 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Bimanual Teleoperation Framework for Light Duty Underwater Vehicle-Manipulator Systems
Apr 04, 2024
In an effort to lower the barrier to entry in underwater manipulation, this paper presents an open-source, user-friendly framework for bimanual teleoperation of a light-duty underwater vehicle-manipulator system (UVMS). This framework allows for the control of the vehicle along with two manipulators and their end-effectors using two low-cost haptic devices. The UVMS kinematics are derived in order to create an independent resolved motion rate controller for each manipulator, which optimally controls the joint positions to achieve a desired end-effector pose. This desired pose is computed in real-time using a teleoperation controller developed to process the dual haptic device input from the user. A physics-based simulation environment is used to implement this framework for two example tasks as well as provide data for error analysis of user commands. The first task illustrates the functionality of the framework through motion control of the vehicle and manipulators using only the haptic devices. The second task is to grasp an object using both manipulators simultaneously, demonstrating precision and coordination using the framework. The framework code is available at https://github.com/stevens-armlab/uvms_bimanual_sim.
M3TCM: Multi-modal Multi-task Context Model for Utterance Classification in Motivational Interviews
Apr 04, 2024Accurate utterance classification in motivational interviews is crucial to automatically understand the quality and dynamics of client-therapist interaction, and it can serve as a key input for systems mediating such interactions. Motivational interviews exhibit three important characteristics. First, there are two distinct roles, namely client and therapist. Second, they are often highly emotionally charged, which can be expressed both in text and in prosody. Finally, context is of central importance to classify any given utterance. Previous works did not adequately incorporate all of these characteristics into utterance classification approaches for mental health dialogues. In contrast, we present M3TCM, a Multi-modal, Multi-task Context Model for utterance classification. Our approach for the first time employs multi-task learning to effectively model both joint and individual components of therapist and client behaviour. Furthermore, M3TCM integrates information from the text and speech modality as well as the conversation context. With our novel approach, we outperform the state of the art for utterance classification on the recently introduced AnnoMI dataset with a relative improvement of 20% for the client- and by 15% for therapist utterance classification. In extensive ablation studies, we quantify the improvement resulting from each contribution.
Improvement of Performance in Freezing of Gait detection in Parkinsons Disease using Transformer networks and a single waist worn triaxial accelerometer
Apr 04, 2024Freezing of gait (FOG) is one of the most incapacitating symptoms in Parkinsons disease, affecting more than 50 percent of patients in advanced stages of the disease. The presence of FOG may lead to falls and a loss of independence with a consequent reduction in the quality of life. Wearable technology and artificial intelligence have been used for automatic FOG detection to optimize monitoring. However, differences between laboratory and daily-life conditions present challenges for the implementation of reliable detection systems. Consequently, improvement of FOG detection methods remains important to provide accurate monitoring mechanisms intended for free-living and real-time use. This paper presents advances in automatic FOG detection using a single body-worn triaxial accelerometer and a novel classification algorithm based on Transformers and convolutional networks. This study was performed with data from 21 patients who manifested FOG episodes while performing activities of daily living in a home setting. Results indicate that the proposed FOG-Transformer can bring a significant improvement in FOG detection using leave-one-subject-out cross-validation (LOSO CV). These results bring opportunities for the implementation of accurate monitoring systems for use in ambulatory or home settings.
On Extending the Automatic Test Markup Language (ATML) for Machine Learning
Apr 04, 2024This paper addresses the urgent need for messaging standards in the operational test and evaluation (T&E) of machine learning (ML) applications, particularly in edge ML applications embedded in systems like robots, satellites, and unmanned vehicles. It examines the suitability of the IEEE Standard 1671 (IEEE Std 1671), known as the Automatic Test Markup Language (ATML), an XML-based standard originally developed for electronic systems, for ML application testing. The paper explores extending IEEE Std 1671 to encompass the unique challenges of ML applications, including the use of datasets and dependencies on software. Through modeling various tests such as adversarial robustness and drift detection, this paper offers a framework adaptable to specific applications, suggesting that minor modifications to ATML might suffice to address the novelties of ML. This paper differentiates ATML's focus on testing from other ML standards like Predictive Model Markup Language (PMML) or Open Neural Network Exchange (ONNX), which concentrate on ML model specification. We conclude that ATML is a promising tool for effective, near real-time operational T&E of ML applications, an essential aspect of AI lifecycle management, safety, and governance.
Robot Safety Monitoring using Programmable Light Curtains
Apr 04, 2024As factories continue to evolve into collaborative spaces with multiple robots working together with human supervisors in the loop, ensuring safety for all actors involved becomes critical. Currently, laser-based light curtain sensors are widely used in factories for safety monitoring. While these conventional safety sensors meet high accuracy standards, they are difficult to reconfigure and can only monitor a fixed user-defined region of space. Furthermore, they are typically expensive. Instead, we leverage a controllable depth sensor, programmable light curtains (PLC), to develop an inexpensive and flexible real-time safety monitoring system for collaborative robot workspaces. Our system projects virtual dynamic safety envelopes that tightly envelop the moving robot at all times and detect any objects that intrude the envelope. Furthermore, we develop an instrumentation algorithm that optimally places (multiple) PLCs in a workspace to maximize the visibility coverage of robots. Our work enables fence-less human-robot collaboration, while scaling to monitor multiple robots with few sensors. We analyze our system in a real manufacturing testbed with four robot arms and demonstrate its capabilities as a fast, accurate, and inexpensive safety monitoring solution.
