 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low-power, Continuous Remote Behavioral Localization with Event Cameras
Dec 06, 2023
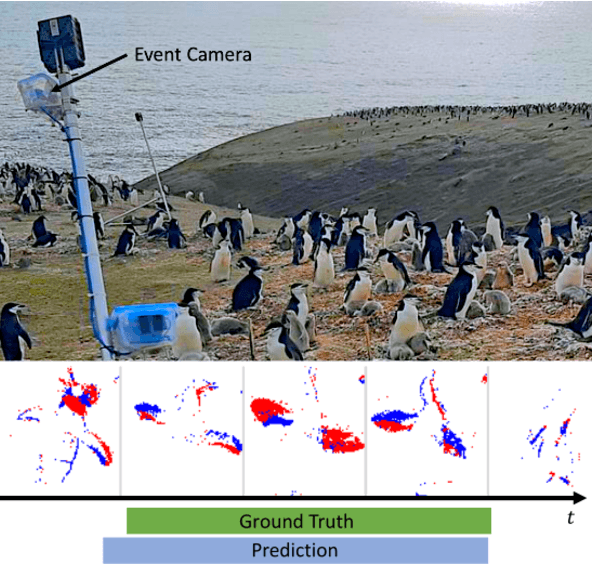
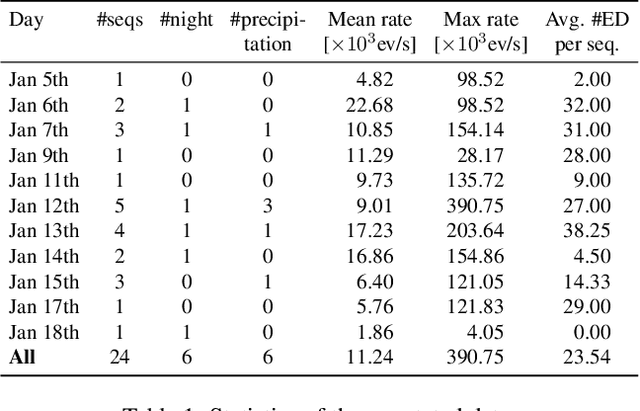

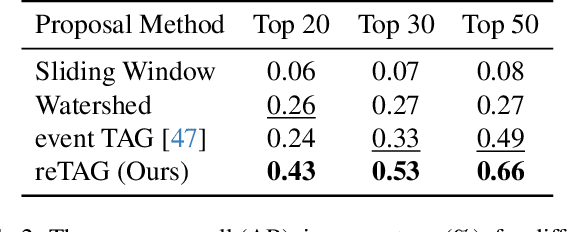
Researchers in natural science need reliable methods for quantifying animal behavior. Recently, numerous computer vision methods emerged to automate the process. However, observing wild species at remote locations remains a challenging task due to difficult lighting conditions and constraints on power supply and data storage. Event cameras offer unique advantages for battery-dependent remote monitoring due to their low power consumption and high dynamic range capabilities. We use this novel sensor to quantify a behavior in Chinstrap penguins called ecstatic display. We formulate the problem as a temporal action detection task, determining the start and end times of the behavior. For this purpose, we recorded a colony of breeding penguins in Antarctica during several weeks and labeled event data on 16 nests. The developed method consists of a generator of candidate time intervals (proposals) and a classifier of the actions within them. The experiments show that the event cameras' natural response to motion is effective for continuous behavior monitoring and detection, reaching a mean average precision (mAP) of 58% (which increases to 63% in good weather conditions). The results also demonstrate the robustness against various lighting conditions contained in the challenging dataset. The low-power capabilities of the event camera allows to record three times longer than with a conventional camera. This work pioneers the use of event cameras for remote wildlife observation, opening new interdisciplinary opportunities. https://tub-rip.github.io/eventpenguins/
Highly Accelerated Weighted MMSE Algorithms for Designing Precoders in FDD Systems with Incomplete CSI
Dec 04, 2023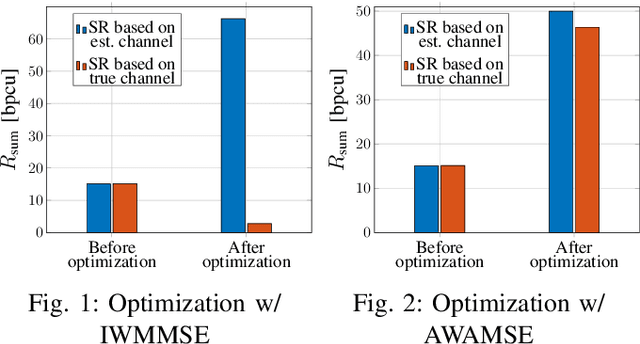
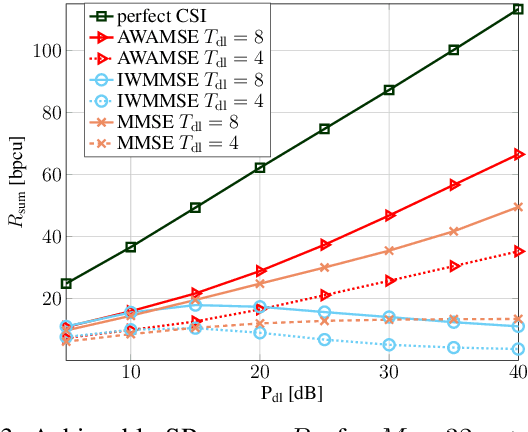
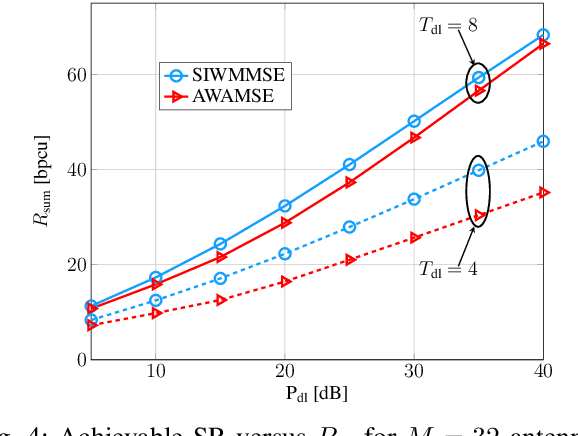
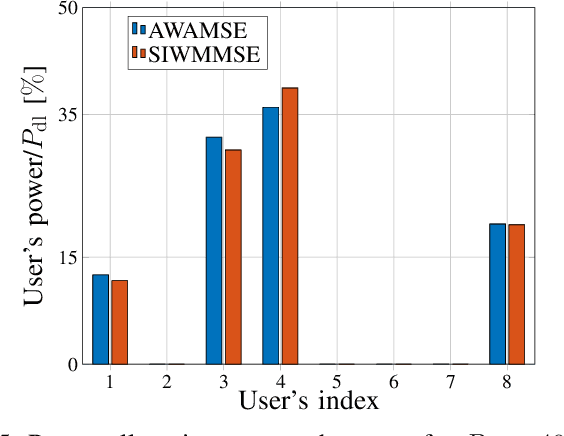
