 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explaining Deep Learning Models for Age-related Gait Classification based on time series acceleration
Nov 28, 2023
Gait analysis holds significant importance in monitoring daily health, particularly among older adults. Advancements in sensor technology enable the capture of movement in real-life environments and generate big data. Machine learning, notably deep learning (DL), shows promise to use these big data in gait analysis. However, the inherent black-box nature of these models poses challenges for their clinical application. This study aims to enhance transparency in DL-based gait classification for aged-related gait patterns using Explainable Artificial Intelligence, such as SHAP. A total of 244 subjects, comprising 129 adults and 115 older adults (age>65), were included. They performed a 3-minute walking task while accelerometers were affixed to the lumbar segment L3. DL models, convolutional neural network (CNN) and gated recurrent unit (GRU), were trained using 1-stride and 8-stride accelerations, respectively, to classify adult and older adult groups. SHAP was employed to explain the models' predictions. CNN achieved a satisfactory performance with an accuracy of 81.4% and an AUC of 0.89, and GRU demonstrated promising results with an accuracy of 84.5% and an AUC of 0.94. SHAP analysis revealed that both CNN and GRU assigned higher SHAP values to the data from vertical and walking directions, particularly emphasizing data around heel contact, spanning from the terminal swing to loading response phases. Furthermore, SHAP values indicated that GRU did not treat every stride equally. CNN accurately distinguished between adults and older adults based on the characteristics of a single stride's data. GRU achieved accurate classification by considering the relationships and subtle differences between strides. In both models, data around heel contact emerged as most critical, suggesting differences in acceleration and deceleration patterns during walking between different age groups.
Efficient Toxic Content Detection by Bootstrapping and Distilling Large Language Models
Dec 13, 2023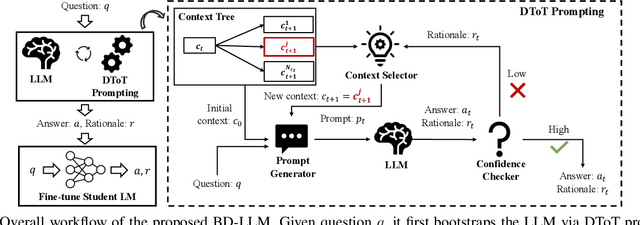
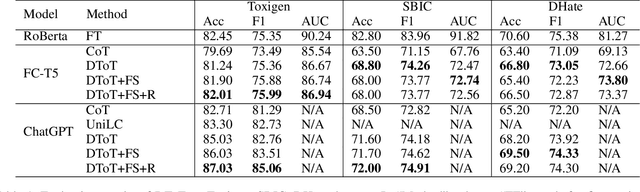
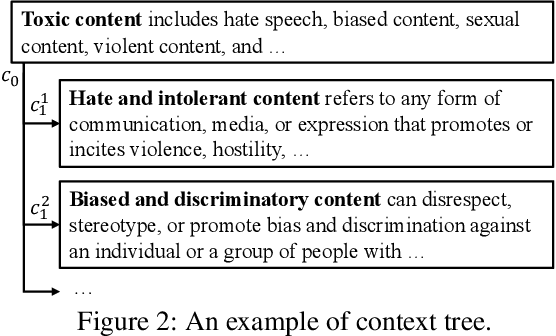
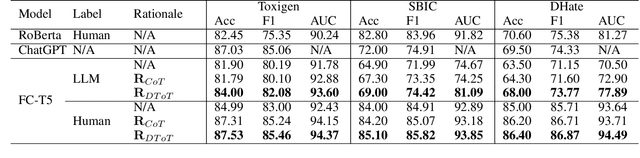
Toxic content detection is crucial for online services to remove inappropriate content that violates community standards. To automate the detection process, prior works have proposed varieties of machine learning (ML) approaches to train Language Models (LMs) for toxic content detection. However, both their accuracy and transferability across datasets are limited. Recently, Large Language Models (LLMs) have shown promise in toxic content detection due to their superior zero-shot and few-shot in-context learning ability as well as broad transferability on ML tasks. However, efficiently designing prompts for LLMs remains challenging. Moreover, the high run-time cost of LLMs may hinder their deployments in production. To address these challenges, in this work, we propose BD-LLM, a novel and efficient approach to Bootstrapping and Distilling LLMs for toxic content detection. Specifically, we design a novel prompting method named Decision-Tree-of-Thought (DToT) to bootstrap LLMs' detection performance and extract high-quality rationales. DToT can automatically select more fine-grained context to re-prompt LLMs when their responses lack confidence. Additionally, we use the rationales extracted via DToT to fine-tune student LMs. Our experimental results on various datasets demonstrate that DToT can improve the accuracy of LLMs by up to 4.6%. Furthermore, student LMs fine-tuned with rationales extracted via DToT outperform baselines on all datasets with up to 16.9\% accuracy improvement, while being more than 60x smaller than conventional LLMs. Finally, we observe that student LMs fine-tuned with rationales exhibit better cross-dataset transferability.
