopters safely and efficiently on ships. Originally, a precision Helicopter Position Sensing Equipment (HPSE) tracked and monitored the position of the helicopter relative to the Rapid Securing Device (RSD). However, using the HPSE component was determined to be infeasible in the transition of the ASIST system due to the hardware installation requirements. As a result, sailors track the position of the helicopters with their eyes with no sensor or artificially intelligent decision aid. Manually tracking the helicopter takes additional time and makes recoveries more difficult, especially at high sea states. Performing recoveries without the decision aid leads to higher uncertainty and cognitive load. PETA (Pose Estimation and Tracking for ASIST) is a research effort to create a helicopter tracking system prototype without hardware installation requirements for ASIST system operators. Its overall goal is to improve situational awareness and reduce operator uncertainty with respect to the aircrafts position relative to the RSD, and consequently increase the allowable landing area. The authors produced a prototype system capable of tracking helicopters with respect to the RSD. The software included a helicopter pose estimation component, camera pose estimation component, and a user interface component. PETA demonstrated the potential for state-of-the-art computer vision algorithms Faster R-CNN and HRNet (High-Resolution Network) to be used to estimate the pose of helicopters in real-time, returning ASIST to its originally intended capability. PETA also demonstrated that traditional methods of encoder-decoders could be used to estimate the orientation of the helicopter and could be used to confirm the output from HRNet.
WavePlanes: A compact Wavelet representation for Dynamic Neural Radiance Fields
Dec 03, 2023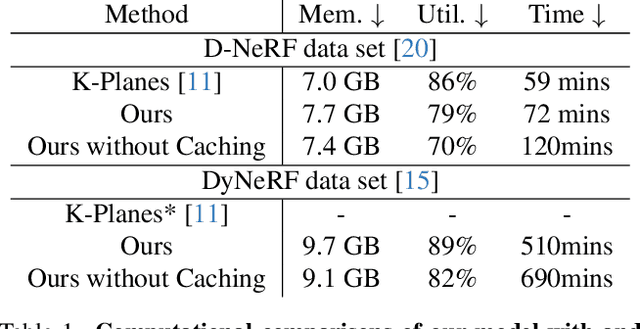
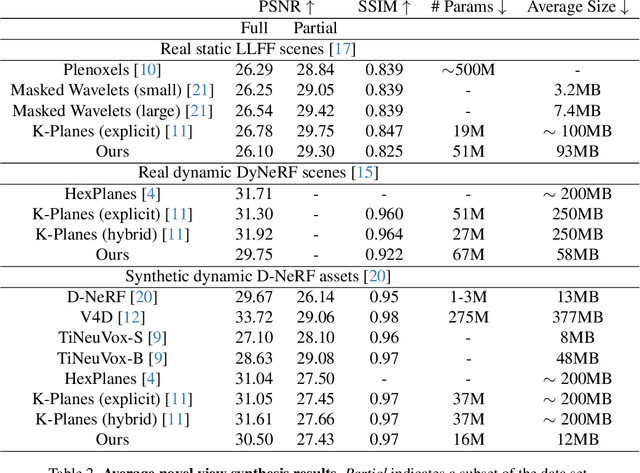
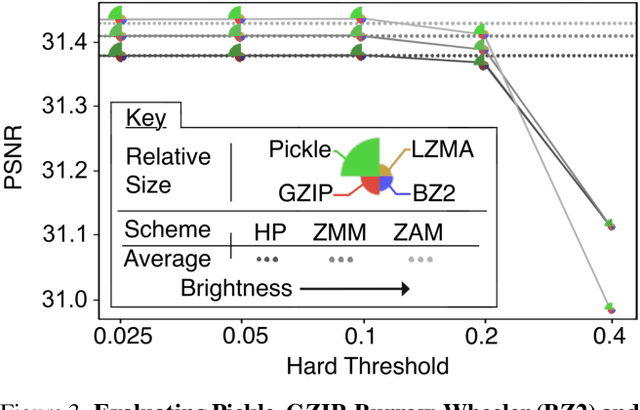
Dynamic Neural Radiance Fields (Dynamic NeRF) enhance NeRF technology to model moving scenes. However, they are resource intensive and challenging to compress. To address this issue, this paper presents WavePlanes, a fast and more compact explicit model. We propose a multi-scale space and space-time feature plane representation using N-level 2-D wavelet coefficients. The inverse discrete wavelet transform reconstructs N feature signals at varying detail, which are linearly decoded to approximate the color and density of volumes in a 4-D grid. Exploiting the sparsity of wavelet coefficients, we compress a Hash Map containing only non-zero coefficients and their locations on each plane. This results in a compressed model size of ~12 MB. Compared with state-of-the-art plane-based models, WavePlanes is up to 15x smaller, less computationally demanding and achieves comparable results in as little as one hour of training - without requiring custom CUDA code or high performance computing resources. Additionally, we propose new feature fusion schemes that work as well as previously proposed schemes while providing greater interpretability. Our code is available at: https://github.com/azzarelli/waveplanes/
Deep learning and traditional-based CAD schemes for the pulmonary embolism diagnosis: A survey