In this work, we derive a lower bound on the training-based achievable downlink (DL) sum rate (SR) of a multi-user multiple-input-single-output (MISO) system operating in frequency-division-duplex (FDD) mode. Assuming linear minimum mean square error (LMMSE) channel estimation is used, we establish a connection of the derived lower bound on the signal-to-interference-noise-ratio (SINR) to an average MSE that allows to reformulate the SR maximization problem as the minimization of the augmented weighted average MSE (AWAMSE). We propose an iterative precoder design with three alternating steps, all given in closed form, drastically reducing the computation time. We show numerically the effectiveness of the proposed approach in challenging scenarios with limited channel knowledge, i.e., we consider scenarios with a very limited number of pilots. We additionally propose a more efficient version of the well-known stochastic iterative WMMSE (SIWMMSE) approach, where the precoder update is given in closed form.
HumanNeRF-SE: A Simple yet Effective Approach to Animate HumanNeRF with Diverse Poses
Dec 04, 2023We present HumanNeRF-SE, which can synthesize diverse novel pose images with simple input. Previous HumanNeRF studies require large neural networks to fit the human appearance and prior knowledge. Subsequent methods build upon this approach with some improvements. Instead, we reconstruct this approach, combining explicit and implicit human representations with both general and specific mapping processes. Our key insight is that explicit shape can filter the information used to fit implicit representation, and frozen general mapping combined with point-specific mapping can effectively avoid overfitting and improve pose generalization performance. Our explicit and implicit human represent combination architecture is extremely effective. This is reflected in our model's ability to synthesize images under arbitrary poses with few-shot input and increase the speed of synthesizing images by 15 times through a reduction in computational complexity without using any existing acceleration modules. Compared to the state-of-the-art HumanNeRF studies, HumanNeRF-SE achieves better performance with fewer learnable parameters and less training time (see Figure 1).
