 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Animatable 3D Gaussian: Fast and High-Quality Reconstruction of Multiple Human Avatars
Nov 29, 2023
Neural radiance fields are capable of reconstructing high-quality drivable human avatars but are expensive to train and render. To reduce consumption, we propose Animatable 3D Gaussian, which learns human avatars from input images and poses. We extend 3D Gaussians to dynamic human scenes by modeling a set of skinned 3D Gaussians and a corresponding skeleton in canonical space and deforming 3D Gaussians to posed space according to the input poses. We introduce hash-encoded shape and appearance to speed up training and propose time-dependent ambient occlusion to achieve high-quality reconstructions in scenes containing complex motions and dynamic shadows. On both novel view synthesis and novel pose synthesis tasks, our method outperforms existing methods in terms of training time, rendering speed, and reconstruction quality. Our method can be easily extended to multi-human scenes and achieve comparable novel view synthesis results on a scene with ten people in only 25 seconds of training.
ROSO: Improving Robotic Policy Inference via Synthetic Observations
Nov 29, 2023In this paper, we propose the use of generative artificial intelligence (AI) to improve zero-shot performance of a pre-trained policy by altering observations during inference. Modern robotic systems, powered by advanced neural networks, have demonstrated remarkable capabilities on pre-trained tasks. However, generalizing and adapting to new objects and environments is challenging, and fine-tuning visuomotor policies is time-consuming. To overcome these issues we propose Robotic Policy Inference via Synthetic Observations (ROSO). ROSO uses stable diffusion to pre-process a robot's observation of novel objects during inference time to fit within its distribution of observations of the pre-trained policies. This novel paradigm allows us to transfer learned knowledge from known tasks to previously unseen scenarios, enhancing the robot's adaptability without requiring lengthy fine-tuning. Our experiments show that incorporating generative AI into robotic inference significantly improves successful outcomes, finishing up to 57% of tasks otherwise unsuccessful with the pre-trained policy.
HumanNeRF-SE: A Simple yet Effective Approach to Animate HumanNeRF with Diverse Poses
Dec 04, 2023We present HumanNeRF-SE, which can synthesize diverse novel pose images with simple input. Previous HumanNeRF studies require large neural networks to fit the human appearance and prior knowledge. Subsequent methods build upon this approach with some improvements. Instead, we reconstruct this approach, combining explicit and implicit human representations with both general and specific mapping processes. Our key insight is that explicit shape can filter the information used to fit implicit representation, and frozen general mapping combined with point-specific mapping can effectively avoid overfitting and improve pose generalization performance. Our explicit and implicit human represent combination architecture is extremely effective. This is reflected in our model's ability to synthesize images under arbitrary poses with few-shot input and increase the speed of synthesizing images by 15 times through a reduction in computational complexity without using any existing acceleration modules. Compared to the state-of-the-art HumanNeRF studies, HumanNeRF-SE achieves better performance with fewer learnable parameters and less training time (see Figure 1).
