 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Using a Large Language Model to generate a Design Structure Matrix
Dec 07, 2023
The Design Structure Matrix (DSM) is an established method used in dependency modelling, especially in the design of complex engineering systems. The generation of DSM is traditionally carried out through manual means and can involve interviewing experts to elicit critical system elements and the relationships between them. Such manual approaches can be time-consuming and costly. This paper presents a workflow that uses a Large Language Model (LLM) to support the generation of DSM and improve productivity. A prototype of the workflow was developed in this work and applied on a diesel engine DSM published previously. It was found that the prototype could reproduce 357 out of 462 DSM entries published (i.e. 77.3%), suggesting that the work can aid DSM generation. A no-code version of the prototype is made available online to support future research.
Deep Emotions Across Languages: A Novel Approach for Sentiment Propagation in Multilingual WordNets
Dec 07, 2023Sentiment analysis involves using WordNets enriched with emotional metadata, which are valuable resources. However, manual annotation is time-consuming and expensive, resulting in only a few WordNet Lexical Units being annotated. This paper introduces two new techniques for automatically propagating sentiment annotations from a partially annotated WordNet to its entirety and to a WordNet in a different language: Multilingual Structured Synset Embeddings (MSSE) and Cross-Lingual Deep Neural Sentiment Propagation (CLDNS). We evaluated the proposed MSSE+CLDNS method extensively using Princeton WordNet and Polish WordNet, which have many inter-lingual relations. Our results show that the MSSE+CLDNS method outperforms existing propagation methods, indicating its effectiveness in enriching WordNets with emotional metadata across multiple languages. This work provides a solid foundation for large-scale, multilingual sentiment analysis and is valuable for academic research and practical applications.
LiveTune: Dynamic Parameter Tuning for Training Deep Neural Networks
Nov 28, 2023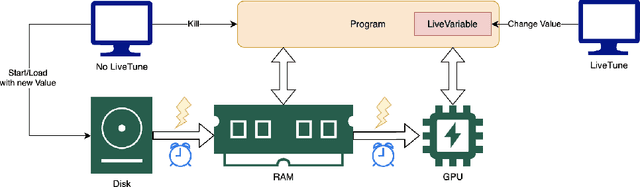
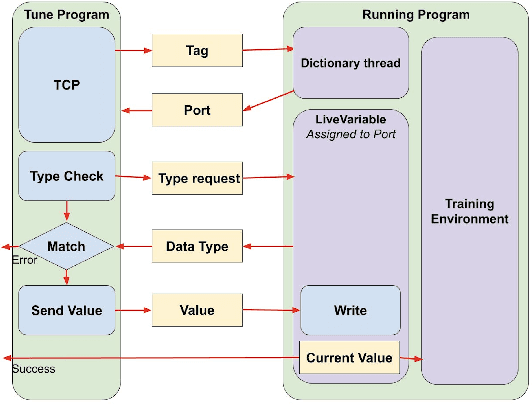
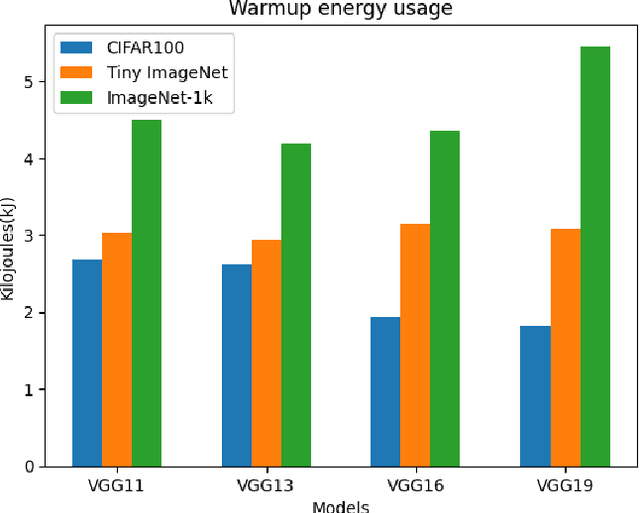
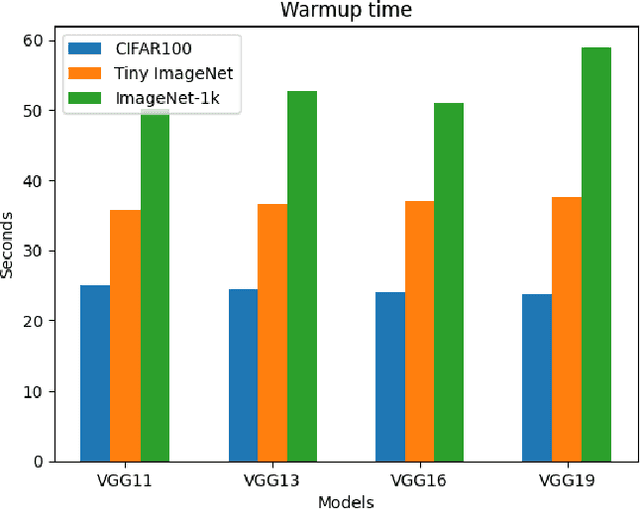
Traditional machine learning training is a static process that lacks real-time adaptability of hyperparameters. Popular tuning solutions during runtime involve checkpoints and schedulers. Adjusting hyper-parameters usually require the program to be restarted, wasting utilization and time, while placing unnecessary strain on memory and processors. We present LiveTune, a new framework allowing real-time parameter tuning during training through LiveVariables. Live Variables allow for a continuous training session by storing parameters on designated ports on the system, allowing them to be dynamically adjusted. Extensive evaluations of our framework show saving up to 60 seconds and 5.4 Kilojoules of energy per hyperparameter change.