FedEmb: A Vertical and Hybrid Federated Learning Algorithm using Network And Feature Embedding Aggregation
Dec 04, 2023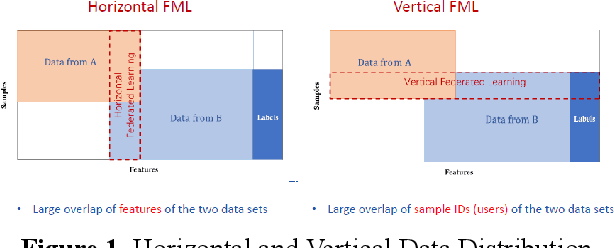

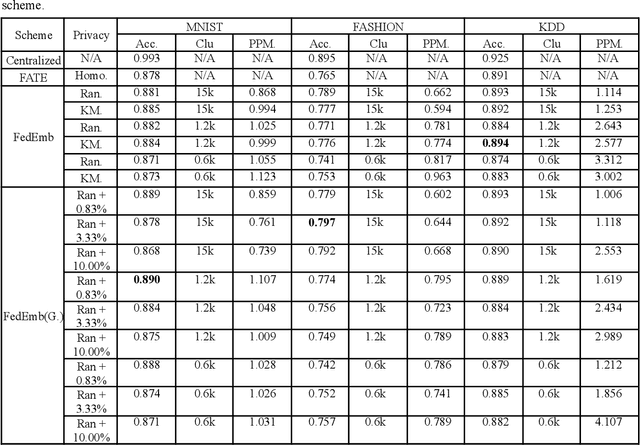
Federated learning (FL) is an emerging paradigm for decentralized training of machine learning models on distributed clients, without revealing the data to the central server. The learning scheme may be horizontal, vertical or hybrid (both vertical and horizontal). Most existing research work with deep neural network (DNN) modelling is focused on horizontal data distributions, while vertical and hybrid schemes are much less studied. In this paper, we propose a generalized algorithm FedEmb, for modelling vertical and hybrid DNN-based learning. The idea of our algorithm is characterised by higher inference accuracy, stronger privacy-preserving properties, and lower client-server communication bandwidth demands as compared with existing work. The experimental results show that FedEmb is an effective method to tackle both split feature & subject space decentralized problems, shows 0.3% to 4.2% inference accuracy improvement with limited privacy revealing for datasets stored in local clients, and reduces 88.9 % time complexity over vertical baseline method.