Highly Accelerated Weighted MMSE Algorithms for Designing Precoders in FDD Systems with Incomplete CSI
Dec 04, 2023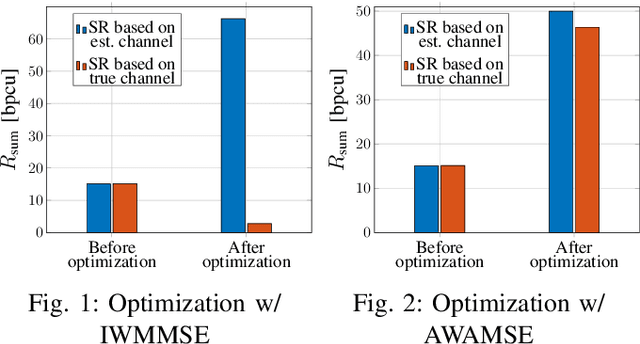
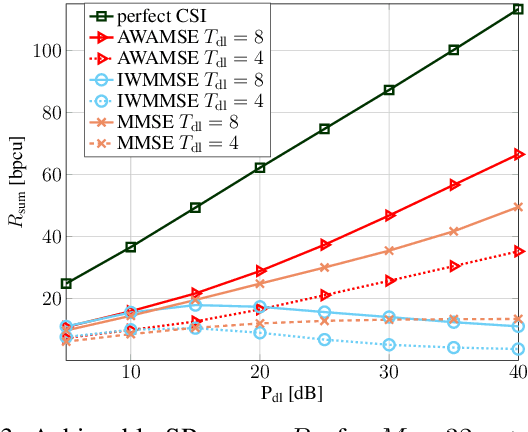
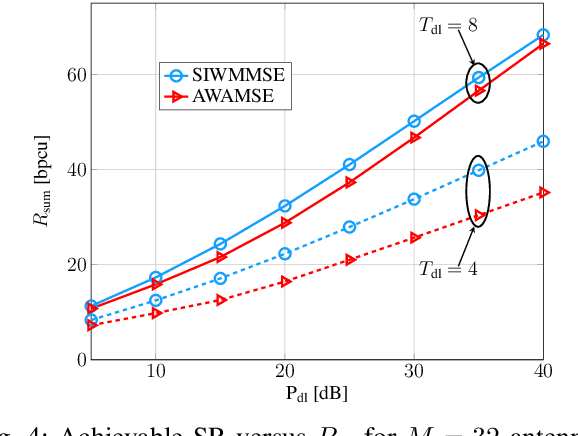
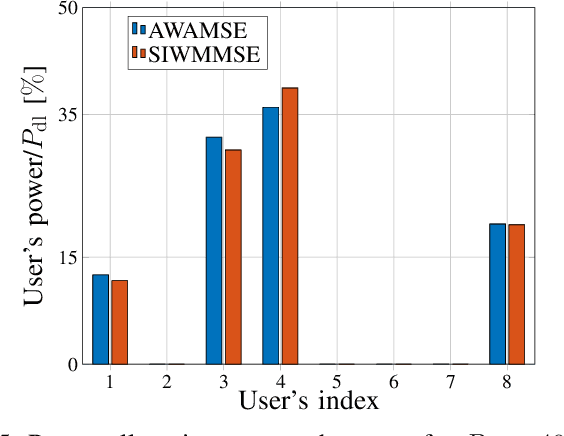
In this work, we derive a lower bound on the training-based achievable downlink (DL) sum rate (SR) of a multi-user multiple-input-single-output (MISO) system operating in frequency-division-duplex (FDD) mode. Assuming linear minimum mean square error (LMMSE) channel estimation is used, we establish a connection of the derived lower bound on the signal-to-interference-noise-ratio (SINR) to an average MSE that allows to reformulate the SR maximization problem as the minimization of the augmented weighted average MSE (AWAMSE). We propose an iterative precoder design with three alternating steps, all given in closed form, drastically reducing the computation time. We show numerically the effectiveness of the proposed approach in challenging scenarios with limited channel knowledge, i.e., we consider scenarios with a very limited number of pilots. We additionally propose a more efficient version of the well-known stochastic iterative WMMSE (SIWMMSE) approach, where the precoder update is given in closed form.
FedEmb: A Vertical and Hybrid Federated Learning Algorithm using Network And Feature Embedding Aggregation
Dec 04, 2023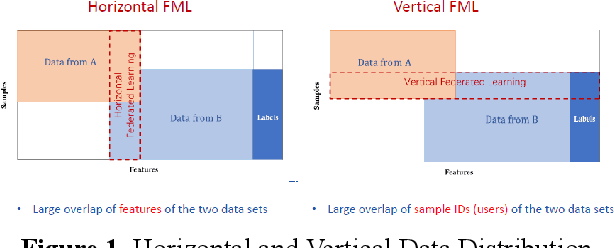

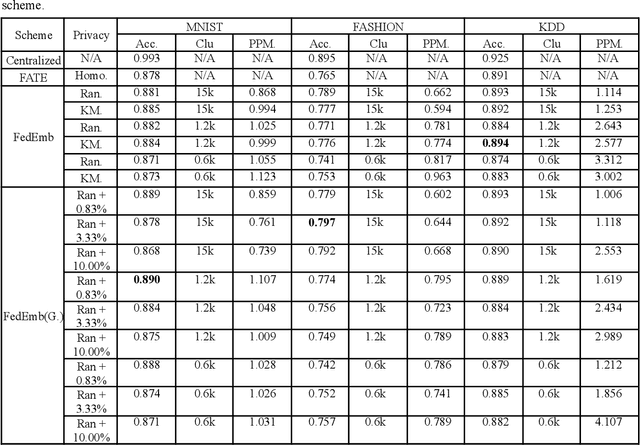
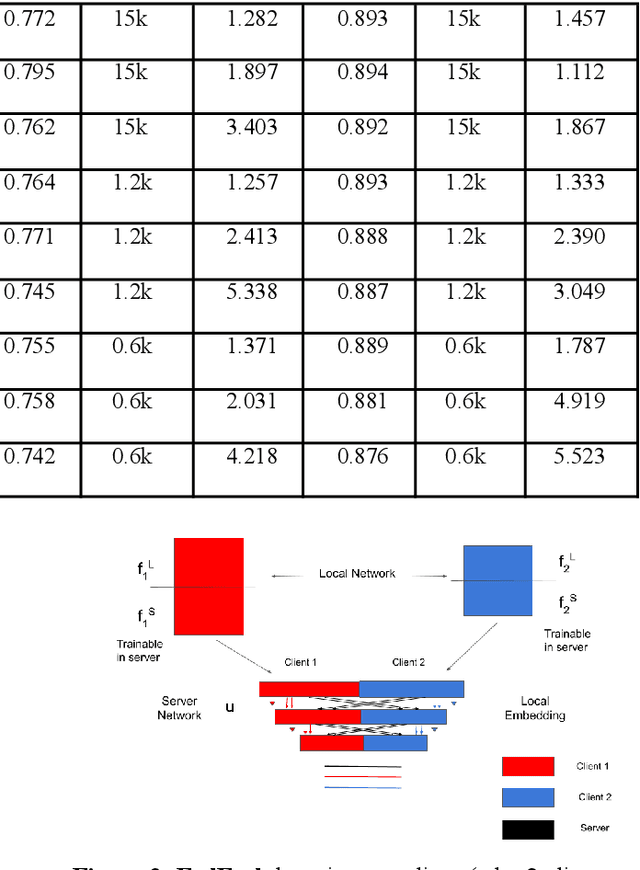
Federated learning (FL) is an emerging paradigm for decentralized training of machine learning models on distributed clients, without revealing the data to the central server. The learning scheme may be horizontal, vertical or hybrid (both vertical and horizontal). Most existing research work with deep neural network (DNN) modelling is focused on horizontal data distributions, while vertical and hybrid schemes are much less studied. In this paper, we propose a generalized algorithm FedEmb, for modelling vertical and hybrid DNN-based learning. The idea of our algorithm is characterised by higher inference accuracy, stronger privacy-preserving properties, and lower client-server communication bandwidth demands as compared with existing work. The experimental results show that FedEmb is an effective method to tackle both split feature & subject space decentralized problems, shows 0.3% to 4.2% inference accuracy improvement with limited privacy revealing for datasets stored in local clients, and reduces 88.9 % time complexity over vertical baseline method.
* Accepted by Proceedings on Engineering Sciences
Sensitivity Analysis in the Presence of Intrinsic Stochasticity for Discrete Fracture Network Simulations
