 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine learning-based decentralized TDMA for VLC IoT networks
Nov 27, 2023
In this paper, a machine learning-based decentralized time division multiple access (TDMA) algorithm for visible light communication (VLC) Internet of Things (IoT) networks is proposed. The proposed algorithm is based on Q-learning, a reinforcement learning algorithm. This paper considers a decentralized condition in which there is no coordinator node for sending synchronization frames and assigning transmission time slots to other nodes. The proposed algorithm uses a decentralized manner for synchronization, and each node uses the Q-learning algorithm to find the optimal transmission time slot for sending data without collisions. The proposed algorithm is implemented on a VLC hardware system, which had been designed and implemented in our laboratory. Average reward, convergence time, goodput, average delay, and data packet size are evaluated parameters. The results show that the proposed algorithm converges quickly and provides collision-free decentralized TDMA for the network. The proposed algorithm is compared with carrier-sense multiple access with collision avoidance (CSMA/CA) algorithm as a potential selection for decentralized VLC IoT networks. The results show that the proposed algorithm provides up to 61% more goodput and up to 49% less average delay than CSMA/CA.
Novel Models for Multiple Dependent Heteroskedastic Time Series
Oct 26, 2023Functional magnetic resonance imaging or functional MRI (fMRI) is a very popular tool used for differing brain regions by measuring brain activity. It is affected by physiological noise, such as head and brain movement in the scanner from breathing, heart beats, or the subject fidgeting. The purpose of this paper is to propose a novel approach to handling fMRI data for infants with high volatility caused by sudden head movements. Another purpose is to evaluate the volatility modelling performance of multiple dependent fMRI time series data. The models examined in this paper are AR and GARCH and the modelling performance is evaluated by several statistical performance measures. The conclusions of this paper are that multiple dependent fMRI series data can be fitted with AR + GARCH model if the multiple fMRI data have many sudden head movements. The GARCH model can capture the shared volatility clustering caused by head movements across brain regions. However, the multiple fMRI data without many head movements have fitted AR + GARCH model with different performance. The conclusions are supported by statistical tests and measures. This paper highlights the difference between the proposed approach from traditional approaches when estimating model parameters and modelling conditional variances on multiple dependent time series. In the future, the proposed approach can be applied to other research fields, such as financial economics, and signal processing. Code is available at \url{https://github.com/13204942/STAT40710}.
Onflow: an online portfolio allocation algorithm
Dec 08, 2023We introduce Onflow, a reinforcement learning technique that enables online optimization of portfolio allocation policies based on gradient flows. We devise dynamic allocations of an investment portfolio to maximize its expected log return while taking into account transaction fees. The portfolio allocation is parameterized through a softmax function, and at each time step, the gradient flow method leads to an ordinary differential equation whose solutions correspond to the updated allocations. This algorithm belongs to the large class of stochastic optimization procedures; we measure its efficiency by comparing our results to the mathematical theoretical values in a log-normal framework and to standard benchmarks from the 'old NYSE' dataset. For log-normal assets, the strategy learned by Onflow, with transaction costs at zero, mimics Markowitz's optimal portfolio and thus the best possible asset allocation strategy. Numerical experiments from the 'old NYSE' dataset show that Onflow leads to dynamic asset allocation strategies whose performances are: a) comparable to benchmark strategies such as Cover's Universal Portfolio or Helmbold et al. "multiplicative updates" approach when transaction costs are zero, and b) better than previous procedures when transaction costs are high. Onflow can even remain efficient in regimes where other dynamical allocation techniques do not work anymore. Therefore, as far as tested, Onflow appears to be a promising dynamic portfolio management strategy based on observed prices only and without any assumption on the laws of distributions of the underlying assets' returns. In particular it could avoid model risk when building a trading strategy.
TypeFly: Flying Drones with Large Language Model
Dec 08, 2023Commanding a drone with a natural language is not only user-friendly but also opens the door for emerging language agents to control the drone. Emerging large language models (LLMs) provide a previously impossible opportunity to automatically translate a task description in a natural language to a program that can be executed by the drone. However, powerful LLMs and their vision counterparts are limited in three important ways. First, they are only available as cloud-based services. Sending images to the cloud raises privacy concerns. Second, they are expensive, costing proportionally to the request size. Finally, without expensive fine-tuning, existing LLMs are quite limited in their capability of writing a program for specialized systems like drones. In this paper, we present a system called TypeFly that tackles the above three problems using a combination of edge-based vision intelligence, novel programming language design, and prompt engineering. Instead of the familiar Python, TypeFly gets a cloud-based LLM service to write a program in a small, custom language called MiniSpec, based on task and scene descriptions in English. Such MiniSpec programs are not only succinct (and therefore efficient) but also able to consult the LLM during their execution using a special skill called query. Using a set of increasingly challenging drone tasks, we show that design choices made by TypeFly can reduce both the cost of LLM service and the task execution time by more than 2x. More importantly, query and prompt engineering techniques contributed by TypeFly significantly improve the chance of success of complex tasks.
