 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Metasurface Sensing Approach to DOA Estimation of Coherent Signals
Dec 05, 2023
The DOA estimation method of coherent signals based on periodical coding metasurface is proposed. After periodical coding, the DOA information of incident signals in the time domain is represented as the amplitude and phase information at different frequency points in the frequency domain. Finite time Fourier transform (FTFT) is performed on the received signal and appropriate frequency points are selected to reconstruct the frequency domain snapshot, then pattern smoothing (PS) technique is applied to execute DOA estimation. Compared with conventional DOA estimation methods, the proposed method has two main advantages: one is that only a single receiving channel is needed to avoid the appearance of channel mismatch errors, the other is that it can process with multiple coherent signals. The performance curves of the proposed method are analyzed under different conditions and compared with existing methods. Simulation results show the effectiveness of the proposed method.
Transition Path Sampling with Boltzmann Generator-based MCMC Moves
Dec 08, 2023Sampling all possible transition paths between two 3D states of a molecular system has various applications ranging from catalyst design to drug discovery. Current approaches to sample transition paths use Markov chain Monte Carlo and rely on time-intensive molecular dynamics simulations to find new paths. Our approach operates in the latent space of a normalizing flow that maps from the molecule's Boltzmann distribution to a Gaussian, where we propose new paths without requiring molecular simulations. Using alanine dipeptide, we explore Metropolis-Hastings acceptance criteria in the latent space for exact sampling and investigate different latent proposal mechanisms.
Backward Learning for Goal-Conditioned Policies
Dec 08, 2023Can we learn policies in reinforcement learning without rewards? Can we learn a policy just by trying to reach a goal state? We answer these questions positively by proposing a multi-step procedure that first learns a world model that goes backward in time, secondly generates goal-reaching backward trajectories, thirdly improves those sequences using shortest path finding algorithms, and finally trains a neural network policy by imitation learning. We evaluate our method on a deterministic maze environment where the observations are $64\times 64$ pixel bird's eye images and can show that it consistently reaches several goals.
An Overview of MLCommons Cloud Mask Benchmark: Related Research and Data
Dec 08, 2023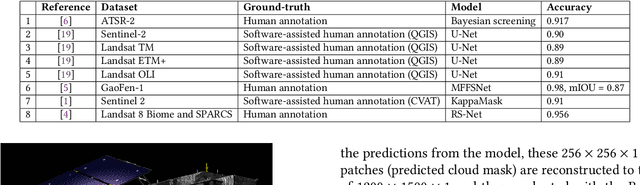
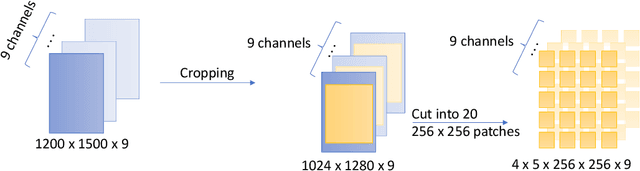
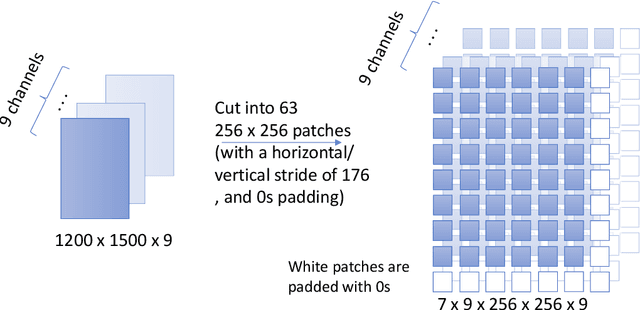
Cloud masking is a crucial task that is well-motivated for meteorology and its applications in environmental and atmospheric sciences. Its goal is, given satellite images, to accurately generate cloud masks that identify each pixel in image to contain either cloud or clear sky. In this paper, we summarize some of the ongoing research activities in cloud masking, with a focus on the research and benchmark currently conducted in MLCommons Science Working Group. This overview is produced with the hope that others will have an easier time getting started and collaborate on the activities related to MLCommons Cloud Mask Benchmark.
Early ChatGPT User Portrait through the Lens of Data
Dec 10, 2023Since its launch, ChatGPT has achieved remarkable success as a versatile conversational AI platform, drawing millions of users worldwide and garnering widespread recognition across academic, industrial, and general communities. This paper aims to point a portrait of early GPT users and understand how they evolved. Specific questions include their topics of interest and their potential careers; and how this changes over time. We conduct a detailed analysis of real-world ChatGPT datasets with multi-turn conversations between users and ChatGPT. Through a multi-pronged approach, we quantify conversation dynamics by examining the number of turns, then gauge sentiment to understand user sentiment variations, and finally employ Latent Dirichlet Allocation (LDA) to discern overarching topics within the conversation. By understanding shifts in user demographics and interests, we aim to shed light on the changing nature of human-AI interaction and anticipate future trends in user engagement with language models.
