 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TSNet:A Two-stage Network for Image Dehazing with Multi-scale Fusion and Adaptive Learning
Apr 03, 2024
Image dehazing has been a popular topic of research for a long time. Previous deep learning-based image dehazing methods have failed to achieve satisfactory dehazing effects on both synthetic datasets and real-world datasets, exhibiting poor generalization. Moreover, single-stage networks often result in many regions with artifacts and color distortion in output images. To address these issues, this paper proposes a two-stage image dehazing network called TSNet, mainly consisting of the multi-scale fusion module (MSFM) and the adaptive learning module (ALM). Specifically, MSFM and ALM enhance the generalization of TSNet. The MSFM can obtain large receptive fields at multiple scales and integrate features at different frequencies to reduce the differences between inputs and learning objectives. The ALM can actively learn of regions of interest in images and restore texture details more effectively. Additionally, TSNet is designed as a two-stage network, where the first-stage network performs image dehazing, and the second-stage network is employed to improve issues such as artifacts and color distortion present in the results of the first-stage network. We also change the learning objective from ground truth images to opposite fog maps, which improves the learning efficiency of TSNet. Extensive experiments demonstrate that TSNet exhibits superior dehazing performance on both synthetic and real-world datasets compared to previous state-of-the-art methods.
TCLC-GS: Tightly Coupled LiDAR-Camera Gaussian Splatting for Surrounding Autonomous Driving Scenes
Apr 03, 2024Most 3D Gaussian Splatting (3D-GS) based methods for urban scenes initialize 3D Gaussians directly with 3D LiDAR points, which not only underutilizes LiDAR data capabilities but also overlooks the potential advantages of fusing LiDAR with camera data. In this paper, we design a novel tightly coupled LiDAR-Camera Gaussian Splatting (TCLC-GS) to fully leverage the combined strengths of both LiDAR and camera sensors, enabling rapid, high-quality 3D reconstruction and novel view RGB/depth synthesis. TCLC-GS designs a hybrid explicit (colorized 3D mesh) and implicit (hierarchical octree feature) 3D representation derived from LiDAR-camera data, to enrich the properties of 3D Gaussians for splatting. 3D Gaussian's properties are not only initialized in alignment with the 3D mesh which provides more completed 3D shape and color information, but are also endowed with broader contextual information through retrieved octree implicit features. During the Gaussian Splatting optimization process, the 3D mesh offers dense depth information as supervision, which enhances the training process by learning of a robust geometry. Comprehensive evaluations conducted on the Waymo Open Dataset and nuScenes Dataset validate our method's state-of-the-art (SOTA) performance. Utilizing a single NVIDIA RTX 3090 Ti, our method demonstrates fast training and achieves real-time RGB and depth rendering at 90 FPS in resolution of 1920x1280 (Waymo), and 120 FPS in resolution of 1600x900 (nuScenes) in urban scenarios.
Transfer learning applications for anomaly detection in wind turbines
Apr 03, 2024Anomaly detection in wind turbines typically involves using normal behaviour models to detect faults early. However, training autoencoder models for each turbine is time-consuming and resource intensive. Thus, transfer learning becomes essential for wind turbines with limited data or applications with limited computational resources. This study examines how cross-turbine transfer learning can be applied to autoencoder-based anomaly detection. Here, autoencoders are combined with constant thresholds for the reconstruction error to determine if input data contains an anomaly. The models are initially trained on one year's worth of data from one or more source wind turbines. They are then fine-tuned using smaller amounts of data from another turbine. Three methods for fine-tuning are investigated: adjusting the entire autoencoder, only the decoder, or only the threshold of the model. The performance of the transfer learning models is compared to baseline models that were trained on one year's worth of data from the target wind turbine. The results of the tests conducted in this study indicate that models trained on data of multiple wind turbines do not improve the anomaly detection capability compared to models trained on data of one source wind turbine. In addition, modifying the model's threshold can lead to comparable or even superior performance compared to the baseline, whereas fine-tuning the decoder or autoencoder further enhances the models' performance.
