 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Novel Sector-Based Algorithm for an Optimized Star-Galaxy Classification
Apr 01, 2024
This paper introduces a novel sector-based methodology for star-galaxy classification, leveraging the latest Sloan Digital Sky Survey data (SDSS-DR18). By strategically segmenting the sky into sectors aligned with SDSS observational patterns and employing a dedicated convolutional neural network (CNN), we achieve state-of-the-art performance for star galaxy classification. Our preliminary results demonstrate a promising pathway for efficient and precise astronomical analysis, especially in real-time observational settings.
TCLC-GS: Tightly Coupled LiDAR-Camera Gaussian Splatting for Surrounding Autonomous Driving Scenes
Apr 03, 2024Most 3D Gaussian Splatting (3D-GS) based methods for urban scenes initialize 3D Gaussians directly with 3D LiDAR points, which not only underutilizes LiDAR data capabilities but also overlooks the potential advantages of fusing LiDAR with camera data. In this paper, we design a novel tightly coupled LiDAR-Camera Gaussian Splatting (TCLC-GS) to fully leverage the combined strengths of both LiDAR and camera sensors, enabling rapid, high-quality 3D reconstruction and novel view RGB/depth synthesis. TCLC-GS designs a hybrid explicit (colorized 3D mesh) and implicit (hierarchical octree feature) 3D representation derived from LiDAR-camera data, to enrich the properties of 3D Gaussians for splatting. 3D Gaussian's properties are not only initialized in alignment with the 3D mesh which provides more completed 3D shape and color information, but are also endowed with broader contextual information through retrieved octree implicit features. During the Gaussian Splatting optimization process, the 3D mesh offers dense depth information as supervision, which enhances the training process by learning of a robust geometry. Comprehensive evaluations conducted on the Waymo Open Dataset and nuScenes Dataset validate our method's state-of-the-art (SOTA) performance. Utilizing a single NVIDIA RTX 3090 Ti, our method demonstrates fast training and achieves real-time RGB and depth rendering at 90 FPS in resolution of 1920x1280 (Waymo), and 120 FPS in resolution of 1600x900 (nuScenes) in urban scenarios.
Transfer learning applications for anomaly detection in wind turbines
Apr 03, 2024Anomaly detection in wind turbines typically involves using normal behaviour models to detect faults early. However, training autoencoder models for each turbine is time-consuming and resource intensive. Thus, transfer learning becomes essential for wind turbines with limited data or applications with limited computational resources. This study examines how cross-turbine transfer learning can be applied to autoencoder-based anomaly detection. Here, autoencoders are combined with constant thresholds for the reconstruction error to determine if input data contains an anomaly. The models are initially trained on one year's worth of data from one or more source wind turbines. They are then fine-tuned using smaller amounts of data from another turbine. Three methods for fine-tuning are investigated: adjusting the entire autoencoder, only the decoder, or only the threshold of the model. The performance of the transfer learning models is compared to baseline models that were trained on one year's worth of data from the target wind turbine. The results of the tests conducted in this study indicate that models trained on data of multiple wind turbines do not improve the anomaly detection capability compared to models trained on data of one source wind turbine. In addition, modifying the model's threshold can lead to comparable or even superior performance compared to the baseline, whereas fine-tuning the decoder or autoencoder further enhances the models' performance.
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Apr 03, 2024Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
Affective-NLI: Towards Accurate and Interpretable Personality Recognition in Conversation
Apr 03, 2024Personality Recognition in Conversation (PRC) aims to identify the personality traits of speakers through textual dialogue content. It is essential for providing personalized services in various applications of Human-Computer Interaction (HCI), such as AI-based mental therapy and companion robots for the elderly. Most recent studies analyze the dialog content for personality classification yet overlook two major concerns that hinder their performance. First, crucial implicit factors contained in conversation, such as emotions that reflect the speakers' personalities are ignored. Second, only focusing on the input dialog content disregards the semantic understanding of personality itself, which reduces the interpretability of the results. In this paper, we propose Affective Natural Language Inference (Affective-NLI) for accurate and interpretable PRC. To utilize affectivity within dialog content for accurate personality recognition, we fine-tuned a pre-trained language model specifically for emotion recognition in conversations, facilitating real-time affective annotations for utterances. For interpretability of recognition results, we formulate personality recognition as an NLI problem by determining whether the textual description of personality labels is entailed by the dialog content. Extensive experiments on two daily conversation datasets suggest that Affective-NLI significantly outperforms (by 6%-7%) state-of-the-art approaches. Additionally, our Flow experiment demonstrates that Affective-NLI can accurately recognize the speaker's personality in the early stages of conversations by surpassing state-of-the-art methods with 22%-34%.