Robust Trajectory and Resource Optimization for Communication-assisted UAV SAR Sensing
Apr 01, 2024In this paper, we investigate joint 3-dimensional (3D) trajectory planning and resource allocation for rotary-wing unmanned aerial vehicle (UAV) synthetic aperture radar (SAR) sensing. To support emerging real-time SAR applications and enable live mission control, we incorporate real-time communication with a ground station (GS). The UAV's main mission is the mapping of large areas of interest (AoIs) using an onboard SAR system and transferring the unprocessed raw radar data to the ground in real time. We propose a robust trajectory and resource allocation design that takes into account random UAV trajectory deviations. To this end, we model the UAV trajectory deviations and study their effect on the radar coverage. Then, we formulate a robust non-convex mixed-integer non-linear program (MINLP) such that the UAV 3D trajectory and resources are jointly optimized for maximization of the radar ground coverage. A low-complexity sub-optimal solution for the formulated problem is presented. Furthermore, to assess the performance of the sub-optimal algorithm, we derive an upper bound on the optimal solution based on monotonic optimization theory. Simulation results show that the proposed sub-optimal algorithm achieves close-to-optimal performance and not only outperforms several benchmark schemes but is also robust with respect to UAV trajectory deviations.
AOCIL: Exemplar-free Analytic Online Class Incremental Learning with Low Time and Resource Consumption
Mar 23, 2024Online Class Incremental Learning (OCIL) aims to train the model in a task-by-task manner, where data arrive in mini-batches at a time while previous data are not accessible. A significant challenge is known as Catastrophic Forgetting, i.e., loss of the previous knowledge on old data. To address this, replay-based methods show competitive results but invade data privacy, while exemplar-free methods protect data privacy but struggle for accuracy. In this paper, we proposed an exemplar-free approach -- Analytic Online Class Incremental Learning (AOCIL). Instead of back-propagation, we design the Analytic Classifier (AC) updated by recursive least square, cooperating with a frozen backbone. AOCIL simultaneously achieves high accuracy, low resource consumption and data privacy protection. We conduct massive experiments on four existing benchmark datasets, and the results demonstrate the strong capability of handling OCIL scenarios. Codes will be ready.
Towards the Development of a Real-Time Deepfake Audio Detection System in Communication Platforms
Mar 18, 2024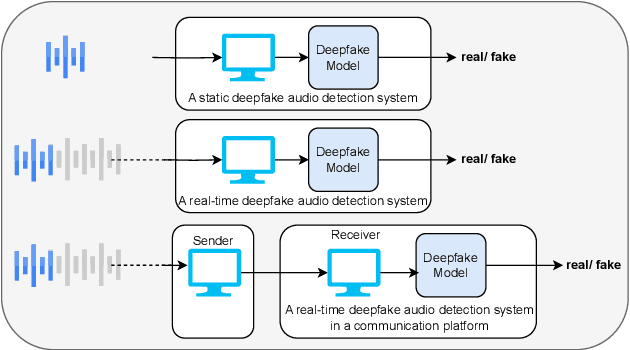
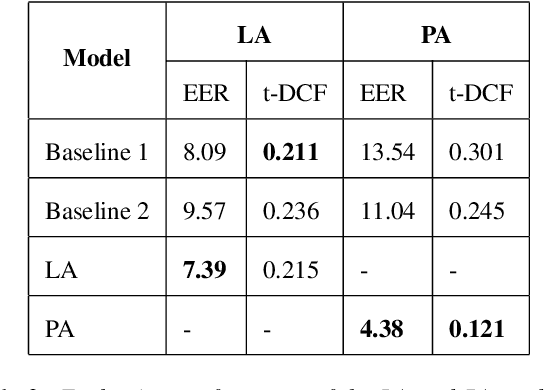
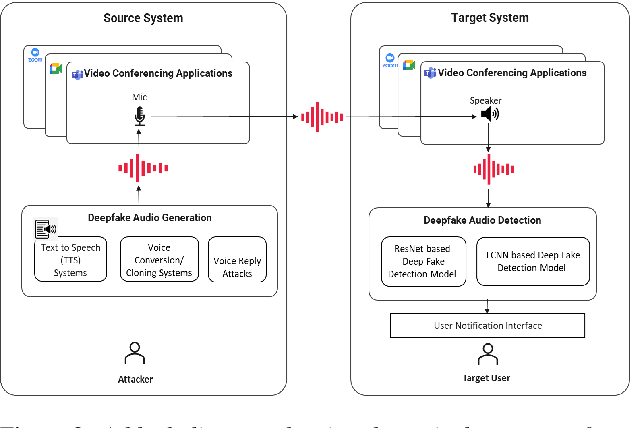
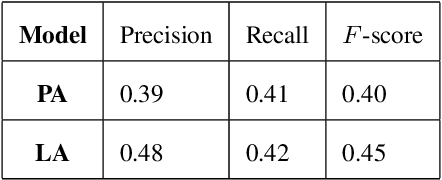
Deepfake audio poses a rising threat in communication platforms, necessitating real-time detection for audio stream integrity. Unlike traditional non-real-time approaches, this study assesses the viability of employing static deepfake audio detection models in real-time communication platforms. An executable software is developed for cross-platform compatibility, enabling real-time execution. Two deepfake audio detection models based on Resnet and LCNN architectures are implemented using the ASVspoof 2019 dataset, achieving benchmark performances compared to ASVspoof 2019 challenge baselines. The study proposes strategies and frameworks for enhancing these models, paving the way for real-time deepfake audio detection in communication platforms. This work contributes to the advancement of audio stream security, ensuring robust detection capabilities in dynamic, real-time communication scenarios.
