 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
From Text to Motion: Grounding GPT-4 in a Humanoid Robot "Alter3"
Dec 11, 2023
We report the development of Alter3, a humanoid robot capable of generating spontaneous motion using a Large Language Model (LLM), specifically GPT-4. This achievement was realized by integrating GPT-4 into our proprietary android, Alter3, thereby effectively grounding the LLM with Alter's bodily movement. Typically, low-level robot control is hardware-dependent and falls outside the scope of LLM corpora, presenting challenges for direct LLM-based robot control. However, in the case of humanoid robots like Alter3, direct control is feasible by mapping the linguistic expressions of human actions onto the robot's body through program code. Remarkably, this approach enables Alter3 to adopt various poses, such as a 'selfie' stance or 'pretending to be a ghost,' and generate sequences of actions over time without explicit programming for each body part. This demonstrates the robot's zero-shot learning capabilities. Additionally, verbal feedback can adjust poses, obviating the need for fine-tuning. A video of Alter3's generated motions is available at https://tnoinkwms.github.io/ALTER-LLM/
Achelous++: Power-Oriented Water-Surface Panoptic Perception Framework on Edge Devices based on Vision-Radar Fusion and Pruning of Heterogeneous Modalities
Dec 14, 2023Urban water-surface robust perception serves as the foundation for intelligent monitoring of aquatic environments and the autonomous navigation and operation of unmanned vessels, especially in the context of waterway safety. It is worth noting that current multi-sensor fusion and multi-task learning models consume substantial power and heavily rely on high-power GPUs for inference. This contributes to increased carbon emissions, a concern that runs counter to the prevailing emphasis on environmental preservation and the pursuit of sustainable, low-carbon urban environments. In light of these concerns, this paper concentrates on low-power, lightweight, multi-task panoptic perception through the fusion of visual and 4D radar data, which is seen as a promising low-cost perception method. We propose a framework named Achelous++ that facilitates the development and comprehensive evaluation of multi-task water-surface panoptic perception models. Achelous++ can simultaneously execute five perception tasks with high speed and low power consumption, including object detection, object semantic segmentation, drivable-area segmentation, waterline segmentation, and radar point cloud semantic segmentation. Furthermore, to meet the demand for developers to customize models for real-time inference on low-performance devices, a novel multi-modal pruning strategy known as Heterogeneous-Aware SynFlow (HA-SynFlow) is proposed. Besides, Achelous++ also supports random pruning at initialization with different layer-wise sparsity, such as Uniform and Erdos-Renyi-Kernel (ERK). Overall, our Achelous++ framework achieves state-of-the-art performance on the WaterScenes benchmark, excelling in both accuracy and power efficiency compared to other single-task and multi-task models. We release and maintain the code at https://github.com/GuanRunwei/Achelous.
Dietary Assessment with Multimodal ChatGPT: A Systematic Analysis
Dec 14, 2023Conventional approaches to dietary assessment are primarily grounded in self-reporting methods or structured interviews conducted under the supervision of dietitians. These methods, however, are often subjective, potentially inaccurate, and time-intensive. Although artificial intelligence (AI)-based solutions have been devised to automate the dietary assessment process, these prior AI methodologies encounter challenges in their ability to generalize across a diverse range of food types, dietary behaviors, and cultural contexts. This results in AI applications in the dietary field that possess a narrow specialization and limited accuracy. Recently, the emergence of multimodal foundation models such as GPT-4V powering the latest ChatGPT has exhibited transformative potential across a wide range of tasks (e.g., Scene understanding and image captioning) in numerous research domains. These models have demonstrated remarkable generalist intelligence and accuracy, capable of processing various data modalities. In this study, we explore the application of multimodal ChatGPT within the realm of dietary assessment. Our findings reveal that GPT-4V excels in food detection under challenging conditions with accuracy up to 87.5% without any fine-tuning or adaptation using food-specific datasets. By guiding the model with specific language prompts (e.g., African cuisine), it shifts from recognizing common staples like rice and bread to accurately identifying regional dishes like banku and ugali. Another GPT-4V's standout feature is its contextual awareness. GPT-4V can leverage surrounding objects as scale references to deduce the portion sizes of food items, further enhancing its accuracy in translating food weight into nutritional content. This alignment with the USDA National Nutrient Database underscores GPT-4V's potential to advance nutritional science and dietary assessment techniques.