* Accepted by Proceedings on Engineering Sciences
FDM Printing: a Fabrication Method for Fluidic Soft Circuits?
Dec 02, 2023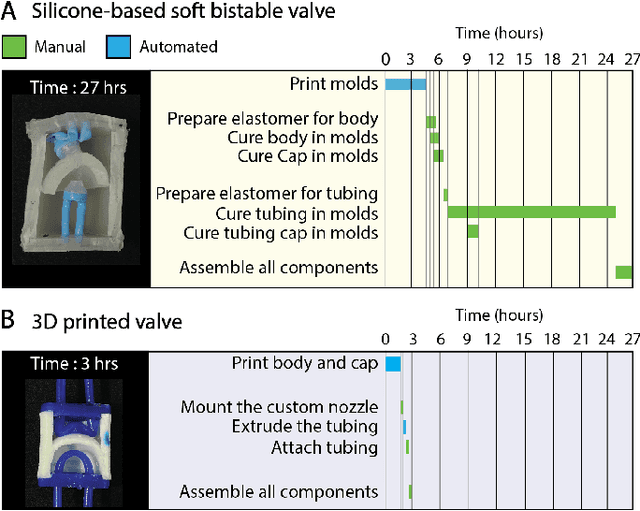
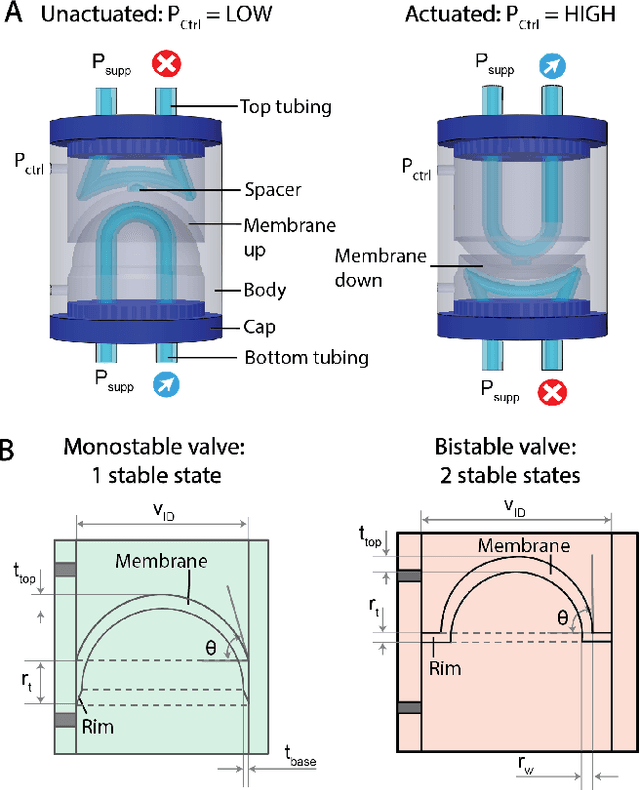
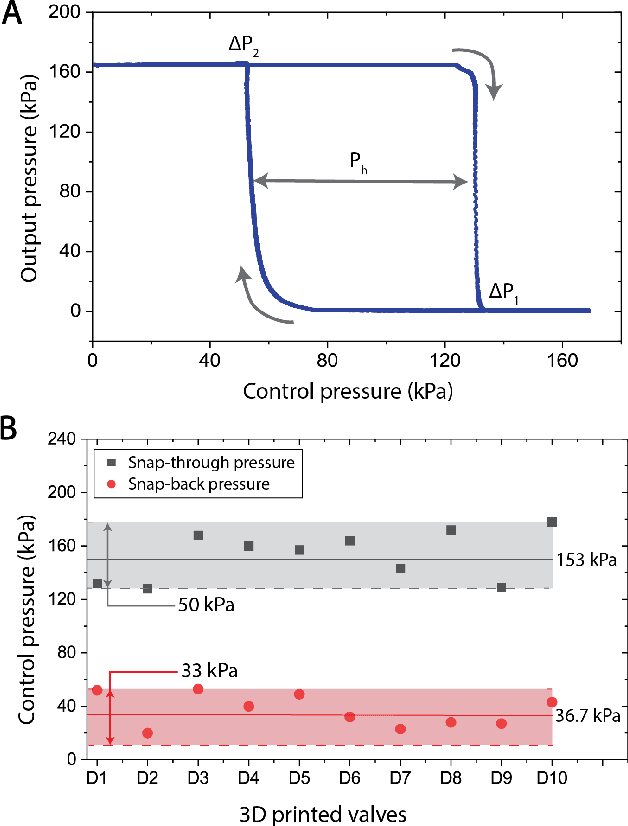
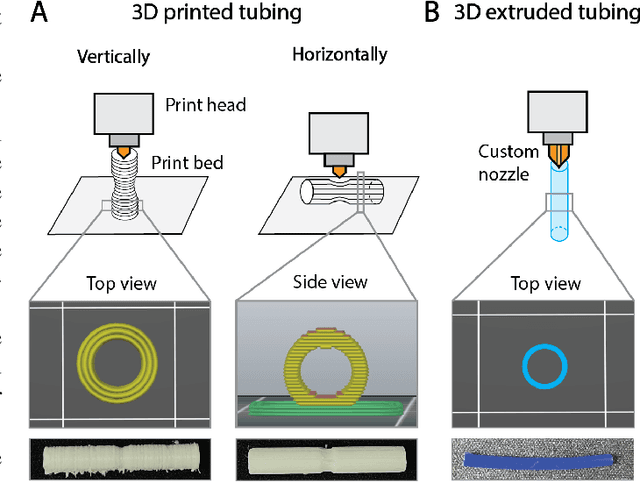
Existing fluidic soft logic gates for the control of soft robots either rely on extensive manual fabrication processes or expensive printing techniques. In our work, we explore Fused Deposition Modeling for creating fully 3D printed fluidic logic gates. We print a soft bistable valve from thermoplastic polyurethane using a desktop FDM printer. We introduce a new printing nozzle for extruding tubing. Our fabrication strategy reduces the production time of soft bistable valves from 27 hours with replica molding to 3 hours with a FDM printer. Our rapid and cost-effective fabrication process for fluidic logic gates seeks to democratize fluidic circuitry for the control of soft robots.