Tackling the Singularities at the Endpoints of Time Intervals in Diffusion Models
Mar 20, 2024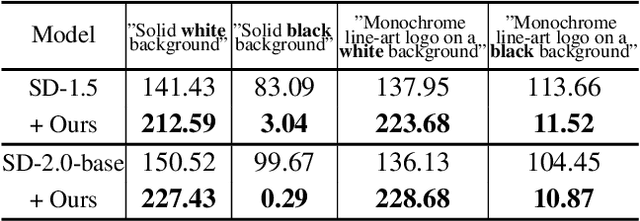
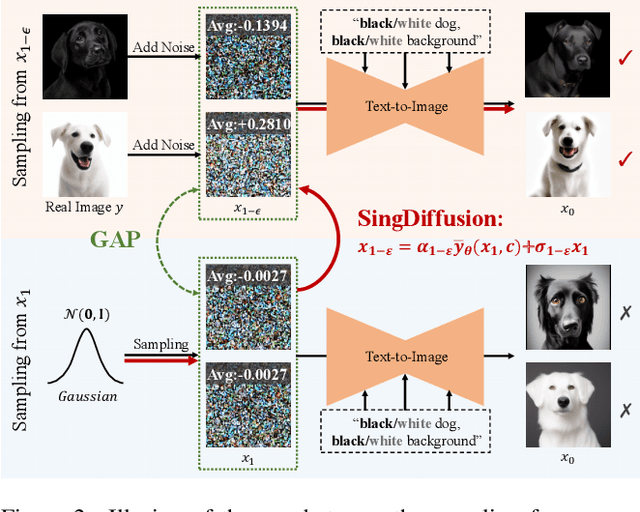


Most diffusion models assume that the reverse process adheres to a Gaussian distribution. However, this approximation has not been rigorously validated, especially at singularities, where t=0 and t=1. Improperly dealing with such singularities leads to an average brightness issue in applications, and limits the generation of images with extreme brightness or darkness. We primarily focus on tackling singularities from both theoretical and practical perspectives. Initially, we establish the error bounds for the reverse process approximation, and showcase its Gaussian characteristics at singularity time steps. Based on this theoretical insight, we confirm the singularity at t=1 is conditionally removable while it at t=0 is an inherent property. Upon these significant conclusions, we propose a novel plug-and-play method SingDiffusion to address the initial singular time step sampling, which not only effectively resolves the average brightness issue for a wide range of diffusion models without extra training efforts, but also enhances their generation capability in achieving notable lower FID scores.
Continuous Spiking Graph Neural Networks
Apr 02, 2024Continuous graph neural networks (CGNNs) have garnered significant attention due to their ability to generalize existing discrete graph neural networks (GNNs) by introducing continuous dynamics. They typically draw inspiration from diffusion-based methods to introduce a novel propagation scheme, which is analyzed using ordinary differential equations (ODE). However, the implementation of CGNNs requires significant computational power, making them challenging to deploy on battery-powered devices. Inspired by recent spiking neural networks (SNNs), which emulate a biological inference process and provide an energy-efficient neural architecture, we incorporate the SNNs with CGNNs in a unified framework, named Continuous Spiking Graph Neural Networks (COS-GNN). We employ SNNs for graph node representation at each time step, which are further integrated into the ODE process along with time. To enhance information preservation and mitigate information loss in SNNs, we introduce the high-order structure of COS-GNN, which utilizes the second-order ODE for spiking representation and continuous propagation. Moreover, we provide the theoretical proof that COS-GNN effectively mitigates the issues of exploding and vanishing gradients, enabling us to capture long-range dependencies between nodes. Experimental results on graph-based learning tasks demonstrate the effectiveness of the proposed COS-GNN over competitive baselines.