 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Intelligent Anomaly Detection for Lane Rendering Using Transformer with Self-Supervised Pre-Training and Customized Fine-Tuning
Dec 07, 2023
The burgeoning navigation services using digital maps provide great convenience to drivers. Nevertheless, the presence of anomalies in lane rendering map images occasionally introduces potential hazards, as such anomalies can be misleading to human drivers and consequently contribute to unsafe driving conditions. In response to this concern and to accurately and effectively detect the anomalies, this paper transforms lane rendering image anomaly detection into a classification problem and proposes a four-phase pipeline consisting of data pre-processing, self-supervised pre-training with the masked image modeling (MiM) method, customized fine-tuning using cross-entropy based loss with label smoothing, and post-processing to tackle it leveraging state-of-the-art deep learning techniques, especially those involving Transformer models. Various experiments verify the effectiveness of the proposed pipeline. Results indicate that the proposed pipeline exhibits superior performance in lane rendering image anomaly detection, and notably, the self-supervised pre-training with MiM can greatly enhance the detection accuracy while significantly reducing the total training time. For instance, employing the Swin Transformer with Uniform Masking as self-supervised pretraining (Swin-Trans-UM) yielded a heightened accuracy at 94.77% and an improved Area Under The Curve (AUC) score of 0.9743 compared with the pure Swin Transformer without pre-training (Swin-Trans) with an accuracy of 94.01% and an AUC of 0.9498. The fine-tuning epochs were dramatically reduced to 41 from the original 280. In conclusion, the proposed pipeline, with its incorporation of self-supervised pre-training using MiM and other advanced deep learning techniques, emerges as a robust solution for enhancing the accuracy and efficiency of lane rendering image anomaly detection in digital navigation systems.
DGR: Tackling Drifted and Correlated Noise in Quantum Error Correction via Decoding Graph Re-weighting
Dec 07, 2023
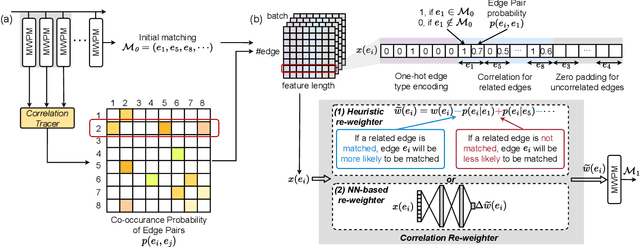
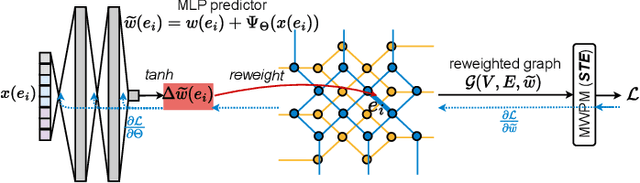
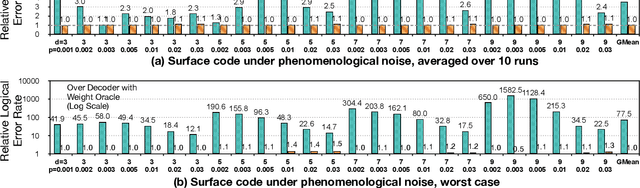
Quantum hardware suffers from high error rates and noise, which makes directly running applications on them ineffective. Quantum Error Correction (QEC) is a critical technique towards fault tolerance which encodes the quantum information distributively in multiple data qubits and uses syndrome qubits to check parity. Minimum-Weight-Perfect-Matching (MWPM) is a popular QEC decoder that takes the syndromes as input and finds the matchings between syndromes that infer the errors. However, there are two paramount challenges for MWPM decoders. First, as noise in real quantum systems can drift over time, there is a potential misalignment with the decoding graph's initial weights, leading to a severe performance degradation in the logical error rates. Second, while the MWPM decoder addresses independent errors, it falls short when encountering correlated errors typical on real hardware, such as those in the 2Q depolarizing channel. We propose DGR, an efficient decoding graph edge re-weighting strategy with no quantum overhead. It leverages the insight that the statistics of matchings across decoding iterations offer rich information about errors on real quantum hardware. By counting the occurrences of edges and edge pairs in decoded matchings, we can statistically estimate the up-to-date probabilities of each edge and the correlations between them. The reweighting process includes two vital steps: alignment re-weighting and correlation re-weighting. The former updates the MWPM weights based on statistics to align with actual noise, and the latter adjusts the weight considering edge correlations. Extensive evaluations on surface code and honeycomb code under various settings show that DGR reduces the logical error rate by 3.6x on average-case noise mismatch with exceeding 5000x improvement under worst-case mismatch.