3D Copy-Paste: Physically Plausible Object Insertion for Monocular 3D Detection
Dec 08, 2023

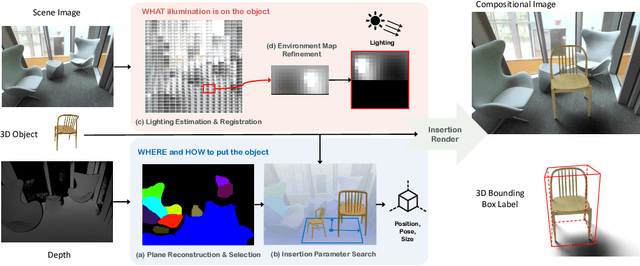

A major challenge in monocular 3D object detection is the limited diversity and quantity of objects in real datasets. While augmenting real scenes with virtual objects holds promise to improve both the diversity and quantity of the objects, it remains elusive due to the lack of an effective 3D object insertion method in complex real captured scenes. In this work, we study augmenting complex real indoor scenes with virtual objects for monocular 3D object detection. The main challenge is to automatically identify plausible physical properties for virtual assets (e.g., locations, appearances, sizes, etc.) in cluttered real scenes. To address this challenge, we propose a physically plausible indoor 3D object insertion approach to automatically copy virtual objects and paste them into real scenes. The resulting objects in scenes have 3D bounding boxes with plausible physical locations and appearances. In particular, our method first identifies physically feasible locations and poses for the inserted objects to prevent collisions with the existing room layout. Subsequently, it estimates spatially-varying illumination for the insertion location, enabling the immersive blending of the virtual objects into the original scene with plausible appearances and cast shadows. We show that our augmentation method significantly improves existing monocular 3D object models and achieves state-of-the-art performance. For the first time, we demonstrate that a physically plausible 3D object insertion, serving as a generative data augmentation technique, can lead to significant improvements for discriminative downstream tasks such as monocular 3D object detection. Project website: https://gyhandy.github.io/3D-Copy-Paste/
Efficient Test-Time Adaptation for Super-Resolution with Second-Order Degradation and Reconstruction
Oct 29, 2023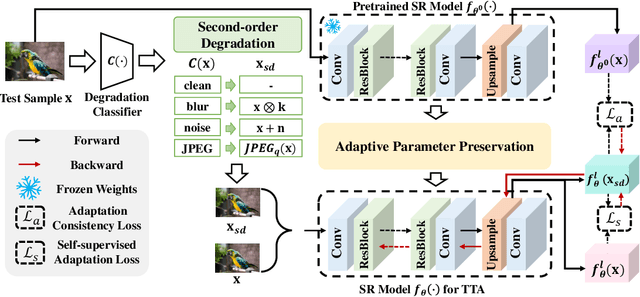
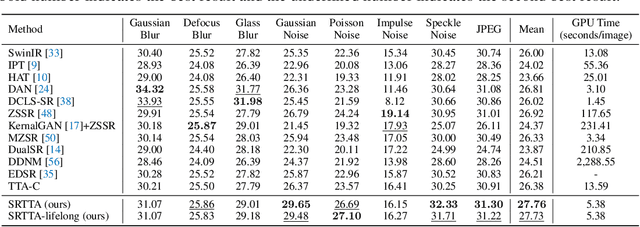

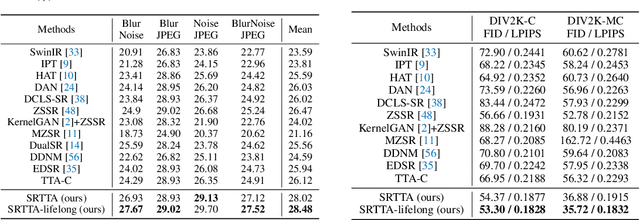
Image super-resolution (SR) aims to learn a mapping from low-resolution (LR) to high-resolution (HR) using paired HR-LR training images. Conventional SR methods typically gather the paired training data by synthesizing LR images from HR images using a predetermined degradation model, e.g., Bicubic down-sampling. However, the realistic degradation type of test images may mismatch with the training-time degradation type due to the dynamic changes of the real-world scenarios, resulting in inferior-quality SR images. To address this, existing methods attempt to estimate the degradation model and train an image-specific model, which, however, is quite time-consuming and impracticable to handle rapidly changing domain shifts. Moreover, these methods largely concentrate on the estimation of one degradation type (e.g., blur degradation), overlooking other degradation types like noise and JPEG in real-world test-time scenarios, thus limiting their practicality. To tackle these problems, we present an efficient test-time adaptation framework for SR, named SRTTA, which is able to quickly adapt SR models to test domains with different/unknown degradation types. Specifically, we design a second-order degradation scheme to construct paired data based on the degradation type of the test image, which is predicted by a pre-trained degradation classifier. Then, we adapt the SR model by implementing feature-level reconstruction learning from the initial test image to its second-order degraded counterparts, which helps the SR model generate plausible HR images. Extensive experiments are conducted on newly synthesized corrupted DIV2K datasets with 8 different degradations and several real-world datasets, demonstrating that our SRTTA framework achieves an impressive improvement over existing methods with satisfying speed. The source code is available at https://github.com/DengZeshuai/SRTTA.