Dec 03, 2023Nowadays, pulmonary Computed Tomography Angiography (CTA) is the main tool for detecting Pulmonary Embolism (PE). However, manual interpretation of CTA volume requires a radiologist, which is time-consuming and error-prone due to the specific conditions of lung tissue, large volume of data, lack of experience, and eye fatigue. Therefore, Computer-Aided Design (CAD) systems are used as a second opinion for the diagnosis of PE. The purpose of this article is to review, evaluate, and compare the performance of deep learning and traditional-based CAD system for diagnosis PE and to help physicians and researchers in this field. In this study, all articles available in databases such as IEEE, ScienceDirect, Wiley, Springer, Nature, and Wolters Kluwer in the field of PE diagnosis were examined using traditional and deep learning methods. From 2002 to 2023, 23 papers were studied to extract the articles with the considered limitations. Each paper presents an automatic PE detection system that we evaluate using criteria such as sensitivity, False Positives (FP), and the number of datasets. This research work includes recent studies, state-of-the-art research works, and a more comprehensive overview compared to previously published review articles in this research area.
ViVid-1-to-3: Novel View Synthesis with Video Diffusion Models
Dec 03, 2023Generating novel views of an object from a single image is a challenging task. It requires an understanding of the underlying 3D structure of the object from an image and rendering high-quality, spatially consistent new views. While recent methods for view synthesis based on diffusion have shown great progress, achieving consistency among various view estimates and at the same time abiding by the desired camera pose remains a critical problem yet to be solved. In this work, we demonstrate a strikingly simple method, where we utilize a pre-trained video diffusion model to solve this problem. Our key idea is that synthesizing a novel view could be reformulated as synthesizing a video of a camera going around the object of interest -- a scanning video -- which then allows us to leverage the powerful priors that a video diffusion model would have learned. Thus, to perform novel-view synthesis, we create a smooth camera trajectory to the target view that we wish to render, and denoise using both a view-conditioned diffusion model and a video diffusion model. By doing so, we obtain a highly consistent novel view synthesis, outperforming the state of the art.
Learning Neural Traffic Rules
Dec 03, 2023Extensive research has been devoted to the field of multi-agent navigation. Recently, there has been remarkable progress attributed to the emergence of learning-based techniques with substantially elevated intelligence and realism. Nonetheless, prevailing learned models face limitations in terms of scalability and effectiveness, primarily due to their agent-centric nature, i.e., the learned neural policy is individually deployed on each agent. Inspired by the efficiency observed in real-world traffic networks, we present an environment-centric navigation policy. Our method learns a set of traffic rules to coordinate a vast group of unintelligent agents that possess only basic collision-avoidance capabilities. Our method segments the environment into distinct blocks and parameterizes the traffic rule using a Graph Recurrent Neural Network (GRNN) over the block network. Each GRNN node is trained to modulate the velocities of agents as they traverse through. Using either Imitation Learning (IL) or Reinforcement Learning (RL) schemes, we demonstrate the efficacy of our neural traffic rules in resolving agent congestion, closely resembling real-world traffic regulations. Our method handles up to $240$ agents at real-time and generalizes across diverse agent and environment configurations.