DUQGen: Effective Unsupervised Domain Adaptation of Neural Rankers by Diversifying Synthetic Query Generation
Apr 03, 2024State-of-the-art neural rankers pre-trained on large task-specific training data such as MS-MARCO, have been shown to exhibit strong performance on various ranking tasks without domain adaptation, also called zero-shot. However, zero-shot neural ranking may be sub-optimal, as it does not take advantage of the target domain information. Unfortunately, acquiring sufficiently large and high quality target training data to improve a modern neural ranker can be costly and time-consuming. To address this problem, we propose a new approach to unsupervised domain adaptation for ranking, DUQGen, which addresses a critical gap in prior literature, namely how to automatically generate both effective and diverse synthetic training data to fine tune a modern neural ranker for a new domain. Specifically, DUQGen produces a more effective representation of the target domain by identifying clusters of similar documents; and generates a more diverse training dataset by probabilistic sampling over the resulting document clusters. Our extensive experiments, over the standard BEIR collection, demonstrate that DUQGen consistently outperforms all zero-shot baselines and substantially outperforms the SOTA baselines on 16 out of 18 datasets, for an average of 4% relative improvement across all datasets. We complement our results with a thorough analysis for more in-depth understanding of the proposed method's performance and to identify promising areas for further improvements.
TSNet:A Two-stage Network for Image Dehazing with Multi-scale Fusion and Adaptive Learning
Apr 03, 2024Image dehazing has been a popular topic of research for a long time. Previous deep learning-based image dehazing methods have failed to achieve satisfactory dehazing effects on both synthetic datasets and real-world datasets, exhibiting poor generalization. Moreover, single-stage networks often result in many regions with artifacts and color distortion in output images. To address these issues, this paper proposes a two-stage image dehazing network called TSNet, mainly consisting of the multi-scale fusion module (MSFM) and the adaptive learning module (ALM). Specifically, MSFM and ALM enhance the generalization of TSNet. The MSFM can obtain large receptive fields at multiple scales and integrate features at different frequencies to reduce the differences between inputs and learning objectives. The ALM can actively learn of regions of interest in images and restore texture details more effectively. Additionally, TSNet is designed as a two-stage network, where the first-stage network performs image dehazing, and the second-stage network is employed to improve issues such as artifacts and color distortion present in the results of the first-stage network. We also change the learning objective from ground truth images to opposite fog maps, which improves the learning efficiency of TSNet. Extensive experiments demonstrate that TSNet exhibits superior dehazing performance on both synthetic and real-world datasets compared to previous state-of-the-art methods.