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Apr 03, 2024Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
HCTO: Optimality-Aware LiDAR Inertial Odometry with Hybrid Continuous Time Optimization for Compact Wearable Mapping System
Mar 21, 2024

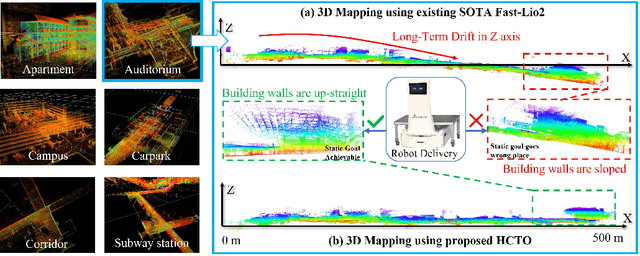
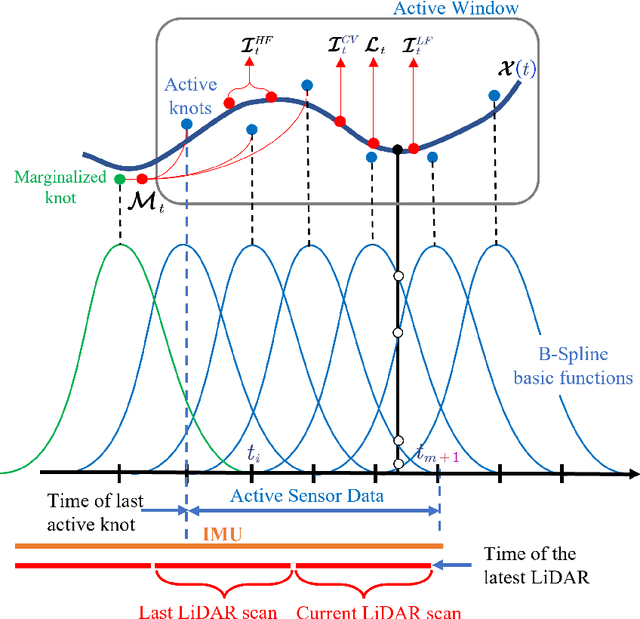
Compact wearable mapping system (WMS) has gained significant attention due to their convenience in various applications. Specifically, it provides an efficient way to collect prior maps for 3D structure inspection and robot-based "last-mile delivery" in complex environments. However, vibrations in human motion and the uneven distribution of point cloud features in complex environments often lead to rapid drift, which is a prevalent issue when applying existing LiDAR Inertial Odometry (LIO) methods on low-cost WMS. To address these limitations, we propose a novel LIO for WMSs based on Hybrid Continuous Time Optimization (HCTO) considering the optimality of Lidar correspondences. First, HCTO recognizes patterns in human motion (high-frequency part, low-frequency part, and constant velocity part) by analyzing raw IMU measurements. Second, HCTO constructs hybrid IMU factors according to different motion states, which enables robust and accurate estimation against vibration-induced noise in the IMU measurements. Third, the best point correspondences are selected using optimal design to achieve real-time performance and better odometry accuracy. We conduct experiments on head-mounted WMS datasets to evaluate the performance of our system, demonstrating significant advantages over state-of-the-art methods. Video recordings of experiments can be found on the project page of HCTO: \href{https://github.com/kafeiyin00/HCTO}{https://github.com/kafeiyin00/HCTO}.
Visual-inertial state estimation based on Chebyshev polynomial optimization
Apr 01, 2024This paper proposes an innovative state estimation method for visual-inertial fusion based on Chebyshev polynomial optimization. Specifically, the pose is modeled as a Chebyshev polynomial of a certain order, and its time derivatives are used to calculate linear acceleration and angular velocity, which, along with inertial measurements, constitute dynamic constraints. This is coupled with a visual measurement model to construct a visual-inertial bundle adjustment formulation. Simulation and public dataset experiments show that the proposed method has better accuracy than the discrete-form preintegration method.
Universal representations for financial transactional data: embracing local, global, and external contexts
Apr 02, 2024Effective processing of financial transactions is essential for banking data analysis. However, in this domain, most methods focus on specialized solutions to stand-alone problems instead of constructing universal representations suitable for many problems. We present a representation learning framework that addresses diverse business challenges. We also suggest novel generative models that account for data specifics, and a way to integrate external information into a client's representation, leveraging insights from other customers' actions. Finally, we offer a benchmark, describing representation quality globally, concerning the entire transaction history; locally, reflecting the client's current state; and dynamically, capturing representation evolution over time. Our generative approach demonstrates superior performance in local tasks, with an increase in ROC-AUC of up to 14\% for the next MCC prediction task and up to 46\% for downstream tasks from existing contrastive baselines. Incorporating external information improves the scores by an additional 20\%.
Learning-Based Joint Beamforming and Antenna Movement Design for Movable Antenna Systems
Apr 02, 2024In this paper, we investigate a multi-receiver communication system enabled by movable antennas (MAs). Specifically, the transmit beamforming and the double-side antenna movement at the transceiver are jointly designed to maximize the sum-rate of all receivers under imperfect channel state information (CSI). Since the formulated problem is non-convex with highly coupled variables, conventional optimization methods cannot solve it efficiently. To address these challenges, an effective learning-based algorithm is proposed, namely heterogeneous multi-agent deep deterministic policy gradient (MADDPG), which incorporates two agents to learn policies for beamforming and movement of MAs, respectively. Based on the offline learning under numerous imperfect CSI, the proposed heterogeneous MADDPG can output the solutions for transmit beamforming and antenna movement in real time. Simulation results validate the effectiveness of the proposed algorithm, and the MA can significantly improve the sum-rate performance of multiple receivers compared to other benchmark schemes.
