 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Spectral Methods: Self-supervised learning in the spectral domain
Dec 08, 2023
We present Neural Spectral Methods, a technique to solve parametric Partial Differential Equations (PDEs), grounded in classical spectral methods. Our method uses orthogonal bases to learn PDE solutions as mappings between spectral coefficients. In contrast to current machine learning approaches which enforce PDE constraints by minimizing the numerical quadrature of the residuals in the spatiotemporal domain, we leverage Parseval's identity and introduce a new training strategy through a \textit{spectral loss}. Our spectral loss enables more efficient differentiation through the neural network, and substantially reduces training complexity. At inference time, the computational cost of our method remains constant, regardless of the spatiotemporal resolution of the domain. Our experimental results demonstrate that our method significantly outperforms previous machine learning approaches in terms of speed and accuracy by one to two orders of magnitude on multiple different problems. When compared to numerical solvers of the same accuracy, our method demonstrates a $10\times$ increase in performance speed.
Continual learning for surface defect segmentation by subnetwork creation and selection
Dec 08, 2023We introduce a new continual (or lifelong) learning algorithm called LDA-CP&S that performs segmentation tasks without undergoing catastrophic forgetting. The method is applied to two different surface defect segmentation problems that are learned incrementally, i.e. providing data about one type of defect at a time, while still being capable of predicting every defect that was seen previously. Our method creates a defect-related subnetwork for each defect type via iterative pruning and trains a classifier based on linear discriminant analysis (LDA). At the inference stage, we first predict the defect type with LDA and then predict the surface defects using the selected subnetwork. We compare our method with other continual learning methods showing a significant improvement -- mean Intersection over Union better by a factor of two when compared to existing methods on both datasets. Importantly, our approach shows comparable results with joint training when all the training data (all defects) are seen simultaneously
DARNet: Bridging Domain Gaps in Cross-Domain Few-Shot Segmentation with Dynamic Adaptation
Dec 08, 2023
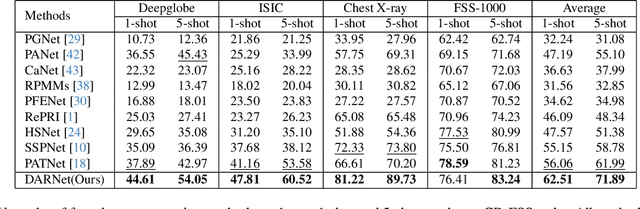
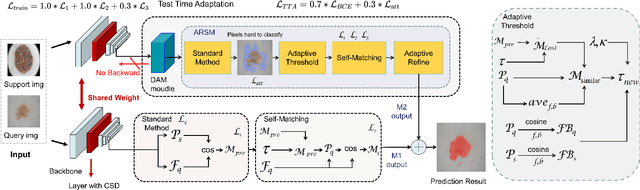
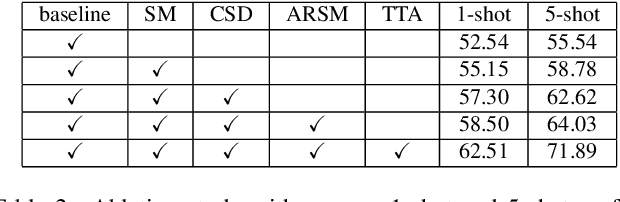
Few-shot segmentation (FSS) aims to segment novel classes in a query image by using only a small number of supporting images from base classes. However, in cross-domain few-shot segmentation (CD-FSS), leveraging features from label-rich domains for resource-constrained domains poses challenges due to domain discrepancies. This work presents a Dynamically Adaptive Refine (DARNet) method that aims to balance generalization and specificity for CD-FSS. Our method includes the Channel Statistics Disruption (CSD) strategy, which perturbs feature channel statistics in the source domain, bolstering generalization to unknown target domains. Moreover, recognizing the variability across target domains, an Adaptive Refine Self-Matching (ARSM) method is also proposed to adjust the matching threshold and dynamically refine the prediction result with the self-matching method, enhancing accuracy. We also present a Test-Time Adaptation (TTA) method to refine the model's adaptability to diverse feature distributions. Our approach demonstrates superior performance against state-of-the-art methods in CD-FSS tasks.