TIBET: Identifying and Evaluating Biases in Text-to-Image Generative Models
Dec 03, 2023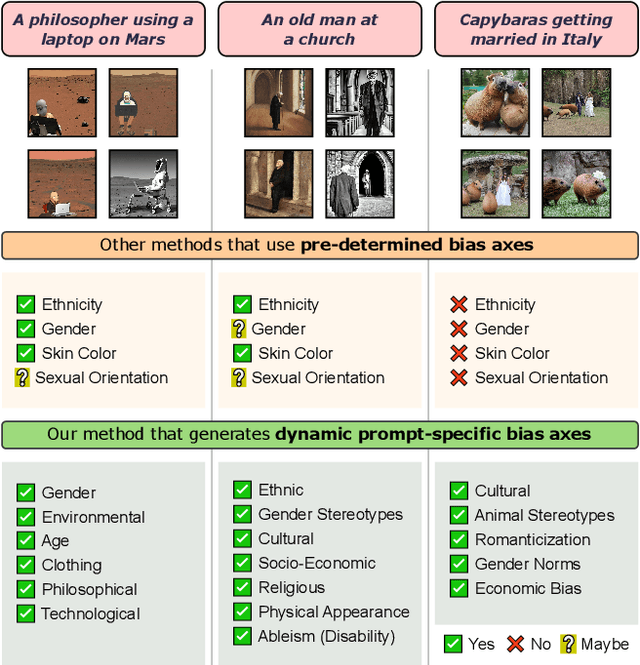
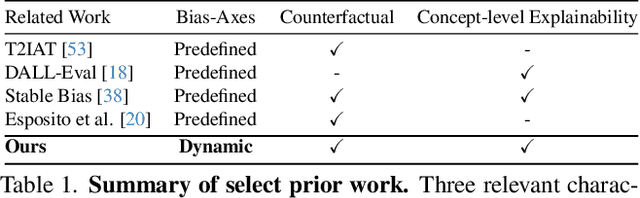
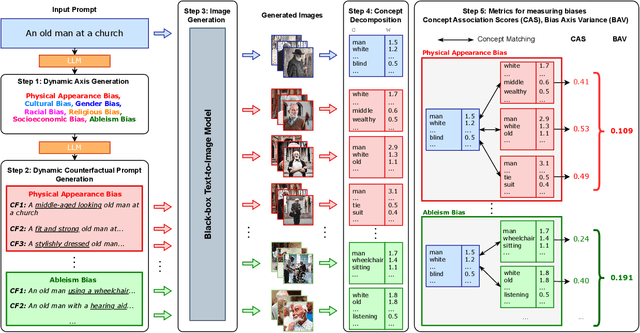
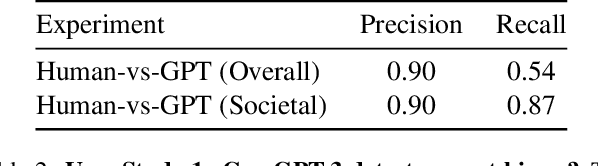
Text-to-Image (TTI) generative models have shown great progress in the past few years in terms of their ability to generate complex and high-quality imagery. At the same time, these models have been shown to suffer from harmful biases, including exaggerated societal biases (e.g., gender, ethnicity), as well as incidental correlations that limit such model's ability to generate more diverse imagery. In this paper, we propose a general approach to study and quantify a broad spectrum of biases, for any TTI model and for any prompt, using counterfactual reasoning. Unlike other works that evaluate generated images on a predefined set of bias axes, our approach automatically identifies potential biases that might be relevant to the given prompt, and measures those biases. In addition, our paper extends quantitative scores with post-hoc explanations in terms of semantic concepts in the images generated. We show that our method is uniquely capable of explaining complex multi-dimensional biases through semantic concepts, as well as the intersectionality between different biases for any given prompt. We perform extensive user studies to illustrate that the results of our method and analysis are consistent with human judgements.