Multi-agricultural Machinery Collaborative Task Assignment Based on Improved Genetic Hybrid Optimization Algorithm
Dec 07, 2023

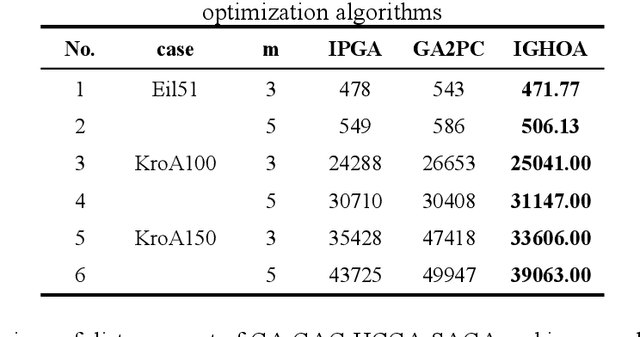
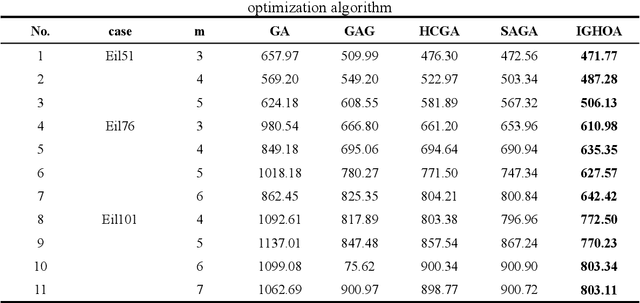
To address the challenges of delayed scheduling information, heavy reliance on manual labour, and low operational efficiency in traditional large-scale agricultural machinery operations, this study proposes a method for multi-agricultural machinery collaborative task assignment based on an improved genetic hybrid optimisation algorithm. The proposed method establishes a multi-agricultural machinery task allocation model by combining the path pre-planning of a simulated annealing algorithm and the static task allocation of a genetic algorithm. By sequentially fusing these two algorithms, their respective shortcomings can be overcome, and their advantages in global and local search can be utilised. Consequently, the search capability of the population is enhanced, leading to the discovery of more optimal solutions. Then, an adaptive crossover operator is constructed according to the task assignment model, considering the capacity, path cost, and time of agricultural machinery; two-segment coding and multi-population adaptive mutation are used to assign tasks to improve the diversity of the population and enhance the exploration ability of the population; and to improve the global optimisation ability of the hybrid algorithm, a 2-Opt local optimisation operator and an Circle modification algorithm are introduced. Finally, simulation experiments were conducted in MATLAB to evaluate the performance of the multi-agricultural machinery collaborative task assignment based on the improved genetic hybrid algorithm. The algorithm's capabilities were assessed through comparative analysis in the simulation trials. The results demonstrate that the developed hybrid algorithm can effectively reduce path costs, and the efficiency of the assignment outcomes surpasses that of the classical genetic algorithm. This approach proves particularly suitable for addressing large-scale task allocation problems.
SparsePoser: Real-time Full-body Motion Reconstruction from Sparse Data
Nov 03, 2023
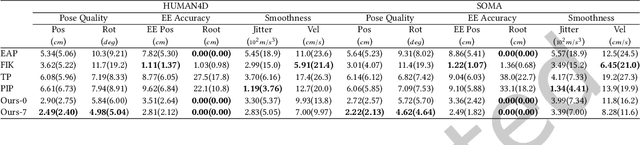
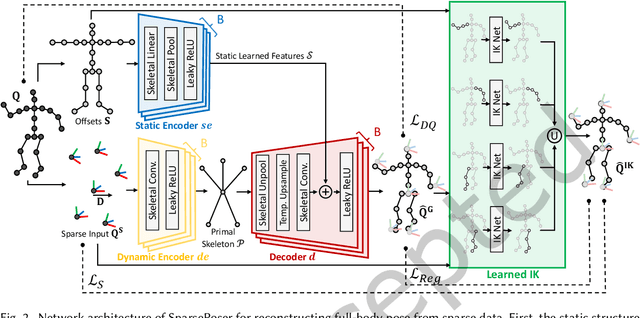
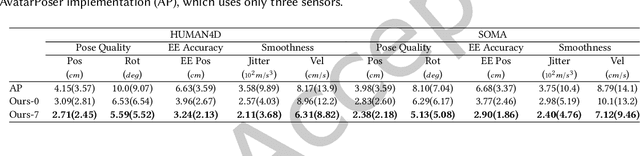
Accurate and reliable human motion reconstruction is crucial for creating natural interactions of full-body avatars in Virtual Reality (VR) and entertainment applications. As the Metaverse and social applications gain popularity, users are seeking cost-effective solutions to create full-body animations that are comparable in quality to those produced by commercial motion capture systems. In order to provide affordable solutions, though, it is important to minimize the number of sensors attached to the subject's body. Unfortunately, reconstructing the full-body pose from sparse data is a heavily under-determined problem. Some studies that use IMU sensors face challenges in reconstructing the pose due to positional drift and ambiguity of the poses. In recent years, some mainstream VR systems have released 6-degree-of-freedom (6-DoF) tracking devices providing positional and rotational information. Nevertheless, most solutions for reconstructing full-body poses rely on traditional inverse kinematics (IK) solutions, which often produce non-continuous and unnatural poses. In this article, we introduce SparsePoser, a novel deep learning-based solution for reconstructing a full-body pose from a reduced set of six tracking devices. Our system incorporates a convolutional-based autoencoder that synthesizes high-quality continuous human poses by learning the human motion manifold from motion capture data. Then, we employ a learned IK component, made of multiple lightweight feed-forward neural networks, to adjust the hands and feet toward the corresponding trackers. We extensively evaluate our method on publicly available motion capture datasets and with real-time live demos. We show that our method outperforms state-of-the-art techniques using IMU sensors or 6-DoF tracking devices, and can be used for users with different body dimensions and proportions.