One-dimensional Convolutional Neural Networks for Detecting Transiting Exoplanets
Dec 12, 2023The transit method is one of the most relevant exoplanet detection techniques, which consists of detecting periodic eclipses in the light curves of stars. This is not always easy due to the presence of noise in the light curves, which is induced, for example, by the response of a telescope to stellar flux. For this reason, we aimed to develop an artificial neural network model that is able to detect these transits in light curves obtained from different telescopes and surveys. We created artificial light curves with and without transits to try to mimic those expected for the extended mission of the Kepler telescope (K2) in order to train and validate a 1D convolutional neural network model, which was later tested, obtaining an accuracy of 99.02 % and an estimated error (loss function) of 0.03. These results, among others, helped to confirm that the 1D CNN is a good choice for working with non-phased-folded Mandel and Agol light curves with transits. It also reduces the number of light curves that have to be visually inspected to decide if they present transit-like signals and decreases the time needed for analyzing each (with respect to traditional analysis).
DiffuVST: Narrating Fictional Scenes with Global-History-Guided Denoising Models
Dec 12, 2023Recent advances in image and video creation, especially AI-based image synthesis, have led to the production of numerous visual scenes that exhibit a high level of abstractness and diversity. Consequently, Visual Storytelling (VST), a task that involves generating meaningful and coherent narratives from a collection of images, has become even more challenging and is increasingly desired beyond real-world imagery. While existing VST techniques, which typically use autoregressive decoders, have made significant progress, they suffer from low inference speed and are not well-suited for synthetic scenes. To this end, we propose a novel diffusion-based system DiffuVST, which models the generation of a series of visual descriptions as a single conditional denoising process. The stochastic and non-autoregressive nature of DiffuVST at inference time allows it to generate highly diverse narratives more efficiently. In addition, DiffuVST features a unique design with bi-directional text history guidance and multimodal adapter modules, which effectively improve inter-sentence coherence and image-to-text fidelity. Extensive experiments on the story generation task covering four fictional visual-story datasets demonstrate the superiority of DiffuVST over traditional autoregressive models in terms of both text quality and inference speed.
May the Noise be with you: Adversarial Training without Adversarial Examples
Dec 12, 2023In this paper, we investigate the following question: Can we obtain adversarially-trained models without training on adversarial examples? Our intuition is that training a model with inherent stochasticity, i.e., optimizing the parameters by minimizing a stochastic loss function, yields a robust expectation function that is non-stochastic. In contrast to related methods that introduce noise at the input level, our proposed approach incorporates inherent stochasticity by embedding Gaussian noise within the layers of the NN model at training time. We model the propagation of noise through the layers, introducing a closed-form stochastic loss function that encapsulates a noise variance parameter. Additionally, we contribute a formalized noise-aware gradient, enabling the optimization of model parameters while accounting for stochasticity. Our experimental results confirm that the expectation model of a stochastic architecture trained on benign distribution is adversarially robust. Interestingly, we find that the impact of the applied Gaussian noise's standard deviation on both robustness and baseline accuracy closely mirrors the impact of the noise magnitude employed in adversarial training. Our work contributes adversarially trained networks using a completely different approach, with empirically similar robustness to adversarial training.