Distributed Reinforcement Learning for Molecular Design: Antioxidant case
Dec 03, 2023Deep reinforcement learning has successfully been applied for molecular discovery as shown by the Molecule Deep Q-network (MolDQN) algorithm. This algorithm has challenges when applied to optimizing new molecules: training such a model is limited in terms of scalability to larger datasets and the trained model cannot be generalized to different molecules in the same dataset. In this paper, a distributed reinforcement learning algorithm for antioxidants, called DA-MolDQN is proposed to address these problems. State-of-the-art bond dissociation energy (BDE) and ionization potential (IP) predictors are integrated into DA-MolDQN, which are critical chemical properties while optimizing antioxidants. Training time is reduced by algorithmic improvements for molecular modifications. The algorithm is distributed, scalable for up to 512 molecules, and generalizes the model to a diverse set of molecules. The proposed models are trained with a proprietary antioxidant dataset. The results have been reproduced with both proprietary and public datasets. The proposed molecules have been validated with DFT simulations and a subset of them confirmed in public "unseen" datasets. In summary, DA-MolDQN is up to 100x faster than previous algorithms and can discover new optimized molecules from proprietary and public antioxidants.
Let the LLMs Talk: Simulating Human-to-Human Conversational QA via Zero-Shot LLM-to-LLM Interactions
Dec 05, 2023Conversational question-answering (CQA) systems aim to create interactive search systems that effectively retrieve information by interacting with users. To replicate human-to-human conversations, existing work uses human annotators to play the roles of the questioner (student) and the answerer (teacher). Despite its effectiveness, challenges exist as human annotation is time-consuming, inconsistent, and not scalable. To address this issue and investigate the applicability of large language models (LLMs) in CQA simulation, we propose a simulation framework that employs zero-shot learner LLMs for simulating teacher-student interactions. Our framework involves two LLMs interacting on a specific topic, with the first LLM acting as a student, generating questions to explore a given search topic. The second LLM plays the role of a teacher by answering questions and is equipped with additional information, including a text on the given topic. We implement both the student and teacher by zero-shot prompting the GPT-4 model. To assess the effectiveness of LLMs in simulating CQA interactions and understand the disparities between LLM- and human-generated conversations, we evaluate the simulated data from various perspectives. We begin by evaluating the teacher's performance through both automatic and human assessment. Next, we evaluate the performance of the student, analyzing and comparing the disparities between questions generated by the LLM and those generated by humans. Furthermore, we conduct extensive analyses to thoroughly examine the LLM performance by benchmarking state-of-the-art reading comprehension models on both datasets. Our results reveal that the teacher LLM generates lengthier answers that tend to be more accurate and complete. The student LLM generates more diverse questions, covering more aspects of a given topic.
Convergence Rates for Stochastic Approximation: Biased Noise with Unbounded Variance, and Applications
Dec 05, 2023The Stochastic Approximation (SA) algorithm introduced by Robbins and Monro in 1951 has been a standard method for solving equations of the form $\mathbf{f}({\boldsymbol {\theta}}) = \mathbf{0}$, when only noisy measurements of $\mathbf{f}(\cdot)$ are available. If $\mathbf{f}({\boldsymbol {\theta}}) = \nabla J({\boldsymbol {\theta}})$ for some function $J(\cdot)$, then SA can also be used to find a stationary point of $J(\cdot)$. In much of the literature, it is assumed that the error term ${\boldsymbol {xi}}_{t+1}$ has zero conditional mean, and that its conditional variance is bounded as a function of $t$ (though not necessarily with respect to ${\boldsymbol {\theta}}_t$). Also, for the most part, the emphasis has been on ``synchronous'' SA, whereby, at each time $t$, \textit{every} component of ${\boldsymbol {\theta}}_t$ is updated. Over the years, SA has been applied to a variety of areas, out of which two are the focus in this paper: Convex and nonconvex optimization, and Reinforcement Learning (RL). As it turns out, in these applications, the above-mentioned assumptions do not always hold. In zero-order methods, the error neither has zero mean nor bounded conditional variance. In the present paper, we extend SA theory to encompass errors with nonzero conditional mean and/or unbounded conditional variance, and also asynchronous SA. In addition, we derive estimates for the rate of convergence of the algorithm. Then we apply the new results to problems in nonconvex optimization, and to Markovian SA, a recently emerging area in RL. We prove that SA converges in these situations, and compute the ``optimal step size sequences'' to maximize the estimated rate of convergence.