Dec 07, 2023Large-scale discrete fracture network (DFN) simulators are standard fare for studies involving the sub-surface transport of particles since direct observation of real world underground fracture networks is generally infeasible. While these simulators have seen numerous successes over several engineering applications, estimations on quantities of interest (QoI) - such as breakthrough time of particles reaching the edge of the system - suffer from a two distinct types of uncertainty. A run of a DFN simulator requires several parameter values to be set that dictate the placement and size of fractures, the density of fractures, and the overall permeability of the system; uncertainty on the proper parameter choices will lead to some amount of uncertainty in the QoI, called epistemic uncertainty. Furthermore, since DFN simulators rely on stochastic processes to place fractures and govern flow, understanding how this randomness affects the QoI requires several runs of the simulator at distinct random seeds. The uncertainty in the QoI attributed to different realizations (i.e. different seeds) of the same random process leads to a second type of uncertainty, called aleatoric uncertainty. In this paper, we perform a Sensitivity Analysis, which directly attributes the uncertainty observed in the QoI to the epistemic uncertainty from each input parameter and to the aleatoric uncertainty. We make several design choices to handle an observed heteroskedasticity in DFN simulators, where the aleatoric uncertainty changes for different inputs, since the quality makes several standard statistical methods inadmissible. Beyond the specific takeaways on which input variables affect uncertainty the most for DFN simulators, a major contribution of this paper is the introduction of a statistically rigorous workflow for characterizing the uncertainty in DFN flow simulations that exhibit heteroskedasticity.
Relational Deep Learning: Graph Representation Learning on Relational Databases
Dec 07, 2023Much of the world's most valued data is stored in relational databases and data warehouses, where the data is organized into many tables connected by primary-foreign key relations. However, building machine learning models using this data is both challenging and time consuming. The core problem is that no machine learning method is capable of learning on multiple tables interconnected by primary-foreign key relations. Current methods can only learn from a single table, so the data must first be manually joined and aggregated into a single training table, the process known as feature engineering. Feature engineering is slow, error prone and leads to suboptimal models. Here we introduce an end-to-end deep representation learning approach to directly learn on data laid out across multiple tables. We name our approach Relational Deep Learning (RDL). The core idea is to view relational databases as a temporal, heterogeneous graph, with a node for each row in each table, and edges specified by primary-foreign key links. Message Passing Graph Neural Networks can then automatically learn across the graph to extract representations that leverage all input data, without any manual feature engineering. Relational Deep Learning leads to more accurate models that can be built much faster. To facilitate research in this area, we develop RelBench, a set of benchmark datasets and an implementation of Relational Deep Learning. The data covers a wide spectrum, from discussions on Stack Exchange to book reviews on the Amazon Product Catalog. Overall, we define a new research area that generalizes graph machine learning and broadens its applicability to a wide set of AI use cases.