MedYOLO: A Medical Image Object Detection Framework
Dec 12, 2023Artificial intelligence-enhanced identification of organs, lesions, and other structures in medical imaging is typically done using convolutional neural networks (CNNs) designed to make voxel-accurate segmentations of the region of interest. However, the labels required to train these CNNs are time-consuming to generate and require attention from subject matter experts to ensure quality. For tasks where voxel-level precision is not required, object detection models offer a viable alternative that can reduce annotation effort. Despite this potential application, there are few options for general purpose object detection frameworks available for 3-D medical imaging. We report on MedYOLO, a 3-D object detection framework using the one-shot detection method of the YOLO family of models and designed for use with medical imaging. We tested this model on four different datasets: BRaTS, LIDC, an abdominal organ Computed Tomography (CT) dataset, and an ECG-gated heart CT dataset. We found our models achieve high performance on commonly present medium and large-sized structures such as the heart, liver, and pancreas even without hyperparameter tuning. However, the models struggle with very small or rarely present structures.
High-density Electromyography for Effective Gesture-based Control of Physically Assistive Mobile Manipulators
Dec 12, 2023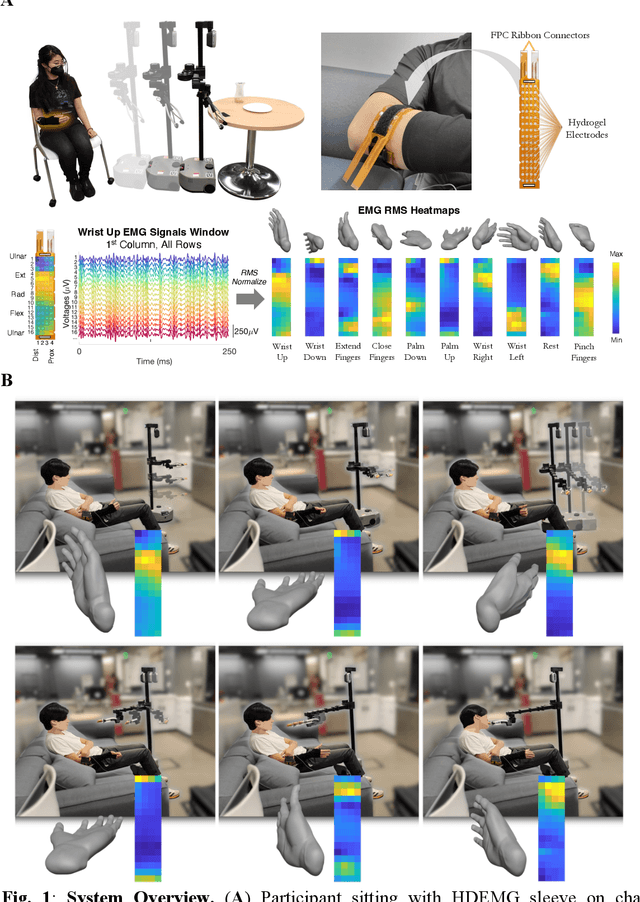
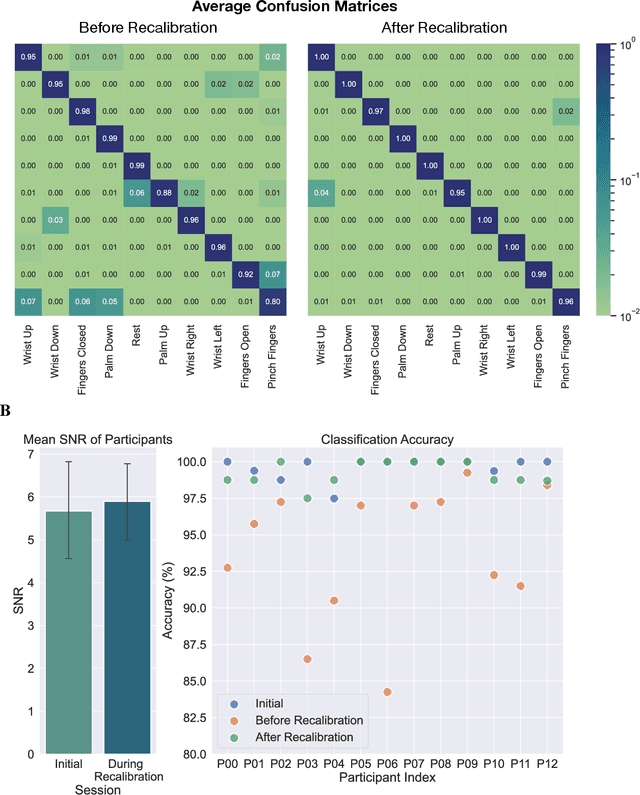
