 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Change Points Detection for Linear Dynamical Systems with Finite Sample Guarantees
Nov 30, 2023
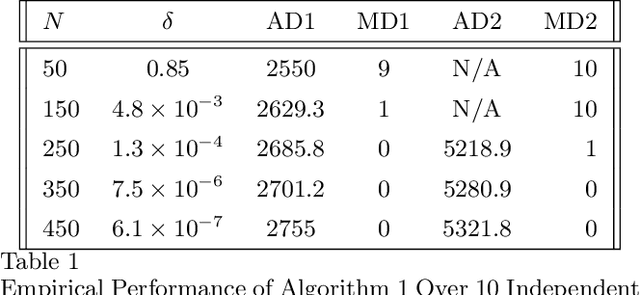
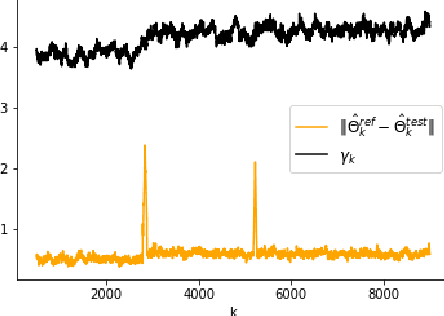
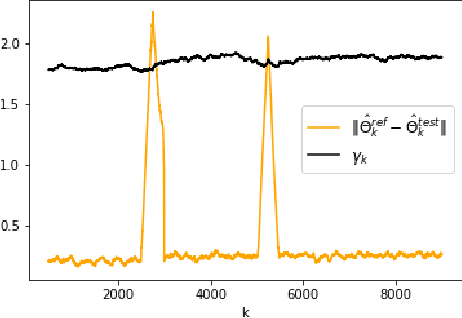
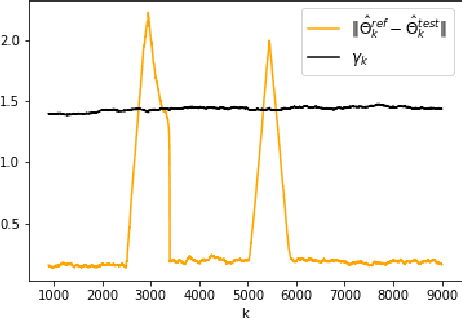
The problem of online change point detection is to detect abrupt changes in properties of time series, ideally as soon as possible after those changes occur. Existing work on online change point detection either assumes i.i.d data, focuses on asymptotic analysis, does not present theoretical guarantees on the trade-off between detection accuracy and detection delay, or is only suitable for detecting single change points. In this work, we study the online change point detection problem for linear dynamical systems with unknown dynamics, where the data exhibits temporal correlations and the system could have multiple change points. We develop a data-dependent threshold that can be used in our test that allows one to achieve a pre-specified upper bound on the probability of making a false alarm. We further provide a finite-sample-based bound for the probability of detecting a change point. Our bound demonstrates how parameters used in our algorithm affect the detection probability and delay, and provides guidance on the minimum required time between changes to guarantee detection.
SARA-RT: Scaling up Robotics Transformers with Self-Adaptive Robust Attention
Dec 04, 2023

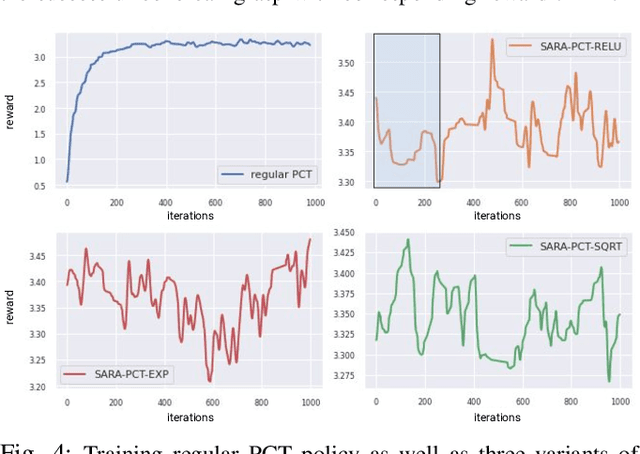

We present Self-Adaptive Robust Attention for Robotics Transformers (SARA-RT): a new paradigm for addressing the emerging challenge of scaling up Robotics Transformers (RT) for on-robot deployment. SARA-RT relies on the new method of fine-tuning proposed by us, called up-training. It converts pre-trained or already fine-tuned Transformer-based robotic policies of quadratic time complexity (including massive billion-parameter vision-language-action models or VLAs), into their efficient linear-attention counterparts maintaining high quality. We demonstrate the effectiveness of SARA-RT by speeding up: (a) the class of recently introduced RT-2 models, the first VLA robotic policies pre-trained on internet-scale data, as well as (b) Point Cloud Transformer (PCT) robotic policies operating on large point clouds. We complement our results with the rigorous mathematical analysis providing deeper insight into the phenomenon of SARA.
