 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Effectively Fine-tune to Improve Large Multimodal Models for Radiology Report Generation
Dec 03, 2023
Writing radiology reports from medical images requires a high level of domain expertise. It is time-consuming even for trained radiologists and can be error-prone for inexperienced radiologists. It would be appealing to automate this task by leveraging generative AI, which has shown drastic progress in vision and language understanding. In particular, Large Language Models (LLM) have demonstrated impressive capabilities recently and continued to set new state-of-the-art performance on almost all natural language tasks. While many have proposed architectures to combine vision models with LLMs for multimodal tasks, few have explored practical fine-tuning strategies. In this work, we proposed a simple yet effective two-stage fine-tuning protocol to align visual features to LLM's text embedding space as soft visual prompts. Our framework with OpenLLaMA-7B achieved state-of-the-art level performance without domain-specific pretraining. Moreover, we provide detailed analyses of soft visual prompts and attention mechanisms, shedding light on future research directions.
SparsePoser: Real-time Full-body Motion Reconstruction from Sparse Data
Nov 03, 2023
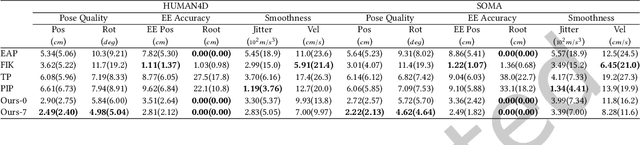
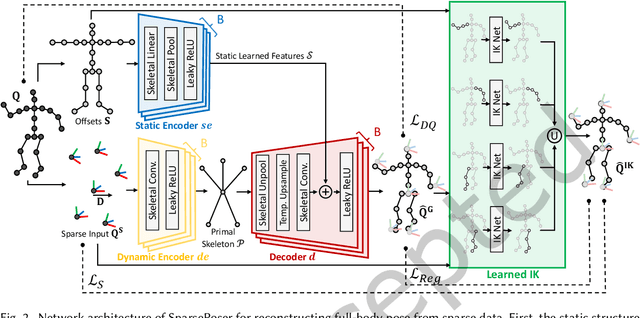
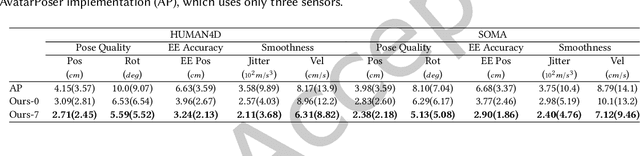
Accurate and reliable human motion reconstruction is crucial for creating natural interactions of full-body avatars in Virtual Reality (VR) and entertainment applications. As the Metaverse and social applications gain popularity, users are seeking cost-effective solutions to create full-body animations that are comparable in quality to those produced by commercial motion capture systems. In order to provide affordable solutions, though, it is important to minimize the number of sensors attached to the subject's body. Unfortunately, reconstructing the full-body pose from sparse data is a heavily under-determined problem. Some studies that use IMU sensors face challenges in reconstructing the pose due to positional drift and ambiguity of the poses. In recent years, some mainstream VR systems have released 6-degree-of-freedom (6-DoF) tracking devices providing positional and rotational information. Nevertheless, most solutions for reconstructing full-body poses rely on traditional inverse kinematics (IK) solutions, which often produce non-continuous and unnatural poses. In this article, we introduce SparsePoser, a novel deep learning-based solution for reconstructing a full-body pose from a reduced set of six tracking devices. Our system incorporates a convolutional-based autoencoder that synthesizes high-quality continuous human poses by learning the human motion manifold from motion capture data. Then, we employ a learned IK component, made of multiple lightweight feed-forward neural networks, to adjust the hands and feet toward the corresponding trackers. We extensively evaluate our method on publicly available motion capture datasets and with real-time live demos. We show that our method outperforms state-of-the-art techniques using IMU sensors or 6-DoF tracking devices, and can be used for users with different body dimensions and proportions.