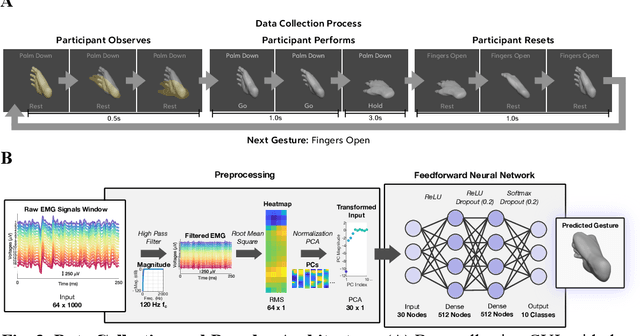
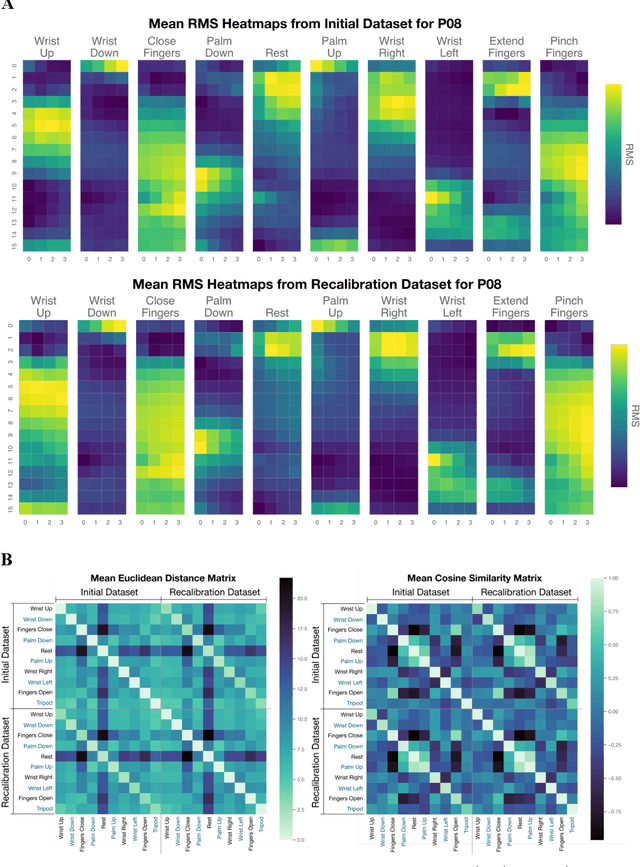
Injury to the cervical spinal cord can cause quadriplegia, impairing muscle function in all four limbs. People with impaired hand function and mobility encounter significant difficulties in carrying out essential self-care and household tasks. Despite the impairment of their neural drive, their volitional myoelectric activity is often partially preserved. High-density electromyography (HDEMG) can detect this myoelectric activity, which can serve as control inputs to assistive devices. Previous HDEMG-controlled robotic interfaces have primarily been limited to controlling table-mounted robot arms. These have constrained reach capabilities. Instead, the ability to control mobile manipulators, which have no such workspace constraints, could allow individuals with quadriplegia to perform a greater variety of assistive tasks, thus restoring independence and reducing caregiver workload. In this study, we introduce a non-invasive wearable HDEMG interface with real-time myoelectric hand gesture recognition, enabling both coarse and fine control over the intricate mobility and manipulation functionalities of an 8 degree-of-freedom mobile manipulator. Our evaluation, involving 13 participants engaging in challenging self-care and household activities, demonstrates the potential of our wearable HDEMG system to profoundly enhance user independence by enabling non-invasive control of a mobile manipulator.