Image Synthesis-based Late Stage Cancer Augmentation and Semi-Supervised Segmentation for MRI Rectal Cancer Staging
Dec 08, 2023Rectal cancer is one of the most common diseases and a major cause of mortality. For deciding rectal cancer treatment plans, T-staging is important. However, evaluating the index from preoperative MRI images requires high radiologists' skill and experience. Therefore, the aim of this study is to segment the mesorectum, rectum, and rectal cancer region so that the system can predict T-stage from segmentation results. Generally, shortage of large and diverse dataset and high quality annotation are known to be the bottlenecks in computer aided diagnostics development. Regarding rectal cancer, advanced cancer images are very rare, and per-pixel annotation requires high radiologists' skill and time. Therefore, it is not feasible to collect comprehensive disease patterns in a training dataset. To tackle this, we propose two kinds of approaches of image synthesis-based late stage cancer augmentation and semi-supervised learning which is designed for T-stage prediction. In the image synthesis data augmentation approach, we generated advanced cancer images from labels. The real cancer labels were deformed to resemble advanced cancer labels by artificial cancer progress simulation. Next, we introduce a T-staging loss which enables us to train segmentation models from per-image T-stage labels. The loss works to keep inclusion/invasion relationships between rectum and cancer region consistent to the ground truth T-stage. The verification tests show that the proposed method obtains the best sensitivity (0.76) and specificity (0.80) in distinguishing between over T3 stage and underT2. In the ablation studies, our semi-supervised learning approach with the T-staging loss improved specificity by 0.13. Adding the image synthesis-based data augmentation improved the DICE score of invasion cancer area by 0.08 from baseline.
Making the End-User a Priority in Benchmarking: OrionBench for Unsupervised Time Series Anomaly Detection
Oct 26, 2023Time series anomaly detection is a prevalent problem in many application domains such as patient monitoring in healthcare, forecasting in finance, or predictive maintenance in energy. This has led to the emergence of a plethora of anomaly detection methods, including more recently, deep learning based methods. Although several benchmarks have been proposed to compare newly developed models, they usually rely on one-time execution over a limited set of datasets and the comparison is restricted to a few models. We propose OrionBench -- a user centric continuously maintained benchmark for unsupervised time series anomaly detection. The framework provides universal abstractions to represent models, extensibility to add new pipelines and datasets, hyperparameter standardization, pipeline verification, and frequent releases with published benchmarks. We demonstrate the usage of OrionBench, and the progression of pipelines across 15 releases published over the course of three years. Moreover, we walk through two real scenarios we experienced with OrionBench that highlight the importance of continuous benchmarks in unsupervised time series anomaly detection.
Fusing Temporal Graphs into Transformers for Time-Sensitive Question Answering
Oct 30, 2023Answering time-sensitive questions from long documents requires temporal reasoning over the times in questions and documents. An important open question is whether large language models can perform such reasoning solely using a provided text document, or whether they can benefit from additional temporal information extracted using other systems. We address this research question by applying existing temporal information extraction systems to construct temporal graphs of events, times, and temporal relations in questions and documents. We then investigate different approaches for fusing these graphs into Transformer models. Experimental results show that our proposed approach for fusing temporal graphs into input text substantially enhances the temporal reasoning capabilities of Transformer models with or without fine-tuning. Additionally, our proposed method outperforms various graph convolution-based approaches and establishes a new state-of-the-art performance on SituatedQA and three splits of TimeQA.
Multi-task Planar Reconstruction with Feature Warping Guidance
Nov 25, 2023Piece-wise planar 3D reconstruction simultaneously segments plane instances and recovers their 3D plane parameters from an image, which is particularly useful for indoor or man-made environments. Efficient reconstruction of 3D planes coupled with semantic predictions offers advantages for a wide range of applications requiring scene understanding and concurrent spatial mapping. However, most existing planar reconstruction models either neglect semantic predictions or do not run efficiently enough for real-time applications. We introduce SoloPlanes, a real-time planar reconstruction model based on a modified instance segmentation architecture which simultaneously predicts semantics for each plane instance, along with plane parameters and piece-wise plane instance masks. By providing multi-view guidance in feature space, we achieve an improvement in instance mask segmentation despite only warping plane features due to the nature of feature sharing in multi-task learning. Our model simultaneously predicts semantics using single images at inference time, while achieving real-time predictions at 43 FPS. The code will be released post-publication.