A Multi-Scale Decomposition MLP-Mixer for Time Series Analysis
Oct 18, 2023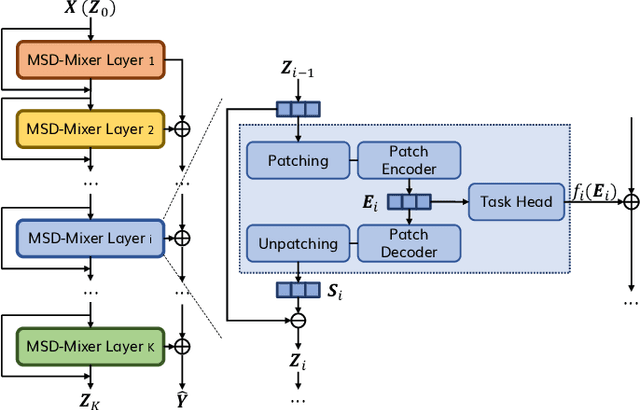
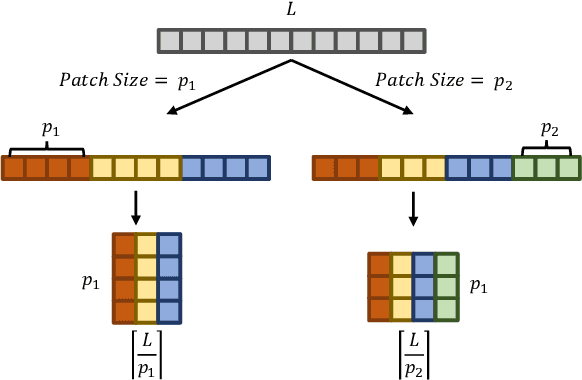
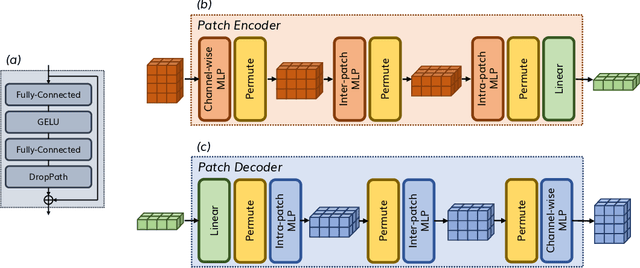
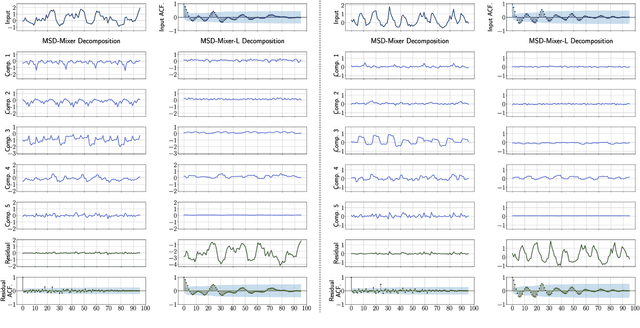
Time series data, often characterized by unique composition and complex multi-scale temporal variations, requires special consideration of decomposition and multi-scale modeling in its analysis. Existing deep learning methods on this best fit to only univariate time series, and have not sufficiently accounted for sub-series level modeling and decomposition completeness. To address this, we propose MSD-Mixer, a Multi-Scale Decomposition MLP-Mixer which learns to explicitly decompose the input time series into different components, and represents the components in different layers. To handle multi-scale temporal patterns and inter-channel dependencies, we propose a novel temporal patching approach to model the time series as multi-scale sub-series, i.e., patches, and employ MLPs to mix intra- and inter-patch variations and channel-wise correlations. In addition, we propose a loss function to constrain both the magnitude and autocorrelation of the decomposition residual for decomposition completeness. Through extensive experiments on various real-world datasets for five common time series analysis tasks (long- and short-term forecasting, imputation, anomaly detection, and classification), we demonstrate that MSD-Mixer consistently achieves significantly better performance in comparison with other state-of-the-art task-general and task-specific approaches.