Sensor Fusion and Resource Management in MIMO-OFDM Joint Sensing and Communication
Dec 12, 2023This study explores the promising potential of integrating sensing capabilities into multiple-input multiple-output (MIMO)-orthogonal frequency division multiplexing (OFDM)-based networks through innovative multi-sensor fusion techniques, tracking algorithms, and resource management. A novel data fusion technique is proposed within the MIMO-OFDM system, which promotes cooperative sensing among monostatic joint sensing and communication (JSC) base stations by sharing range-angle maps with a central fusion center. To manage data sharing and control network overhead introduced by cooperation, an excision filter is introduced at each base station. After data fusion, the framework employs a three-step clustering procedure combined with a tracking algorithm to effectively handle point-like and extended targets. Delving into the sensing/communication trade-off, resources such as transmit power, frequency, and time are varied, providing valuable insights into their impact on the overall system performance. Additionally, a sophisticated channel model is proposed, accounting for complex urban propagation scenarios and addressing multipath effects and multiple reflection points for extended targets like vehicles. Evaluation metrics, including optimal sub-pattern assignment (OSPA), downlink sum rate, and bit rate, offer a comprehensive assessment of the system's localization and communication capabilities, as well as network overhead.
READ-PVLA: Recurrent Adapter with Partial Video-Language Alignment for Parameter-Efficient Transfer Learning in Low-Resource Video-Language Modeling
Dec 12, 2023
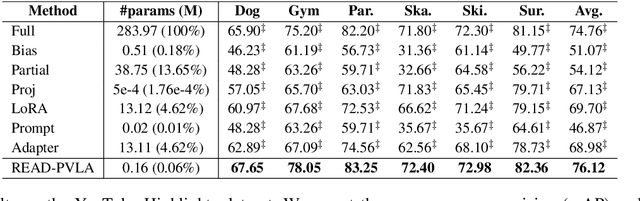
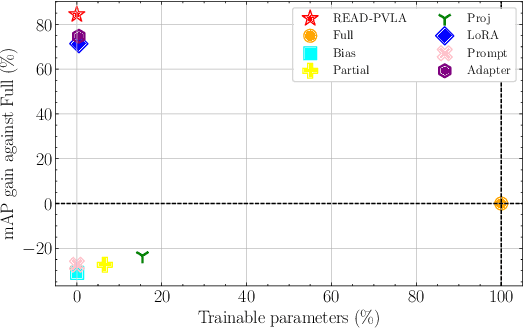
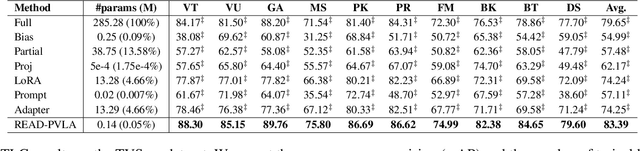
Fully fine-tuning pretrained large-scale transformer models has become a popular paradigm for video-language modeling tasks, such as temporal language grounding and video-language summarization. With a growing number of tasks and limited training data, such full fine-tuning approach leads to costly model storage and unstable training. To overcome these shortcomings, we introduce lightweight adapters to the pre-trained model and only update them at fine-tuning time. However, existing adapters fail to capture intrinsic temporal relations among video frames or textual words. Moreover, they neglect the preservation of critical task-related information that flows from the raw video-language input into the adapter's low-dimensional space. To address these issues, we first propose a novel REcurrent ADapter (READ) that employs recurrent computation to enable temporal modeling capability. Second, we propose Partial Video-Language Alignment (PVLA) objective via the use of partial optimal transport to maintain task-related information flowing into our READ modules. We validate our READ-PVLA framework through extensive experiments where READ-PVLA significantly outperforms all existing fine-tuning strategies on multiple low-resource temporal language grounding and video-language summarization benchmarks.