A Negative Result on Gradient Matching for Selective Backprop
Dec 08, 2023With increasing scale in model and dataset size, the training of deep neural networks becomes a massive computational burden. One approach to speed up the training process is Selective Backprop. For this approach, we perform a forward pass to obtain a loss value for each data point in a minibatch. The backward pass is then restricted to a subset of that minibatch, prioritizing high-loss examples. We build on this approach, but seek to improve the subset selection mechanism by choosing the (weighted) subset which best matches the mean gradient over the entire minibatch. We use the gradients w.r.t. the model's last layer as a cheap proxy, resulting in virtually no overhead in addition to the forward pass. At the same time, for our experiments we add a simple random selection baseline which has been absent from prior work. Surprisingly, we find that both the loss-based as well as the gradient-matching strategy fail to consistently outperform the random baseline.
Deep learning acceleration of iterative model-based light fluence correction for photoacoustic tomography
Dec 08, 2023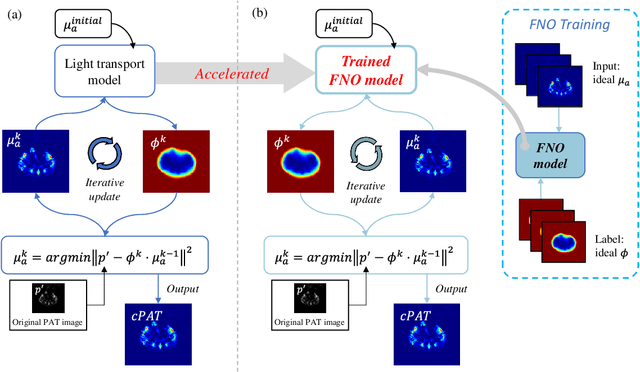

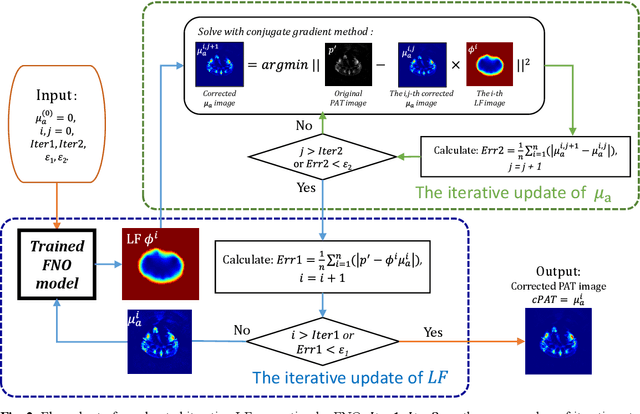
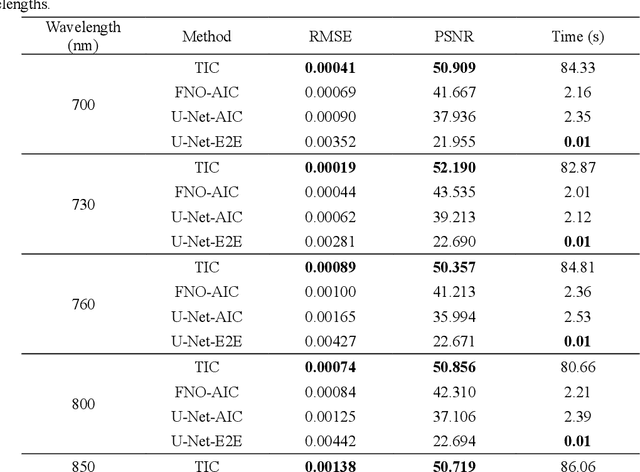
Photoacoustic tomography (PAT) is a promising imaging technique that can visualize the distribution of chromophores within biological tissue. However, the accuracy of PAT imaging is compromised by light fluence (LF), which hinders the quantification of light absorbers. Currently, model-based iterative methods are used for LF correction, but they require significant computational resources due to repeated LF estimation based on differential light transport models. To improve LF correction efficiency, we propose to use Fourier neural operator (FNO), a neural network specially designed for solving differential equations, to learn the forward projection of light transport in PAT. Trained using paired finite-element-based LF simulation data, our FNO model replaces the traditional computational heavy LF estimator during iterative correction, such that the correction procedure is significantly accelerated. Simulation and experimental results demonstrate that our method achieves comparable LF correction quality to traditional iterative methods while reducing the correction time by over 30 times.