Design and Control of an Energy Accumulative Hopping Robot
Dec 13, 2023Jumping and hopping locomotion are efficient means of traversing unstructured rugged terrain with the former being the focus of roboticists. This focus has led to significant performance and understanding in jumping robots but with limited practical applications as they require significant time between jumps to store energy, thus relegating jumping to a secondary role in locomotion. Hopping locomotion, however, can preserve and transfer energy to subsequent hops without long energy storage periods. Therefore, hopping has the potential to be far more energy efficient and agile than jumping. However, to date, only a single untethered hopping robot exists with limited payload and hopping heights (< 1 meter). This is due to the added design and control complexity inherent in the requirements to input energy during dynamic locomotion and control the orientation of the system throughout the hopping cycle, resulting in low energy input and control torques; a redevelopment from basic principles is necessary to advance the capabilities of hopping robots. Here we report hopping robot design principles for efficient and robust systems with high energy input and control torques that are validated through analytical, simulation, and experimental results. The resulting robot (MultiMo-MHR) can hop nearly 4 meters (> 6 times the current state-of-the-art); and is only limited by the impact mechanics and not energy input. The results also directly contradict a recent work that concluded hopping with aerodynamic energy input would be less efficient than flight for hops greater than 0.4 meters.
Robust and Performance Incentivizing Algorithms for Multi-Armed Bandits with Strategic Agents
Dec 13, 2023We consider a variant of the stochastic multi-armed bandit problem. Specifically, the arms are strategic agents who can improve their rewards or absorb them. The utility of an agent increases if she is pulled more or absorbs more of her rewards but decreases if she spends more effort improving her rewards. Agents have heterogeneous properties, specifically having different means and able to improve their rewards up to different levels. Further, a non-empty subset of agents are ''honest'' and in the worst case always give their rewards without absorbing any part. The principal wishes to obtain a high revenue (cumulative reward) by designing a mechanism that incentives top level performance at equilibrium. At the same time, the principal wishes to be robust and obtain revenue at least at the level of the honest agent with the highest mean in case of non-equilibrium behaviour. We identify a class of MAB algorithms which we call performance incentivizing which satisfy a collection of properties and show that they lead to mechanisms that incentivize top level performance at equilibrium and are robust under any strategy profile. Interestingly, we show that UCB is an example of such a MAB algorithm. Further, in the case where the top performance level is unknown we show that combining second price auction ideas with performance incentivizing algorithms achieves performance at least at the second top level while also being robust.
Foundation Models in Robotics: Applications, Challenges, and the Future
Dec 13, 2023
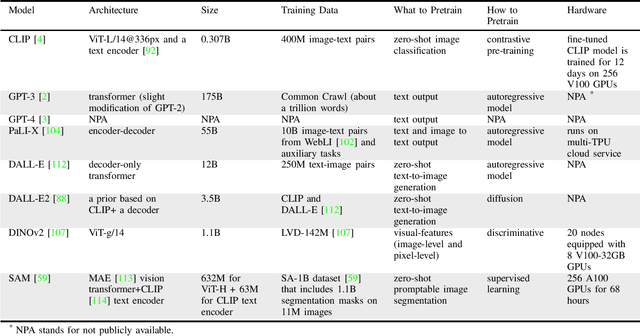
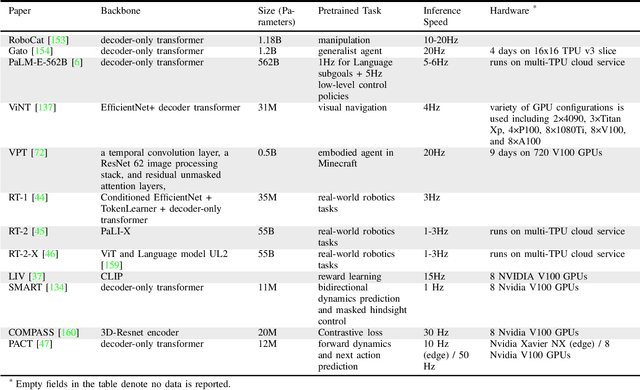
We survey applications of pretrained foundation models in robotics. Traditional deep learning models in robotics are trained on small datasets tailored for specific tasks, which limits their adaptability across diverse applications. In contrast, foundation models pretrained on internet-scale data appear to have superior generalization capabilities, and in some instances display an emergent ability to find zero-shot solutions to problems that are not present in the training data. Foundation models may hold the potential to enhance various components of the robot autonomy stack, from perception to decision-making and control. For example, large language models can generate code or provide common sense reasoning, while vision-language models enable open-vocabulary visual recognition. However, significant open research