Radio Source Localization using Sparse Signal Measurements from Uncrewed Ground Vehicles
Dec 06, 2023Radio source localization can benefit many fields, including wireless communications, radar, radio astronomy, wireless sensor networks, positioning systems, and surveillance systems. However, accurately estimating the position of a radio transmitter using a remote sensor is not an easy task, as many factors contribute to the highly dynamic behavior of radio signals. In this study, we investigate techniques to use a mobile robot to explore an outdoor area and localize the radio source using sparse Received Signal Strength Indicator (RSSI) measurements. We propose a novel radio source localization method with fast turnaround times and reduced complexity compared to the state-of-the-art. Our technique uses RSSI measurements collected while the robot completed a sparse trajectory using a coverage path planning map. The mean RSSI within each grid cell was used to find the most likely cell containing the source. Three techniques were analyzed with the data from eight field tests using a mobile robot. The proposed method can localize a gas source in a basketball field with a 1.2 m accuracy and within three minutes of convergence time, whereas the state-of-the-art active sensing technique took more than 30 minutes to reach a source estimation accuracy below 1 m.
From Detection to Action Recognition: An Edge-Based Pipeline for Robot Human Perception
Dec 06, 2023Mobile service robots are proving to be increasingly effective in a range of applications, such as healthcare, monitoring Activities of Daily Living (ADL), and facilitating Ambient Assisted Living (AAL). These robots heavily rely on Human Action Recognition (HAR) to interpret human actions and intentions. However, for HAR to function effectively on service robots, it requires prior knowledge of human presence (human detection) and identification of individuals to monitor (human tracking). In this work, we propose an end-to-end pipeline that encompasses the entire process, starting from human detection and tracking, leading to action recognition. The pipeline is designed to operate in near real-time while ensuring all stages of processing are performed on the edge, reducing the need for centralised computation. To identify the most suitable models for our mobile robot, we conducted a series of experiments comparing state-of-the-art solutions based on both their detection performance and efficiency. To evaluate the effectiveness of our proposed pipeline, we proposed a dataset comprising daily household activities. By presenting our findings and analysing the results, we demonstrate the efficacy of our approach in enabling mobile robots to understand and respond to human behaviour in real-world scenarios relying mainly on the data from their RGB cameras.
Subnetwork-to-go: Elastic Neural Network with Dynamic Training and Customizable Inference
Dec 06, 2023Deploying neural networks to different devices or platforms is in general challenging, especially when the model size is large or model complexity is high. Although there exist ways for model pruning or distillation, it is typically required to perform a full round of model training or finetuning procedure in order to obtain a smaller model that satisfies the model size or complexity constraints. Motivated by recent works on dynamic neural networks, we propose a simple way to train a large network and flexibly extract a subnetwork from it given a model size or complexity constraint during inference. We introduce a new way to allow a large model to be trained with dynamic depth and width during the training phase, and after the large model is trained we can select a subnetwork from it with arbitrary depth and width during the inference phase with a relatively better performance compared to training the subnetwork independently from scratch. Experiment results on a music source separation model show that our proposed method can effectively improve the separation performance across different subnetwork sizes and complexities with a single large model, and training the large model takes significantly shorter time than training all the different subnetworks.
PointMoment:Mixed-Moment-based Self-Supervised Representation Learning for 3D Point Clouds
Dec 06, 2023Large and rich data is a prerequisite for effective training of deep neural networks. However, the irregularity of point cloud data makes manual annotation time-consuming and laborious. Self-supervised representation learning, which leverages the intrinsic structure of large-scale unlabelled data to learn meaningful feature representations, has attracted increasing attention in the field of point cloud research. However, self-supervised representation learning often suffers from model collapse, resulting in reduced information and diversity of the learned representation, and consequently degrading the performance of downstream tasks. To address this problem, we propose PointMoment, a novel framework for point cloud self-supervised representation learning that utilizes a high-order mixed moment loss function rather than the conventional contrastive loss function. Moreover, our framework does not require any special techniques such as asymmetric network architectures, gradient stopping, etc. Specifically, we calculate the high-order mixed moment of the feature variables and force them to decompose into products of their individual moment, thereby making multiple variables more independent and minimizing the feature redundancy. We also incorporate a contrastive learning approach to maximize the feature invariance under different data augmentations of the same point cloud. Experimental results show that our approach outperforms previous unsupervised learning methods on the downstream task of 3D point cloud classification and segmentation.