Masked Space-Time Hash Encoding for Efficient Dynamic Scene Reconstruction
Oct 26, 2023In this paper, we propose the Masked Space-Time Hash encoding (MSTH), a novel method for efficiently reconstructing dynamic 3D scenes from multi-view or monocular videos. Based on the observation that dynamic scenes often contain substantial static areas that result in redundancy in storage and computations, MSTH represents a dynamic scene as a weighted combination of a 3D hash encoding and a 4D hash encoding. The weights for the two components are represented by a learnable mask which is guided by an uncertainty-based objective to reflect the spatial and temporal importance of each 3D position. With this design, our method can reduce the hash collision rate by avoiding redundant queries and modifications on static areas, making it feasible to represent a large number of space-time voxels by hash tables with small size.Besides, without the requirements to fit the large numbers of temporally redundant features independently, our method is easier to optimize and converge rapidly with only twenty minutes of training for a 300-frame dynamic scene.As a result, MSTH obtains consistently better results than previous methods with only 20 minutes of training time and 130 MB of memory storage. Code is available at https://github.com/masked-spacetime-hashing/msth
Relevance Feedback with Brain Signals
Dec 09, 2023The Relevance Feedback (RF) process relies on accurate and real-time relevance estimation of feedback documents to improve retrieval performance. Since collecting explicit relevance annotations imposes an extra burden on the user, extensive studies have explored using pseudo-relevance signals and implicit feedback signals as substitutes. However, such signals are indirect indicators of relevance and suffer from complex search scenarios where user interactions are absent or biased. Recently, the advances in portable and high-precision brain-computer interface (BCI) devices have shown the possibility to monitor user's brain activities during search process. Brain signals can directly reflect user's psychological responses to search results and thus it can act as additional and unbiased RF signals. To explore the effectiveness of brain signals in the context of RF, we propose a novel RF framework that combines BCI-based relevance feedback with pseudo-relevance signals and implicit signals to improve the performance of document re-ranking. The experimental results on the user study dataset show that incorporating brain signals leads to significant performance improvement in our RF framework. Besides, we observe that brain signals perform particularly well in several hard search scenarios, especially when implicit signals as feedback are missing or noisy. This reveals when and how to exploit brain signals in the context of RF.