Using Curiosity for an Even Representation of Tasks in Continual Offline Reinforcement Learning
Dec 05, 2023In this work, we investigate the means of using curiosity on replay buffers to improve offline multi-task continual reinforcement learning when tasks, which are defined by the non-stationarity in the environment, are non labeled and not evenly exposed to the learner in time. In particular, we investigate the use of curiosity both as a tool for task boundary detection and as a priority metric when it comes to retaining old transition tuples, which we respectively use to propose two different buffers. Firstly, we propose a Hybrid Reservoir Buffer with Task Separation (HRBTS), where curiosity is used to detect task boundaries that are not known due to the task agnostic nature of the problem. Secondly, by using curiosity as a priority metric when it comes to retaining old transition tuples, a Hybrid Curious Buffer (HCB) is proposed. We ultimately show that these buffers, in conjunction with regular reinforcement learning algorithms, can be used to alleviate the catastrophic forgetting issue suffered by the state of the art on replay buffers when the agent's exposure to tasks is not equal along time. We evaluate catastrophic forgetting and the efficiency of our proposed buffers against the latest works such as the Hybrid Reservoir Buffer (HRB) and the Multi-Time Scale Replay Buffer (MTR) in three different continual reinforcement learning settings. Experiments were done on classical control tasks and Metaworld environment. Experiments show that our proposed replay buffers display better immunity to catastrophic forgetting compared to existing works in most of the settings.
PerSival: Neural-network-based visualisation for pervasive continuum-mechanical simulations in musculoskeletal biomechanics
Dec 07, 2023This paper presents a novel neural network architecture for the purpose of pervasive visualisation of a 3D human upper limb musculoskeletal system model. Bringing simulation capabilities to resource-poor systems like mobile devices is of growing interest across many research fields, to widen applicability of methods and results. Until recently, this goal was thought to be out of reach for realistic continuum-mechanical simulations of musculoskeletal systems, due to prohibitive computational cost. Within this work we use a sparse grid surrogate to capture the surface deformation of the m.~biceps brachii in order to train a deep learning model, used for real-time visualisation of the same muscle. Both these surrogate models take 5 muscle activation levels as input and output Cartesian coordinate vectors for each mesh node on the muscle's surface. Thus, the neural network architecture features a significantly lower input than output dimension. 5 muscle activation levels were sufficient to achieve an average error of 0.97 +/- 0.16 mm, or 0.57 +/- 0.10 % for the 2809 mesh node positions of the biceps. The model achieved evaluation times of 9.88 ms per predicted deformation state on CPU only and 3.48 ms with GPU-support, leading to theoretical frame rates of 101 fps and 287 fps respectively. Deep learning surrogates thus provide a way to make continuum-mechanical simulations accessible for visual real-time applications.
Receding Horizon Re-ordering of Multi-Agent Execution Schedules
Dec 07, 2023The trajectory planning for a fleet of Automated Guided Vehicles (AGVs) on a roadmap is commonly referred to as the Multi-Agent Path Finding (MAPF) problem, the solution to which dictates each AGV's spatial and temporal location until it reaches it's goal without collision. When executing MAPF plans in dynamic workspaces, AGVs can be frequently delayed, e.g., due to encounters with humans or third-party vehicles. If the remainder of the AGVs keeps following their individual plans, synchrony of the fleet is lost and some AGVs may pass through roadmap intersections in a different order than originally planned. Although this could reduce the cumulative route completion time of the AGVs, generally, a change in the original ordering can cause conflicts such as deadlocks. In practice, synchrony is therefore often enforced by using a MAPF execution policy employing, e.g., an Action Dependency Graph (ADG) to maintain ordering. To safely re-order without introducing deadlocks, we present the concept of the Switchable Action Dependency Graph (SADG). Using the SADG, we formulate a comparatively low-dimensional Mixed-Integer Linear Program (MILP) that repeatedly re-orders AGVs in a recursively feasible manner, thus maintaining deadlock-free guarantees, while dynamically minimizing the cumulative route completion time of all AGVs. Various simulations validate the efficiency of our approach when compared to the original ADG method as well as robust MAPF solution approaches.
Symmetric Mean-field Langevin Dynamics for Distributional Minimax Problems
Dec 02, 2023In this paper, we extend mean-field Langevin dynamics to minimax optimization over probability distributions for the first time with symmetric and provably convergent updates. We propose mean-field Langevin averaged gradient (MFL-AG), a single-loop algorithm that implements gradient descent ascent in the distribution spaces with a novel weighted averaging, and establish average-iterate convergence to the mixed Nash equilibrium. We also study both time and particle discretization regimes and prove a new uniform-in-time propagation of chaos result which accounts for the dependency of the particle interactions on all previous distributions. Furthermore, we propose mean-field Langevin anchored best response (MFL-ABR), a symmetric double-loop algorithm based on best response dynamics with linear last-iterate convergence. Finally, we study applications to zero-sum Markov games and conduct simulations demonstrating long-term optimality.
AutoMixer for Improved Multivariate Time-Series Forecasting on Business and IT Observability Data
Nov 02, 2023The efficiency of business processes relies on business key performance indicators (Biz-KPIs), that can be negatively impacted by IT failures. Business and IT Observability (BizITObs) data fuses both Biz-KPIs and IT event channels together as multivariate time series data. Forecasting Biz-KPIs in advance can enhance efficiency and revenue through proactive corrective measures. However, BizITObs data generally exhibit both useful and noisy inter-channel interactions between Biz-KPIs and IT events that need to be effectively decoupled. This leads to suboptimal forecasting performance when existing multivariate forecasting models are employed. To address this, we introduce AutoMixer, a time-series Foundation Model (FM) approach, grounded on the novel technique of channel-compressed pretrain and finetune workflows. AutoMixer leverages an AutoEncoder for channel-compressed pretraining and integrates it with the advanced TSMixer model for multivariate time series forecasting. This fusion greatly enhances the potency of TSMixer for accurate forecasts and also generalizes well across several downstream tasks. Through detailed experiments and dashboard analytics, we show AutoMixer's capability to consistently improve the Biz-KPI's forecasting accuracy (by 11-15\%) which directly translates to actionable business insights.