Intelligent Anomaly Detection for Lane Rendering Using Transformer with Self-Supervised Pre-Training and Customized Fine-Tuning
Dec 07, 2023The burgeoning navigation services using digital maps provide great convenience to drivers. Nevertheless, the presence of anomalies in lane rendering map images occasionally introduces potential hazards, as such anomalies can be misleading to human drivers and consequently contribute to unsafe driving conditions. In response to this concern and to accurately and effectively detect the anomalies, this paper transforms lane rendering image anomaly detection into a classification problem and proposes a four-phase pipeline consisting of data pre-processing, self-supervised pre-training with the masked image modeling (MiM) method, customized fine-tuning using cross-entropy based loss with label smoothing, and post-processing to tackle it leveraging state-of-the-art deep learning techniques, especially those involving Transformer models. Various experiments verify the effectiveness of the proposed pipeline. Results indicate that the proposed pipeline exhibits superior performance in lane rendering image anomaly detection, and notably, the self-supervised pre-training with MiM can greatly enhance the detection accuracy while significantly reducing the total training time. For instance, employing the Swin Transformer with Uniform Masking as self-supervised pretraining (Swin-Trans-UM) yielded a heightened accuracy at 94.77% and an improved Area Under The Curve (AUC) score of 0.9743 compared with the pure Swin Transformer without pre-training (Swin-Trans) with an accuracy of 94.01% and an AUC of 0.9498. The fine-tuning epochs were dramatically reduced to 41 from the original 280. In conclusion, the proposed pipeline, with its incorporation of self-supervised pre-training using MiM and other advanced deep learning techniques, emerges as a robust solution for enhancing the accuracy and efficiency of lane rendering image anomaly detection in digital navigation systems.
Multi-agricultural Machinery Collaborative Task Assignment Based on Improved Genetic Hybrid Optimization Algorithm
Dec 07, 2023

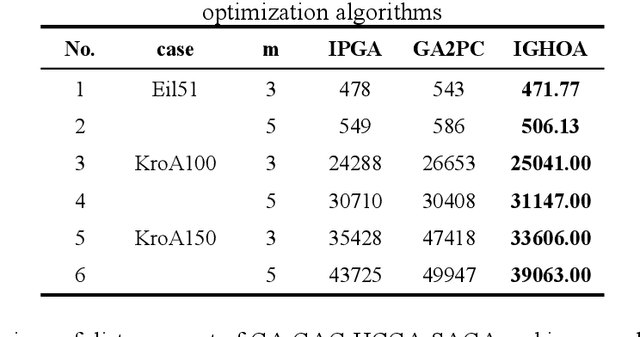
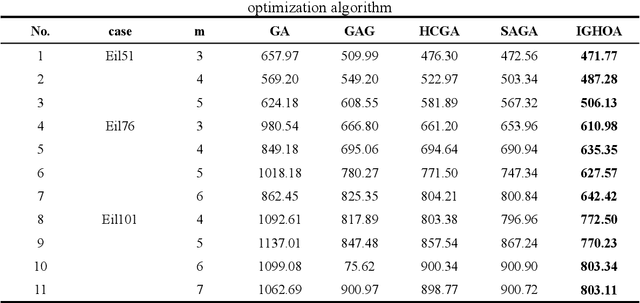
To address the challenges of delayed scheduling information, heavy reliance on manual labour, and low operational efficiency in traditional large-scale agricultural machinery operations, this study proposes a method for multi-agricultural machinery collaborative task assignment based on an improved genetic hybrid optimisation algorithm. The proposed method establishes a multi-agricultural machinery task allocation model by combining the path pre-planning of a simulated annealing algorithm and the static task allocation of a genetic algorithm. By sequentially fusing these two algorithms, their respective shortcomings can be overcome, and their advantages in global and local search can be utilised. Consequently, the search capability of the population is enhanced, leading to the discovery of more optimal solutions. Then, an adaptive crossover operator is constructed according to the task assignment model, considering the capacity, path cost, and time of agricultural machinery; two-segment coding and multi-population adaptive mutation are used to assign tasks to improve the diversity of the population and enhance the exploration ability of the population; and to improve the global optimisation ability of the hybrid algorithm, a 2-Opt local optimisation operator and an Circle modification algorithm are introduced. Finally, simulation experiments were conducted in MATLAB to evaluate the performance of the multi-agricultural machinery collaborative task assignment based on the improved genetic hybrid algorithm. The algorithm's capabilities were assessed through comparative analysis in the simulation trials. The results demonstrate that the developed hybrid algorithm can effectively reduce path costs, and the efficiency of the assignment outcomes surpasses that of the classical genetic algorithm. This approach proves particularly suitable for addressing large-scale task allocation problems.