MMM: Generative Masked Motion Model
Dec 06, 2023Recent advances in text-to-motion generation using diffusion and autoregressive models have shown promising results. However, these models often suffer from a trade-off between real-time performance, high fidelity, and motion editability. To address this gap, we introduce MMM, a novel yet simple motion generation paradigm based on Masked Motion Model. MMM consists of two key components: (1) a motion tokenizer that transforms 3D human motion into a sequence of discrete tokens in latent space, and (2) a conditional masked motion transformer that learns to predict randomly masked motion tokens, conditioned on the pre-computed text tokens. By attending to motion and text tokens in all directions, MMM explicitly captures inherent dependency among motion tokens and semantic mapping between motion and text tokens. During inference, this allows parallel and iterative decoding of multiple motion tokens that are highly consistent with fine-grained text descriptions, therefore simultaneously achieving high-fidelity and high-speed motion generation. In addition, MMM has innate motion editability. By simply placing mask tokens in the place that needs editing, MMM automatically fills the gaps while guaranteeing smooth transitions between editing and non-editing parts. Extensive experiments on the HumanML3D and KIT-ML datasets demonstrate that MMM surpasses current leading methods in generating high-quality motion (evidenced by superior FID scores of 0.08 and 0.429), while offering advanced editing features such as body-part modification, motion in-betweening, and the synthesis of long motion sequences. In addition, MMM is two orders of magnitude faster on a single mid-range GPU than editable motion diffusion models. Our project page is available at \url{https://exitudio.github.io/MMM-page}.
Manipulating the Label Space for In-Context Classification
Dec 06, 2023After pre-training by generating the next word conditional on previous words, the Language Model (LM) acquires the ability of In-Context Learning (ICL) that can learn a new task conditional on the context of the given in-context examples (ICEs). Similarly, visually-conditioned Language Modelling is also used to train Vision-Language Models (VLMs) with ICL ability. However, such VLMs typically exhibit weaker classification abilities compared to contrastive learning-based models like CLIP, since the Language Modelling objective does not directly contrast whether an object is paired with a text. To improve the ICL of classification, using more ICEs to provide more knowledge is a straightforward way. However, this may largely increase the selection time, and more importantly, the inclusion of additional in-context images tends to extend the length of the in-context sequence beyond the processing capacity of a VLM. To alleviate these limitations, we propose to manipulate the label space of each ICE to increase its knowledge density, allowing for fewer ICEs to convey as much information as a larger set would. Specifically, we propose two strategies which are Label Distribution Enhancement and Visual Descriptions Enhancement to improve In-context classification performance on diverse datasets, including the classic ImageNet and more fine-grained datasets like CUB-200. Specifically, using our approach on ImageNet, we increase accuracy from 74.70\% in a 4-shot setting to 76.21\% with just 2 shots. surpassing CLIP by 0.67\%. On CUB-200, our method raises 1-shot accuracy from 48.86\% to 69.05\%, 12.15\% higher than CLIP. The code is given in https://anonymous.4open.science/r/MLS_ICC.
Fine-tuning pre-trained extractive QA models for clinical document parsing
Dec 04, 2023Electronic health records (EHRs) contain a vast amount of high-dimensional multi-modal data that can accurately represent a patient's medical history. Unfortunately, most of this data is either unstructured or semi-structured, rendering it unsuitable for real-time and retrospective analyses. A remote patient monitoring (RPM) program for Heart Failure (HF) patients needs to have access to clinical markers like EF (Ejection Fraction) or LVEF (Left Ventricular Ejection Fraction) in order to ascertain eligibility and appropriateness for the program. This paper explains a system that can parse echocardiogram reports and verify EF values. This system helps identify eligible HF patients who can be enrolled in such a program. At the heart of this system is a pre-trained extractive QA transformer model that is fine-tuned on custom-labeled data. The methods used to prepare such a model for deployment are illustrated by running experiments on a public clinical dataset like MIMIC-IV-Note. The pipeline can be used to generalize solutions to similar problems in a low-resource setting. We found that the system saved over 1500 hours for our clinicians over 12 months by automating the task at scale.