challenges remain, particularly around the scarcity of robot-relevant training data, safety guarantees and uncertainty quantification, and real-time execution. In this survey, we study recent papers that have used or built foundation models to solve robotics problems. We explore how foundation models contribute to improving robot capabilities in the domains of perception, decision-making, and control. We discuss the challenges hindering the adoption of foundation models in robot autonomy and provide opportunities and potential pathways for future advancements. The GitHub project corresponding to this paper (Preliminary release. We are committed to further enhancing and updating this work to ensure its quality and relevance) can be found here: https://github.com/robotics-survey/Awesome-Robotics-Foundation-Models
EmbAu: A Novel Technique to Embed Audio Data Using Shuffled Frog Leaping Algorithm
Dec 13, 2023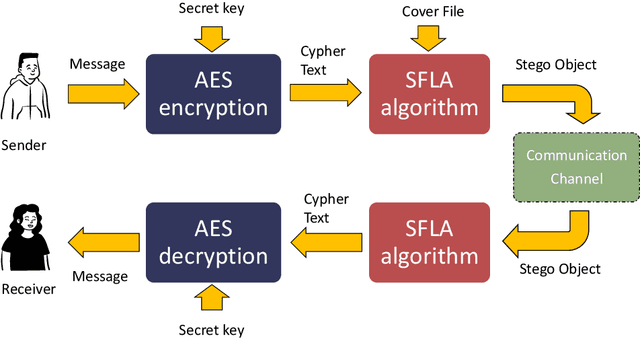



The aim of steganographic algorithms is to identify the appropriate pixel positions in the host or cover image, where bits of sensitive information can be concealed for data encryption. Work is being done to improve the capacity to integrate sensitive information and to maintain the visual appearance of the steganographic image. Consequently, steganography is a challenging research area. In our currently proposed image steganographic technique, we used the Shuffled Frog Leaping Algorithm (SFLA) to determine the order of pixels by which sensitive information can be placed in the cover image. To achieve greater embedding capacity, pixels from the spatial domain of the cover image are carefully chosen and used for placing the sensitive data. Bolstered via image steganography, the final image after embedding is resistant to steganalytic attacks. The SFLA algorithm serves in the optimal pixels selection of any colored (RGB) cover image for secret bit embedding. Using the fitness function, the SFLA benefits by reaching a minimum cost value in an acceptable amount of time. The pixels for embedding are meticulously chosen to minimize the host image's distortion upon embedding. Moreover, an effort has been taken to make the detection of embedded data in the steganographic image a formidable challenge. Due to the enormous need for audio data encryption in the current world, we feel that our suggested method has significant potential in real-world applications. In this paper, we propose and compare our strategy to existing steganographic methods.
On the Dynamics Under the Unhinged Loss and Beyond
Dec 13, 2023Recent works have studied implicit biases in deep learning, especially the behavior of last-layer features and classifier weights. However, they usually need to simplify the intermediate dynamics under gradient flow or gradient descent due to the intractability of loss functions and model architectures. In this paper, we introduce the unhinged loss, a concise loss function, that offers more mathematical opportunities to analyze the closed-form dynamics while requiring as few simplifications or assumptions as possible. The unhinged loss allows for considering more practical techniques, such as time-vary learning rates and feature normalization. Based on the layer-peeled model that views last-layer features as free optimization variables, we conduct a thorough analysis in the unconstrained, regularized, and spherical constrained cases, as well as the case where the neural tangent kernel remains invariant. To bridge the performance of the unhinged loss to that of Cross-Entropy (CE), we investigate the scenario of fixing classifier weights with a specific structure, (e.g., a simplex equiangular tight frame). Our analysis shows that these dynamics converge exponentially fast to a solution depending on the initialization of features and classifier weights. These theoretical results not only offer valuable insights, including explicit feature regularization and rescaled learning rates for enhancing practical training with the unhinged loss, but also extend their applicability to other loss functions. Finally, we empirically demonstrate these theoretical results and insights through extensive experiments.