Diffusion Posterior Sampling for Nonlinear CT Reconstruction
Dec 03, 2023Diffusion models have been demonstrated as powerful deep learning tools for image generation in CT reconstruction and restoration. Recently, diffusion posterior sampling, where a score-based diffusion prior is combined with a likelihood model, has been used to produce high quality CT images given low-quality measurements. This technique is attractive since it permits a one-time, unsupervised training of a CT prior; which can then be incorporated with an arbitrary data model. However, current methods only rely on a linear model of x-ray CT physics to reconstruct or restore images. While it is common to linearize the transmission tomography reconstruction problem, this is an approximation to the true and inherently nonlinear forward model. We propose a new method that solves the inverse problem of nonlinear CT image reconstruction via diffusion posterior sampling. We implement a traditional unconditional diffusion model by training a prior score function estimator, and apply Bayes rule to combine this prior with a measurement likelihood score function derived from the nonlinear physical model to arrive at a posterior score function that can be used to sample the reverse-time diffusion process. This plug-and-play method allows incorporation of a diffusion-based prior with generalized nonlinear CT image reconstruction into multiple CT system designs with different forward models, without the need for any additional training. We develop the algorithm that performs this reconstruction, including an ordered-subsets variant for accelerated processing and demonstrate the technique in both fully sampled low dose data and sparse-view geometries using a single unsupervised training of the prior.
STF: Spatial Temporal Fusion for Trajectory Prediction
Nov 29, 2023Trajectory prediction is a challenging task that aims to predict the future trajectory of vehicles or pedestrians over a short time horizon based on their historical positions. The main reason is that the trajectory is a kind of complex data, including spatial and temporal information, which is crucial for accurate prediction. Intuitively, the more information the model can capture, the more precise the future trajectory can be predicted. However, previous works based on deep learning methods processed spatial and temporal information separately, leading to inadequate spatial information capture, which means they failed to capture the complete spatial information. Therefore, it is of significance to capture information more fully and effectively on vehicle interactions. In this study, we introduced an integrated 3D graph that incorporates both spatial and temporal edges. Based on this, we proposed the integrated 3D graph, which considers the cross-time interaction information. In specific, we design a Spatial-Temporal Fusion (STF) model including Multi-layer perceptions (MLP) and Graph Attention (GAT) to capture the spatial and temporal information historical trajectories simultaneously on the 3D graph. Our experiment on the ApolloScape Trajectory Datasets shows that the proposed STF outperforms several baseline methods, especially on the long-time-horizon trajectory prediction.
Data-Driven Shape Sensing in Continuum Manipulators via Sliding Resistive Flex Sensors
Nov 29, 2023We introduce a novel shape-sensing method using Resistive Flex Sensors (RFS) embedded in cable-driven Continuum Dexterous Manipulators (CDMs). The RFS is predominantly sensitive to deformation rather than direct forces, making it a distinctive tool for shape sensing. The RFS unit we designed is a considerably less expensive and robust alternative, offering comparable accuracy and real-time performance to existing shape sensing methods used for the CDMs proposed for minimally-invasive surgery. Our design allows the RFS to move along and inside the CDM conforming to its curvature, offering the ability to capture resistance metrics from various bending positions without the need for elaborate sensor setups. The RFS unit is calibrated using an overhead camera and a ResNet machine learning framework. Experiments using a 3D printed prototype of the CDM achieved an average shape estimation error of 0.968 mm with a standard error of 0.275 mm. The response time of the model was approximately 1.16 ms, making real-time shape sensing feasible. While this preliminary study successfully showed the feasibility of our approach for C-shape CDM deformations with non-constant curvatures, we are currently extending the results to show the feasibility for adapting to more complex CDM configurations such as S-shape created in obstructed environments or in presence of the external forces.
Synergistic Perception and Control Simplex for Verifiable Safe Vertical Landing
Dec 05, 2023Perception, Planning, and Control form the essential components of autonomy in advanced air mobility. This work advances the holistic integration of these components to enhance the performance and robustness of the complete cyber-physical system. We adapt Perception Simplex, a system for verifiable collision avoidance amidst obstacle detection faults, to the vertical landing maneuver for autonomous air mobility vehicles. We improve upon this system by replacing static assumptions of control capabilities with dynamic confirmation, i.e., real-time confirmation of control limitations of the system, ensuring reliable fulfillment of safety maneuvers and overrides, without dependence on overly pessimistic assumptions. Parameters defining control system capabilities and limitations, e.g., maximum deceleration, are continuously tracked within the system and used to make safety-critical decisions. We apply these techniques to propose a verifiable collision avoidance solution for autonomous aerial mobility vehicles operating in cluttered and potentially unsafe environments.