Fully Spiking Denoising Diffusion Implicit Models
Dec 04, 2023Spiking neural networks (SNNs) have garnered considerable attention owing to their ability to run on neuromorphic devices with super-high speeds and remarkable energy efficiencies. SNNs can be used in conventional neural network-based time- and energy-consuming applications. However, research on generative models within SNNs remains limited, despite their advantages. In particular, diffusion models are a powerful class of generative models, whose image generation quality surpass that of the other generative models, such as GANs. However, diffusion models are characterized by high computational costs and long inference times owing to their iterative denoising feature. Therefore, we propose a novel approach fully spiking denoising diffusion implicit model (FSDDIM) to construct a diffusion model within SNNs and leverage the high speed and low energy consumption features of SNNs via synaptic current learning (SCL). SCL fills the gap in that diffusion models use a neural network to estimate real-valued parameters of a predefined probabilistic distribution, whereas SNNs output binary spike trains. The SCL enables us to complete the entire generative process of diffusion models exclusively using SNNs. We demonstrate that the proposed method outperforms the state-of-the-art fully spiking generative model.
GenEM: Physics-Informed Generative Cryo-Electron Microscopy
Dec 04, 2023In the past decade, deep conditional generative models have revolutionized the generation of realistic images, extending their application from entertainment to scientific domains. Single-particle cryo-electron microscopy (cryo-EM) is crucial in resolving near-atomic resolution 3D structures of proteins, such as the SARS-COV-2 spike protein. To achieve high-resolution reconstruction, AI models for particle picking and pose estimation have been adopted. However, their performance is still limited as they lack high-quality annotated datasets. To address this, we introduce physics-informed generative cryo-electron microscopy (GenEM), which for the first time integrates physical-based cryo-EM simulation with a generative unpaired noise translation to generate physically correct synthetic cryo-EM datasets with realistic noises. Initially, GenEM simulates the cryo-EM imaging process based on a virtual specimen. To generate realistic noises, we leverage an unpaired noise translation via contrastive learning with a novel mask-guided sampling scheme. Extensive experiments show that GenEM is capable of generating realistic cryo-EM images. The generated dataset can further enhance particle picking and pose estimation models, eventually improving the reconstruction resolution. We will release our code and annotated synthetic datasets.