GPT vs Human for Scientific Reviews: A Dual Source Review on Applications of ChatGPT in Science
Dec 05, 2023The new polymath Large Language Models (LLMs) can speed-up greatly scientific reviews, possibly using more unbiased quantitative metrics, facilitating cross-disciplinary connections, and identifying emerging trends and research gaps by analyzing large volumes of data. However, at the present time, they lack the required deep understanding of complex methodologies, they have difficulty in evaluating innovative claims, and they are unable to assess ethical issues and conflicts of interest. Herein, we consider 13 GPT-related papers across different scientific domains, reviewed by a human reviewer and SciSpace, a large language model, with the reviews evaluated by three distinct types of evaluators, namely GPT-3.5, a crowd panel, and GPT-4. We found that 50% of SciSpace's responses to objective questions align with those of a human reviewer, with GPT-4 (informed evaluator) often rating the human reviewer higher in accuracy, and SciSpace higher in structure, clarity, and completeness. In subjective questions, the uninformed evaluators (GPT-3.5 and crowd panel) showed varying preferences between SciSpace and human responses, with the crowd panel showing a preference for the human responses. However, GPT-4 rated them equally in accuracy and structure but favored SciSpace for completeness.
Customization Assistant for Text-to-image Generation
Dec 05, 2023
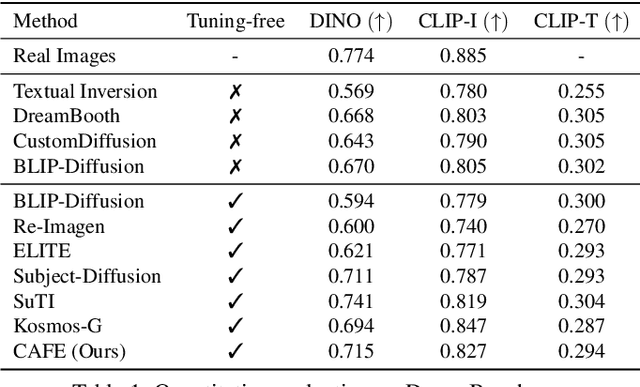
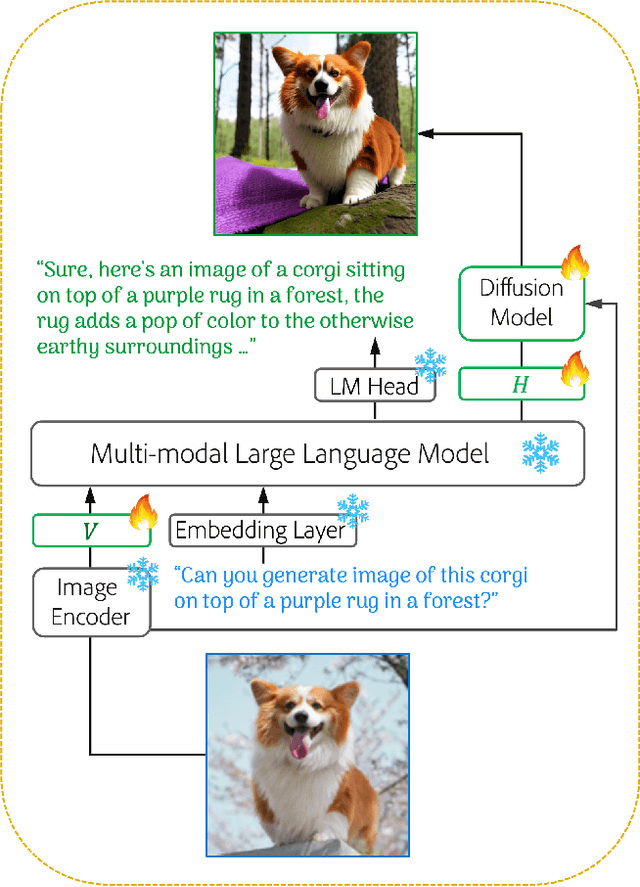
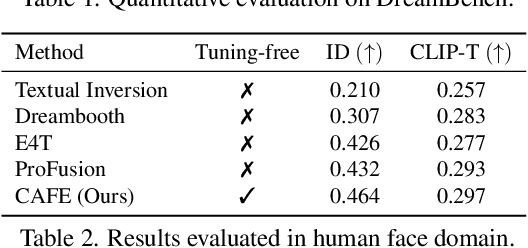
Customizing pre-trained text-to-image generation model has attracted massive research interest recently, due to its huge potential in real-world applications. Although existing methods are able to generate creative content for a novel concept contained in single user-input image, their capability are still far from perfection. Specifically, most existing methods require fine-tuning the generative model on testing images. Some existing methods do not require fine-tuning, while their performance are unsatisfactory. Furthermore, the interaction between users and models are still limited to directive and descriptive prompts such as instructions and captions. In this work, we build a customization assistant based on pre-trained large language model and diffusion model, which can not only perform customized generation in a tuning-free manner, but also enable more user-friendly interactions: users can chat with the assistant and input either ambiguous text or clear instruction. Specifically, we propose a new framework consists of a new model design and a novel training strategy. The resulting assistant can perform customized generation in 2-5 seconds without any test time fine-tuning. Extensive experiments are conducted, competitive results have been obtained across different domains, illustrating the effectiveness of the proposed method.