DGR: Tackling Drifted and Correlated Noise in Quantum Error Correction via Decoding Graph Re-weighting
Dec 07, 2023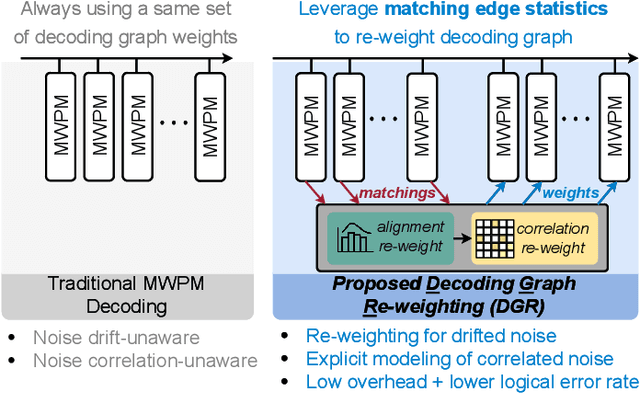
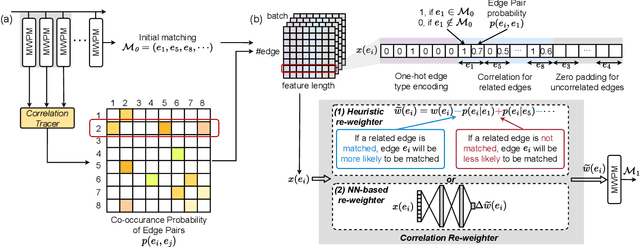
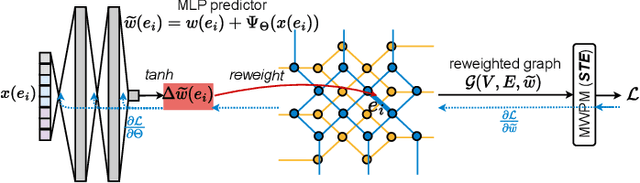
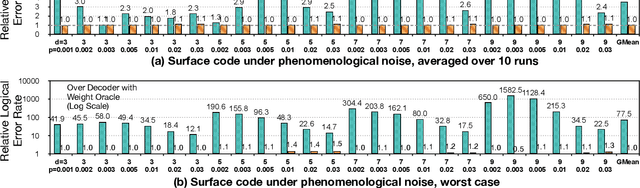
Quantum hardware suffers from high error rates and noise, which makes directly running applications on them ineffective. Quantum Error Correction (QEC) is a critical technique towards fault tolerance which encodes the quantum information distributively in multiple data qubits and uses syndrome qubits to check parity. Minimum-Weight-Perfect-Matching (MWPM) is a popular QEC decoder that takes the syndromes as input and finds the matchings between syndromes that infer the errors. However, there are two paramount challenges for MWPM decoders. First, as noise in real quantum systems can drift over time, there is a potential misalignment with the decoding graph's initial weights, leading to a severe performance degradation in the logical error rates. Second, while the MWPM decoder addresses independent errors, it falls short when encountering correlated errors typical on real hardware, such as those in the 2Q depolarizing channel. We propose DGR, an efficient decoding graph edge re-weighting strategy with no quantum overhead. It leverages the insight that the statistics of matchings across decoding iterations offer rich information about errors on real quantum hardware. By counting the occurrences of edges and edge pairs in decoded matchings, we can statistically estimate the up-to-date probabilities of each edge and the correlations between them. The reweighting process includes two vital steps: alignment re-weighting and correlation re-weighting. The former updates the MWPM weights based on statistics to align with actual noise, and the latter adjusts the weight considering edge correlations. Extensive evaluations on surface code and honeycomb code under various settings show that DGR reduces the logical error rate by 3.6x on average-case noise mismatch with exceeding 5000x improvement under worst-case mismatch.