DreamPropeller: Supercharge Text-to-3D Generation with Parallel Sampling
Nov 28, 2023Recent methods such as Score Distillation Sampling (SDS) and Variational Score Distillation (VSD) using 2D diffusion models for text-to-3D generation have demonstrated impressive generation quality. However, the long generation time of such algorithms significantly degrades the user experience. To tackle this problem, we propose DreamPropeller, a drop-in acceleration algorithm that can be wrapped around any existing text-to-3D generation pipeline based on score distillation. Our framework generalizes Picard iterations, a classical algorithm for parallel sampling an ODE path, and can account for non-ODE paths such as momentum-based gradient updates and changes in dimensions during the optimization process as in many cases of 3D generation. We show that our algorithm trades parallel compute for wallclock time and empirically achieves up to 4.7x speedup with a negligible drop in generation quality for all tested frameworks.
Point'n Move: Interactive Scene Object Manipulation on Gaussian Splatting Radiance Fields
Nov 28, 2023We propose Point'n Move, a method that achieves interactive scene object manipulation with exposed region inpainting. Interactivity here further comes from intuitive object selection and real-time editing. To achieve this, we adopt Gaussian Splatting Radiance Field as the scene representation and fully leverage its explicit nature and speed advantage. Its explicit representation formulation allows us to devise a 2D prompt points to 3D mask dual-stage self-prompting segmentation algorithm, perform mask refinement and merging, minimize change as well as provide good initialization for scene inpainting and perform editing in real-time without per-editing training, all leads to superior quality and performance. We test our method by performing editing on both forward-facing and 360 scenes. We also compare our method against existing scene object removal methods, showing superior quality despite being more capable and having a speed advantage.
AMLNet: Adversarial Mutual Learning Neural Network for Non-AutoRegressive Multi-Horizon Time Series Forecasting
Oct 30, 2023Multi-horizon time series forecasting, crucial across diverse domains, demands high accuracy and speed. While AutoRegressive (AR) models excel in short-term predictions, they suffer speed and error issues as the horizon extends. Non-AutoRegressive (NAR) models suit long-term predictions but struggle with interdependence, yielding unrealistic results. We introduce AMLNet, an innovative NAR model that achieves realistic forecasts through an online Knowledge Distillation (KD) approach. AMLNet harnesses the strengths of both AR and NAR models by training a deep AR decoder and a deep NAR decoder in a collaborative manner, serving as ensemble teachers that impart knowledge to a shallower NAR decoder. This knowledge transfer is facilitated through two key mechanisms: 1) outcome-driven KD, which dynamically weights the contribution of KD losses from the teacher models, enabling the shallow NAR decoder to incorporate the ensemble's diversity; and 2) hint-driven KD, which employs adversarial training to extract valuable insights from the model's hidden states for distillation. Extensive experimentation showcases AMLNet's superiority over conventional AR and NAR models, thereby presenting a promising avenue for multi-horizon time series forecasting that enhances accuracy and expedites computation.
Event-based Visual Inertial Velometer
Nov 30, 2023Neuromorphic event-based cameras are bio-inspired visual sensors with asynchronous pixels and extremely high temporal resolution. Such favorable properties make them an excellent choice for solving state estimation tasks under aggressive ego motion. However, failures of camera pose tracking are frequently witnessed in state-of-the-art event-based visual odometry systems when the local map cannot be updated in time. One of the biggest roadblocks for this specific field is the absence of efficient and robust methods for data association without imposing any assumption on the environment. This problem seems, however, unlikely to be addressed as in standard vision due to the motion-dependent observability of event data. Therefore, we propose a mapping-free design for event-based visual-inertial state estimation in this paper. Instead of estimating the position of the event camera, we find that recovering the instantaneous linear velocity is more consistent with the differential working principle of event cameras. The proposed event-based visual-inertial velometer leverages a continuous-time formulation that incrementally fuses the heterogeneous measurements from a stereo event camera and an inertial measurement unit. Experiments on the synthetic dataset demonstrate that the proposed method can recover instantaneous linear velocity in metric scale with low latency.