Advancing multivariate time series similarity assessment: an integrated computational approach
Mar 16, 2024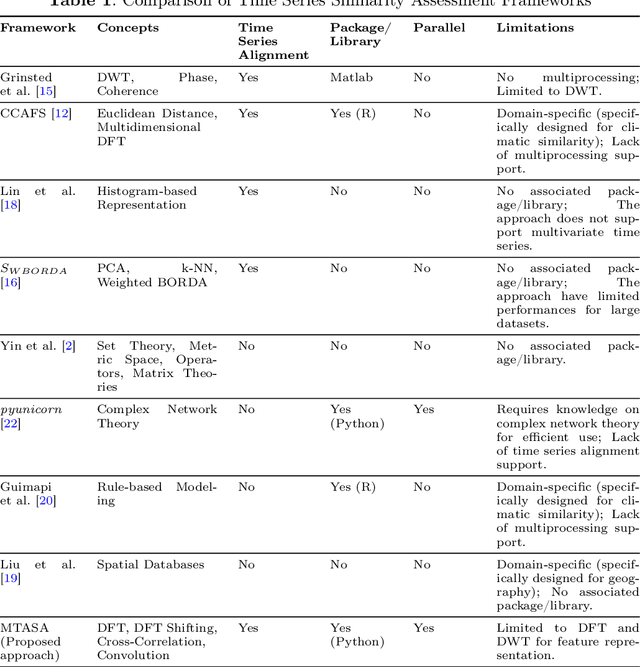
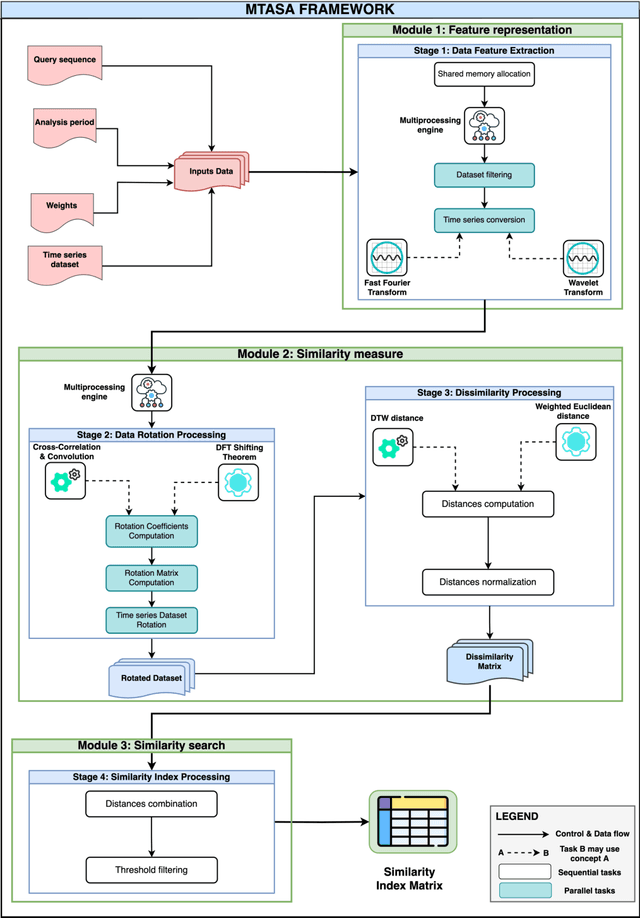
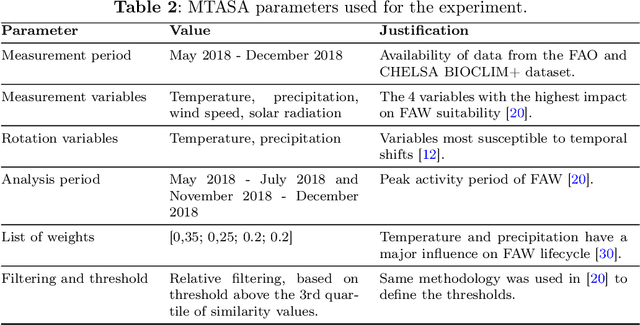
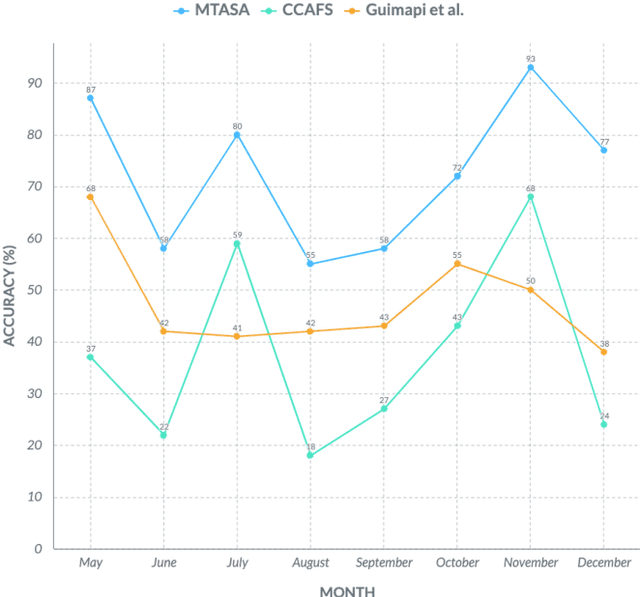
Data mining, particularly the analysis of multivariate time series data, plays a crucial role in extracting insights from complex systems and supporting informed decision-making across diverse domains. However, assessing the similarity of multivariate time series data presents several challenges, including dealing with large datasets, addressing temporal misalignments, and the need for efficient and comprehensive analytical frameworks. To address all these challenges, we propose a novel integrated computational approach known as Multivariate Time series Alignment and Similarity Assessment (MTASA). MTASA is built upon a hybrid methodology designed to optimize time series alignment, complemented by a multiprocessing engine that enhances the utilization of computational resources. This integrated approach comprises four key components, each addressing essential aspects of time series similarity