(Provable) Adversarial Robustness for Group Equivariant Tasks: Graphs, Point Clouds, Molecules, and More
Dec 05, 2023A machine learning model is traditionally considered robust if its prediction remains (almost) constant under input perturbations with small norm. However, real-world tasks like molecular property prediction or point cloud segmentation have inherent equivariances, such as rotation or permutation equivariance. In such tasks, even perturbations with large norm do not necessarily change an input's semantic content. Furthermore, there are perturbations for which a model's prediction explicitly needs to change. For the first time, we propose a sound notion of adversarial robustness that accounts for task equivariance. We then demonstrate that provable robustness can be achieved by (1) choosing a model that matches the task's equivariances (2) certifying traditional adversarial robustness. Certification methods are, however, unavailable for many models, such as those with continuous equivariances. We close this gap by developing the framework of equivariance-preserving randomized smoothing, which enables architecture-agnostic certification. We additionally derive the first architecture-specific graph edit distance certificates, i.e. sound robustness guarantees for isomorphism equivariant tasks like node classification. Overall, a sound notion of robustness is an important prerequisite for future work at the intersection of robust and geometric machine learning.
GDN: A Stacking Network Used for Skin Cancer Diagnosis
Dec 05, 2023Skin cancer, the primary type of cancer that can be identified by visual recognition, requires an automatic identification system that can accurately classify different types of lesions. This paper presents GoogLe-Dense Network (GDN), which is an image-classification model to identify two types of skin cancer, Basal Cell Carcinoma, and Melanoma. GDN uses stacking of different networks to enhance the model performance. Specifically, GDN consists of two sequential levels in its structure. The first level performs basic classification tasks accomplished by GoogLeNet and DenseNet, which are trained in parallel to enhance efficiency. To avoid low accuracy and long training time, the second level takes the output of the GoogLeNet and DenseNet as the input for a logistic regression model. We compare our method with four baseline networks including ResNet, VGGNet, DenseNet, and GoogLeNet on the dataset, in which GoogLeNet and DenseNet significantly outperform ResNet and VGGNet. In the second level, different stacking methods such as perceptron, logistic regression, SVM, decision trees and K-neighbor are studied in which Logistic Regression shows the best prediction result among all. The results prove that GDN, compared to a single network structure, has higher accuracy in optimizing skin cancer detection.
GNSS Odometry: Precise Trajectory Estimation Based on Carrier Phase Cycle Slip Estimation
Dec 05, 2023This paper proposes a highly accurate trajectory estimation method for outdoor mobile robots using global navigation satellite system (GNSS) time differences of carrier phase (TDCP) measurements. By using GNSS TDCP, the relative 3D position can be estimated with millimeter precision. However, when a phenomenon called cycle slip occurs, wherein the carrier phase measurement jumps and becomes discontinuous, it is impossible to accurately estimate the relative position using TDCP. Although previous studies have eliminated the effect of cycle slip using a robust optimization technique, it was difficult to completely eliminate the effect of outliers. In this paper, we propose a method to detect GNSS carrier phase cycle slip, estimate the amount of cycle slip, and modify the observed TDCP to calculate the relative position using the factor graph optimization framework. The estimated relative position acts as a loop closure in graph optimization and contributes to the reduction in the integration error of the relative position. Experiments with an unmanned aerial vehicle showed that by modifying the cycle slip using the proposed method, the vehicle trajectory could be estimated with an accuracy of 5 to 30 cm using only a single GNSS receiver, without using any other external data or sensors.
* Published in IEEE Robotics and Automation Letters (RA-L) and presented at the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022