FreeFlow: A Comprehensive Understanding on Diffusion Probabilistic Models via Optimal Transport
Dec 09, 2023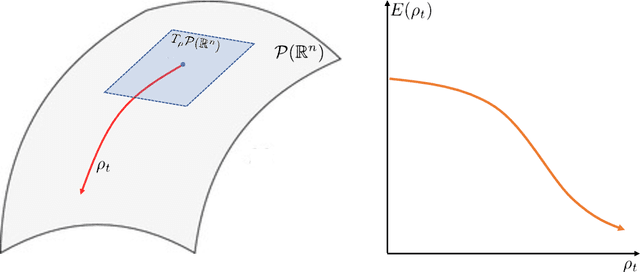
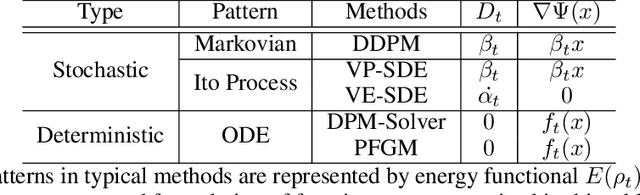
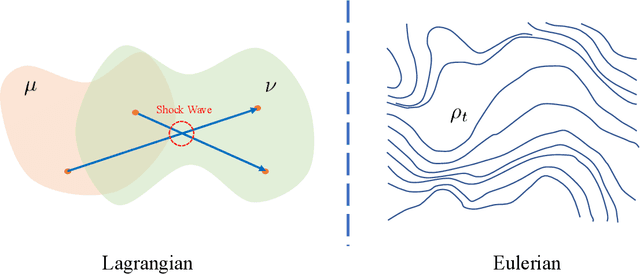
The blooming diffusion probabilistic models (DPMs) have garnered significant interest due to their impressive performance and the elegant inspiration they draw from physics. While earlier DPMs relied upon the Markovian assumption, recent methods based on differential equations have been rapidly applied to enhance the efficiency and capabilities of these models. However, a theoretical interpretation encapsulating these diverse algorithms is insufficient yet pressingly required to guide further development of DPMs. In response to this need, we present FreeFlow, a framework that provides a thorough explanation of the diffusion formula as time-dependent optimal transport, where the evolutionary pattern of probability density is given by the gradient flows of a functional defined in Wasserstein space. Crucially, our framework necessitates a unified description that not only clarifies the subtle mechanism of DPMs but also indicates the roots of some defects through creative involvement of Lagrangian and Eulerian views to understand the evolution of probability flow. We particularly demonstrate that the core equation of FreeFlow condenses all stochastic and deterministic DPMs into a single case, showcasing the expansibility of our method. Furthermore, the Riemannian geometry employed in our work has the potential to bridge broader subjects in mathematics, which enable the involvement of more profound tools for the establishment of more outstanding and generalized models in the future.
Kraken: enabling joint trajectory prediction by utilizing Mode Transformer and Greedy Mode Processing
Dec 08, 2023Accurate and reliable motion prediction is essential for safe urban autonomy. The most prominent motion prediction approaches are based on modeling the distribution of possible future trajectories of each actor in autonomous system's vicinity. These "independent" marginal predictions might be accurate enough to properly describe casual driving situations where the prediction target is not likely to interact with other actors. They are, however, inadequate for modeling interactive situations where the actors' future trajectories are likely to intersect. To mitigate this issue we propose Kraken -- a real-time trajectory prediction model capable of approximating pairwise interactions between the actors as well as producing accurate marginal predictions. Kraken relies on a simple Greedy Mode Processing technique allowing it to convert a factorized prediction for a pair of agents into a physically-plausible joint prediction. It also utilizes the Mode Transformer module to increase the diversity of predicted trajectories and make the joint prediction more informative. We evaluate Kraken on Waymo Motion Prediction challenge where it held the first place in the Interaction leaderboard and the second place in the Motion leaderboard in October 2021.
Attention-Based Ensemble Pooling for Time Series Forecasting
Oct 24, 2023A common technique to reduce model bias in time-series forecasting is to use an ensemble of predictive models and pool their output into an ensemble forecast. In cases where each predictive model has different biases, however, it is not always clear exactly how each model forecast should be weighed during this pooling. We propose a method for pooling that performs a weighted average over candidate model forecasts, where the weights are learned by an attention-based ensemble pooling model. We test this method on two time-series forecasting problems: multi-step forecasting of the dynamics of the non-stationary Lorenz `63 equation, and one-step forecasting of the weekly incident deaths due to COVID-19. We find that while our model achieves excellent valid times when forecasting the non-stationary Lorenz `63 equation, it does not consistently perform better than the existing ensemble pooling when forecasting COVID-19 weekly incident deaths.