Large Language Model is a Good Policy Teacher for Training Reinforcement Learning Agents
Nov 29, 2023Recent studies have shown that Large Language Models (LLMs) can be utilized for solving complex sequential decision-making tasks by providing high-level instructions. However, LLM-based agents face limitations in real-time dynamic environments due to their lack of specialization in solving specific target problems. Moreover, the deployment of such LLM-based agents is both costly and time-consuming in practical scenarios. In this paper, we introduce a novel framework that addresses these challenges by training a smaller scale specialized student agent using instructions from an LLM-based teacher agent. By leveraging guided actions provided by the teachers, the prior knowledge of the LLM is distilled into the local student model. Consequently, the student agent can be trained with significantly less data. Furthermore, subsequent training with environment feedback empowers the student agents to surpass the capabilities of their teachers. We conducted experiments on three challenging MiniGrid environments to evaluate the effectiveness of our framework. The results demonstrate that our approach enhances sample efficiency and achieves superior performance compared to baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
rTsfNet: a DNN model with Multi-head 3D Rotation and Time Series Feature Extraction for IMU-based Human Activity Recognition
Nov 01, 2023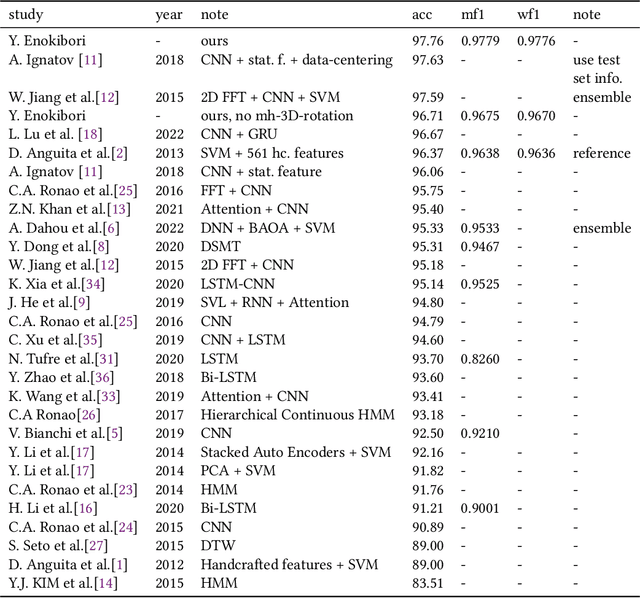
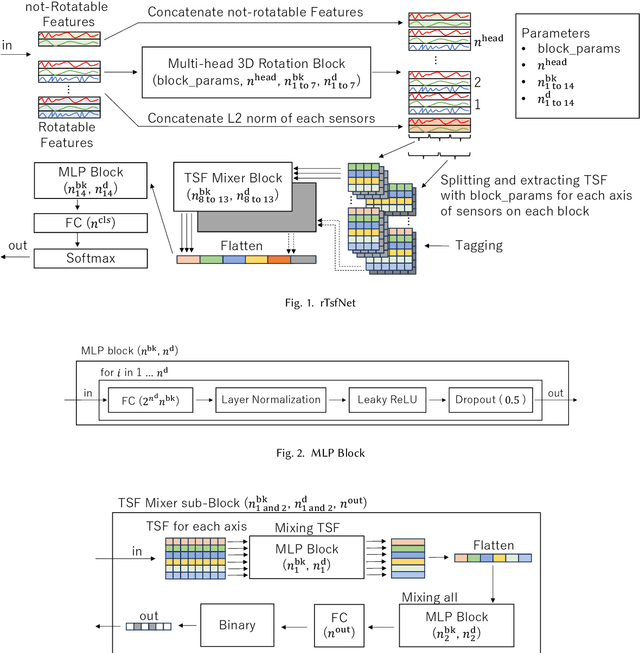

This paper proposes rTsfNet, a DNN model with Multi-head 3D Rotation and Time Series Feature Extraction, as a new DNN model for IMU-based human activity recognition (HAR). rTsfNet automatically selects 3D bases from which features should be derived by deriving 3D rotation parameters within the DNN. Then, time series features (TSFs), the wisdom of many researchers, are derived and realize HAR using MLP. Although a model that does not use CNN, it achieved the highest accuracy than existing models under well-managed benchmark conditions and multiple datasets: UCI HAR, PAMAP2, Daphnet, and OPPORTUNITY, which target different activities.