On Tuning Neural ODE for Stability, Consistency and Faster Convergence
Dec 04, 2023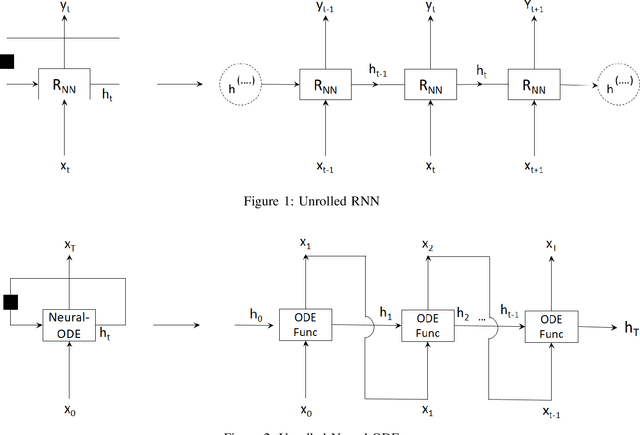
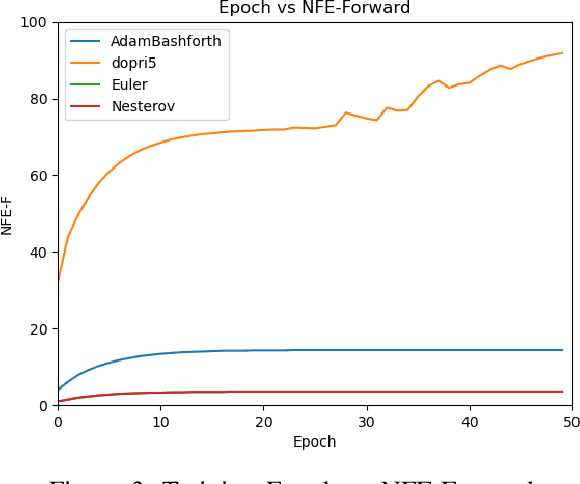
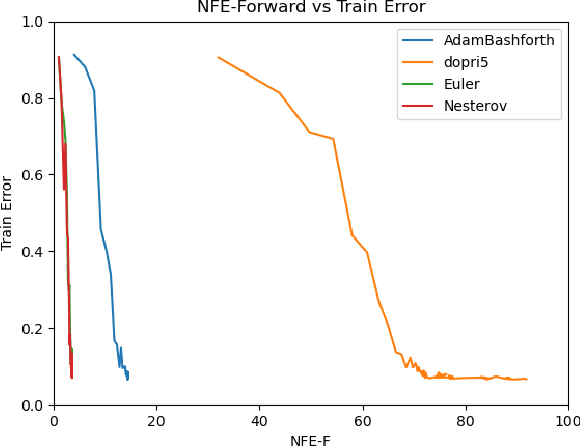
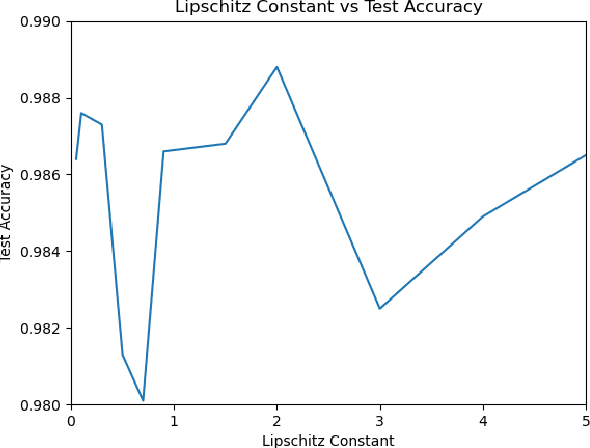
Neural-ODE parameterize a differential equation using continuous depth neural network and solve it using numerical ODE-integrator. These models offer a constant memory cost compared to models with discrete sequence of hidden layers in which memory cost increases linearly with the number of layers. In addition to memory efficiency, other benefits of neural-ode include adaptability of evaluation approach to input, and flexibility to choose numerical precision or fast training. However, despite having all these benefits, it still has some limitations. We identify the ODE-integrator (also called ODE-solver) as the weakest link in the chain as it may have stability, consistency and convergence (CCS) issues and may suffer from slower convergence or may not converge at all. We propose a first-order Nesterov's accelerated gradient (NAG) based ODE-solver which is proven to be tuned vis-a-vis CCS conditions. We empirically demonstrate the efficacy of our approach by training faster, while achieving better or comparable performance against neural-ode employing other fixed-step explicit ODE-solvers as well discrete depth models such as ResNet in three different tasks including supervised classification, density estimation, and time-series modelling.
Accelerated Parallel Magnetic Resonance Imaging with Compressed Sensing using Structured Sparsity
Dec 04, 2023Compressed sensing is an imaging paradigm that allows one to invert an underdetermined linear system by imposing the a priori knowledge that the sought after solution is sparse (i.e., mostly zeros). Previous works have shown that if one also knows something about the sparsity pattern (the locations where non-zero entries exist), one can take advantage of this structure to improve the quality of the result. A significant application of compressed sensing is magnetic resonance imaging (MRI), where samples are acquired in the Fourier domain. Compressed sensing allows one to reconstruct a high-quality image with fewer samples which can be collected with a faster scan. This increases the robustness of MRI to patient motion since less motion is possible during the shorter scan. Parallel imaging, where multiple coils are used to gather data, is another an more ubiquitously used method for accelerating MRI. Existing combinations of these acceleration methods, such as Sparse SENSE, yield high quality images with an even shorter scan time than either technique alone. In this work, we show how to modify Sparse SENSE with structured sparsity to reconstruct a high quality image with even fewer samples.