A Novel Representation to Improve Team Problem Solving in Real-Time
Oct 30, 2023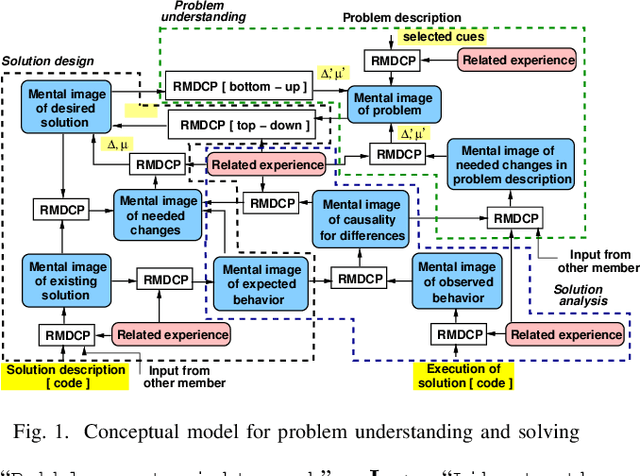
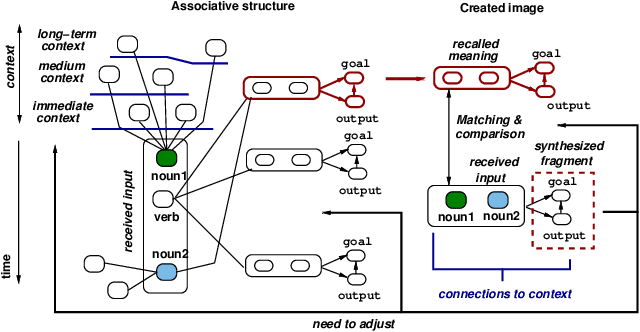
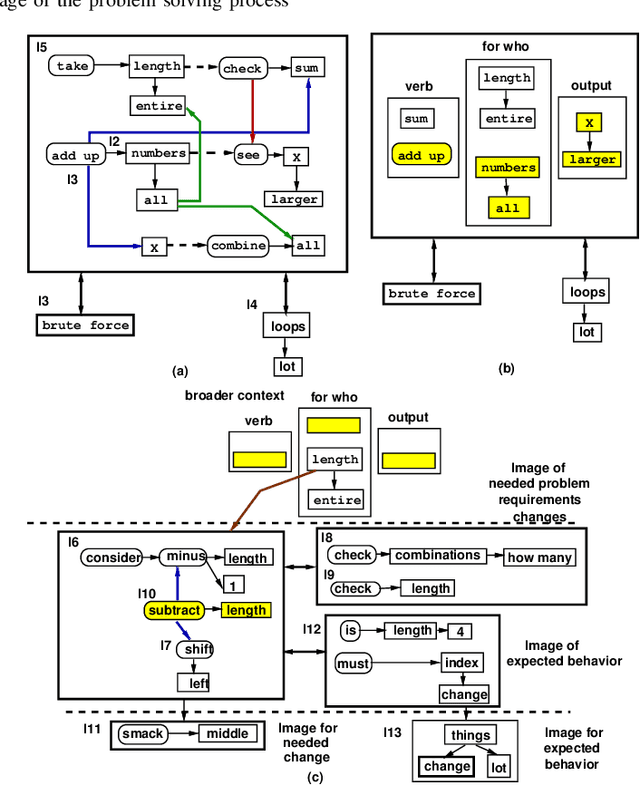
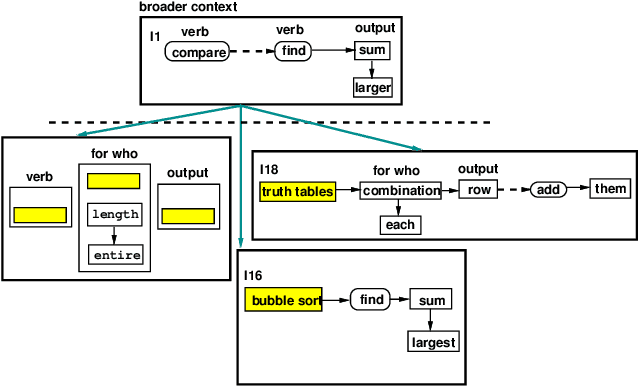
This paper proposes a novel representation to support computing metrics that help understanding and improving in real-time a team's behavior during problem solving in real-life. Even though teams are important in modern activities, there is little computing aid to improve their activity. The representation captures the different mental images developed, enhanced, and utilized during solving. A case study illustrates the representation.
A Structural-Clustering Based Active Learning for Graph Neural Networks
Dec 07, 2023In active learning for graph-structured data, Graph Neural Networks (GNNs) have shown effectiveness. However, a common challenge in these applications is the underutilization of crucial structural information. To address this problem, we propose the Structural-Clustering PageRank method for improved Active learning (SPA) specifically designed for graph-structured data. SPA integrates community detection using the SCAN algorithm with the PageRank scoring method for efficient and informative sample selection. SPA prioritizes nodes that are not only informative but also central in structure. Through extensive experiments, SPA demonstrates higher accuracy and macro-F1 score over existing methods across different annotation budgets and achieves significant reductions in query time. In addition, the proposed method only adds two hyperparameters, $\epsilon$ and $\mu$ in the algorithm to finely tune the balance between structural learning and node selection. This simplicity is a key advantage in active learning scenarios, where extensive hyperparameter tuning is often impractical.