Mapping the Increasing Use of LLMs in Scientific Papers
Apr 01, 2024Scientific publishing lays the foundation of science by disseminating research findings, fostering collaboration, encouraging reproducibility, and ensuring that scientific knowledge is accessible, verifiable, and built upon over time. Recently, there has been immense speculation about how many people are using large language models (LLMs) like ChatGPT in their academic writing, and to what extent this tool might have an effect on global scientific practices. However, we lack a precise measure of the proportion of academic writing substantially modified or produced by LLMs. To address this gap, we conduct the first systematic, large-scale analysis across 950,965 papers published between January 2020 and February 2024 on the arXiv, bioRxiv, and Nature portfolio journals, using a population-level statistical framework to measure the prevalence of LLM-modified content over time. Our statistical estimation operates on the corpus level and is more robust than inference on individual instances. Our findings reveal a steady increase in LLM usage, with the largest and fastest growth observed in Computer Science papers (up to 17.5%). In comparison, Mathematics papers and the Nature portfolio showed the least LLM modification (up to 6.3%). Moreover, at an aggregate level, our analysis reveals that higher levels of LLM-modification are associated with papers whose first authors post preprints more frequently, papers in more crowded research areas, and papers of shorter lengths. Our findings suggests that LLMs are being broadly used in scientific writings.
Caformer: Rethinking Time Series Analysis from Causal Perspective
Mar 13, 2024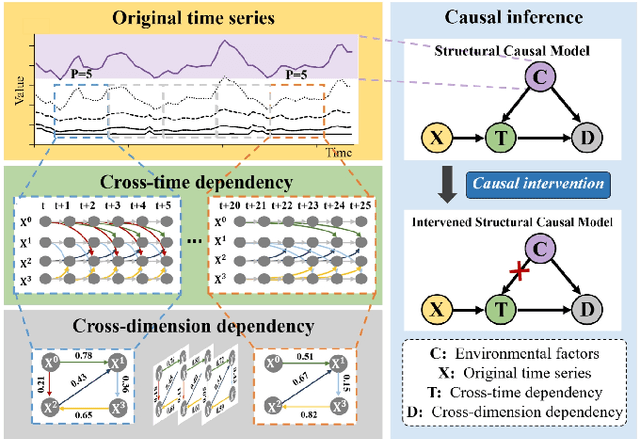
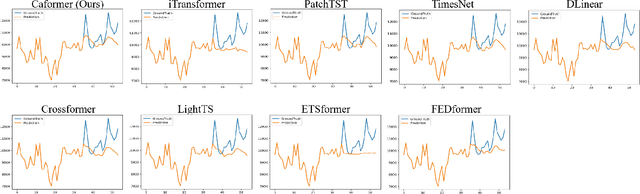
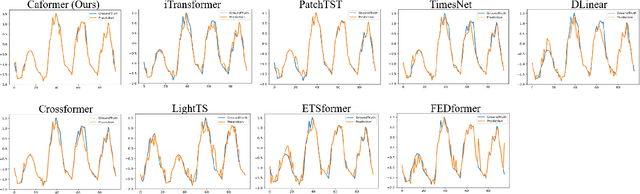
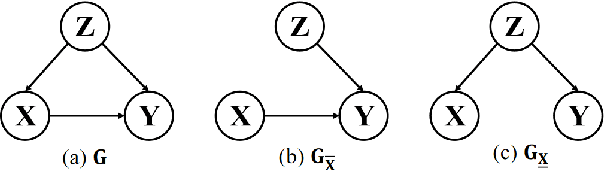
Time series analysis is a vital task with broad applications in various domains. However, effectively capturing cross-dimension and cross-time dependencies in non-stationary time series poses significant challenges, particularly in the context of environmental factors. The spurious correlation induced by the environment confounds the causal relationships between cross-dimension and cross-time dependencies. In this paper, we introduce a novel framework called Caformer (\underline{\textbf{Ca}}usal Trans\underline{\textbf{former}}) for time series analysis from a causal perspective. Specifically, our framework comprises three components: Dynamic Learner, Environment Learner, and Dependency Learner. The Dynamic Learner unveils dynamic interactions among dimensions, the Environment Learner mitigates spurious correlations caused by environment with a back-door adjustment, and the Dependency Learner aims to infer robust interactions across both time and dimensions. Our Caformer demonstrates consistent state-of-the-art performance across five mainstream time series analysis tasks, including long- and short-term forecasting, imputation, classification, and anomaly detection, with proper interpretability.