Skilful Precipitation Nowcasting Using NowcastNet
Dec 08, 2023Designing early warning system for precipitation requires accurate short-term forecasting system. Climate change has led to an increase in frequency of extreme weather events, and hence such systems can prevent disasters and loss of life. Managing such events remain a challenge for both public and private institutions. Precipitation nowcasting can help relevant institutions to better prepare for such events as they impact agriculture, transport, public health and safety, etc. Physics-based numerical weather prediction (NWP) is unable to perform well for nowcasting because of large computational turn-around time. Deep-learning based models on the other hand are able to give predictions within seconds. We use recently proposed NowcastNet, a physics-conditioned deep generative network, to forecast precipitation for different regions of Europe using satellite images. Both spatial and temporal transfer learning is done by forecasting for the unseen regions and year. Model makes realistic predictions and is able to outperform baseline for such a prediction task.
Stellar Spectra Fitting with Amortized Neural Posterior Estimation and nbi
Dec 09, 2023Modern surveys often deliver hundreds of thousands of stellar spectra at once, which are fit to spectral models to derive stellar parameters/labels. Therefore, the technique of Amortized Neural Posterior Estimation (ANPE) stands out as a suitable approach, which enables the inference of large number of targets as sub-linear/constant computational costs. Leveraging our new nbi software package, we train an ANPE model for the APOGEE survey and demonstrate its efficacy on both mock and real APOGEE stellar spectra. Unique to the nbi package is its out-of-the-box functionality on astronomical inverse problems with sequential data. As such, we have been able to acquire the trained model with minimal effort. We introduce an effective approach to handling the measurement noise properties inherent in spectral data, which utilizes the actual uncertainties in the observed data. This allows training data to resemble observed data, an aspect that is crucial for ANPE applications. Given the association of spectral data properties with the observing instrument, we discuss the utility of an ANPE "model zoo," where models are trained for specific instruments and distributed under the nbi framework to facilitate real-time stellar parameter inference.
Lazy-k: Decoding for Constrained Token Classification
Dec 06, 2023We explore the possibility of improving probabilistic models in structured prediction. Specifically, we combine the models with constrained decoding approaches in the context of token classification for information extraction. The decoding methods search for constraint-satisfying label-assignments while maximizing the total probability. To do this, we evaluate several existing approaches, as well as propose a novel decoding method called Lazy-$k$. Our findings demonstrate that constrained decoding approaches can significantly improve the models' performances, especially when using smaller models. The Lazy-$k$ approach allows for more flexibility between decoding time and accuracy. The code for using Lazy-$k$ decoding can be found here: https://github.com/ArthurDevNL/lazyk.
Uncertainty Propagation on Unimodular Matrix Lie Groups
Dec 06, 2023This paper addresses uncertainty propagation on unimodular matrix Lie groups that have a surjective exponential map. We derive the exact formula for the propagation of mean and covariance in a continuous-time setting from the governing Fokker-Planck equation. Two approximate propagation methods are discussed based on the exact formula. One uses numerical quadrature and another utilizes the expansion of moments. A closed-form second-order propagation formula is derived. We apply the general theory to the joint attitude and angular momentum uncertainty propagation problem and numerical experiments demonstrate two approximation methods. These results show that our new methods have high accuracy while being computationally efficient.
Graph Convolutions Enrich the Self-Attention in Transformers!
Dec 07, 2023Transformers, renowned for their self-attention mechanism, have achieved state-of-the-art performance across various tasks in natural language processing, computer vision, time-series modeling, etc. However, one of the challenges with deep Transformer models is the oversmoothing problem, where representations across layers converge to indistinguishable values, leading to significant performance degradation. We interpret the original self-attention as a simple graph filter and redesign it from a graph signal processing (GSP) perspective. We propose graph-filter-based self-attention (GFSA) to learn a general yet effective one, whose complexity, however, is slightly larger than that of the original self-attention mechanism. We demonstrate that GFSA improves the performance of Transformers in various fields, including computer vision, natural language processing, graph pattern classification, speech recognition, and code classification.