Minimizing Robot Digging Times to Retrieve Bins in Robotic-Based Compact Storage and Retrieval Systems
Dec 08, 2023Robotic-based compact storage and retrieval systems provide high-density storage in distribution center and warehouse applications. In the system, items are stored in bins, and the bins are organized inside a three-dimensional grid. Robots move on top of the grid to retrieve and deliver bins. To retrieve a bin, a robot removes all bins above one by one with its gripper, called bin digging. The closer the target bin is to the top of the grid, the less digging is required to retrieve the bin. In this paper, we propose a policy to optimally arrange the bins in the grid while processing bin requests so that the most frequently accessed bins remain near the top of the grid. This improves the performance of the system and makes it responsive to changes in bin demand. Our solution approach identifies the optimal bin arrangement in the storage facility, initiates a transition to this optimal set-up, and subsequently ensures the ongoing maintenance of this arrangement for optimal performance. We perform extensive simulations on a custom-built discrete event model of the system. Our simulation results show that under the proposed policy more than half of the bins requested are located on top of the grid, reducing bin digging compared to existing policies. Compared to existing approaches, the proposed policy reduces the retrieval time of the requested bins by over 30% and the number of bin requests that exceed certain time thresholds by nearly 50%.
High-Resolution Maps of Left Atrial Displacements and Strains Estimated with 3D CINE MRI and Unsupervised Neural Networks
Dec 14, 2023The functional analysis of the left atrium (LA) is important for evaluating cardiac health and understanding diseases like atrial fibrillation. Cine MRI is ideally placed for the detailed 3D characterisation of LA motion and deformation, but it is lacking appropriate acquisition and analysis tools. In this paper, we present Analysis for Left Atrial Displacements and Deformations using unsupervIsed neural Networks, \textit{Aladdin}, to automatically and reliably characterise regional LA deformations from high-resolution 3D Cine MRI. The tool includes: an online few-shot segmentation network (Aladdin-S), an online unsupervised image registration network (Aladdin-R), and a strain calculations pipeline tailored to the LA. We create maps of LA Displacement Vector Field (DVF) magnitude and LA principal strain values from images of 10 healthy volunteers and 8 patients with cardiovascular disease (CVD). We additionally create an atlas of these biomarkers using the data from the healthy volunteers. Aladdin is able to accurately track the LA wall across the cardiac cycle and characterize its motion and deformation. The overall DVF magnitude and principal strain values are significantly higher in the healthy group vs CVD patients: $2.85 \pm 1.59~mm$ and $0.09 \pm 0.05$ vs $1.96 \pm 0.74~mm$ and $0.03 \pm 0.04$, respectively. The time course of these metrics is also different in the two groups, with a more marked active contraction phase observed in the healthy cohort. Finally, utilizing the LA atlas allows us to identify regional deviations from the population distribution that may indicate focal tissue abnormalities. The proposed tool for the quantification of novel regional LA deformation biomarkers should have important clinical applications. The source code, anonymized images, generated maps and atlas are publicly available: https://github.com/cgalaz01/aladdin_cmr_la.
Twitter Permeability to financial events: an experiment towards a model for sensing irregularities
Dec 14, 2023There is a general consensus of the good sensing and novelty characteristics of Twitter as an information media for the complex financial market. This paper investigates the permeability of Twittersphere, the total universe of Twitter users and their habits, towards relevant events in the financial market. Analysis shows that a general purpose social media is permeable to financial-specific events and establishes Twitter as a relevant feeder for taking decisions regarding the financial market and event fraudulent activities in that market. However, the provenance of contributions, their different levels of credibility and quality and even the purpose or intention behind them should to be considered and carefully contemplated if Twitter is used as a single source for decision taking. With the overall aim of this research, to deploy an architecture for real-time monitoring of irregularities in the financial market, this paper conducts a series of experiments on the level of permeability and the permeable features of Twitter in the event of one of these irregularities. To be precise, Twitter data is collected concerning an event comprising of a specific financial action on the 27th January 2017:{~ }the announcement about the merge of two companies Tesco PLC and Booker Group PLC, listed in the main market of the London Stock Exchange (LSE), to create the UK's Leading Food Business. The experiment attempts to answer five key research questions which aim to characterize the features of Twitter permeability to the financial market. The experimental results confirm that a far-impacting financial event, such as the merger considered, caused apparent disturbances in all the features considered, that is, information volume, content and sentiment as well as geographical provenance. Analysis shows that despite, Twitter not being a specific financial forum, it is permeable to financial events.