assessment, thereby offering a comprehensive framework for analysis. MTASA is implemented as an open-source Python library with a user-friendly interface, making it accessible to researchers and practitioners. To evaluate the effectiveness of MTASA, we conducted an empirical study focused on assessing agroecosystem similarity using real-world environmental data. The results from this study highlight MTASA's superiority, achieving approximately 1.5 times greater accuracy and twice the speed compared to existing state-of-the-art integrated frameworks for multivariate time series similarity assessment. It is hoped that MTASA will significantly enhance the efficiency and accessibility of multivariate time series analysis, benefitting researchers and practitioners across various domains. Its capabilities in handling large datasets, addressing temporal misalignments, and delivering accurate results make MTASA a valuable tool for deriving insights and aiding decision-making processes in complex systems.
LAN: Learning Adaptive Neighbors for Real-Time Insider Threat Detection
Mar 17, 2024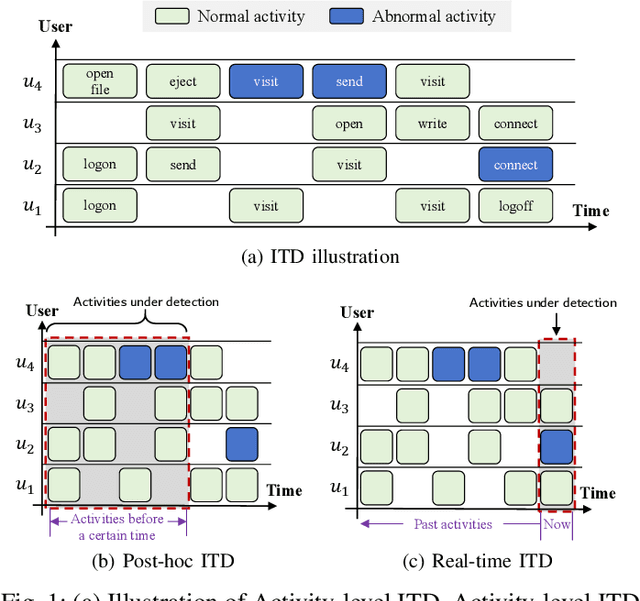
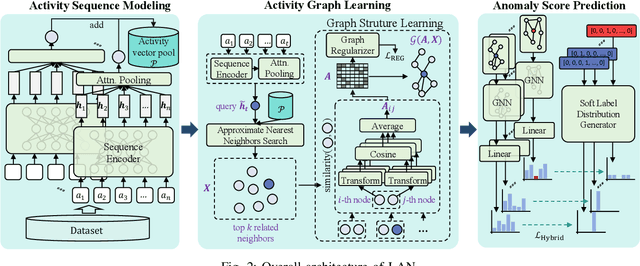
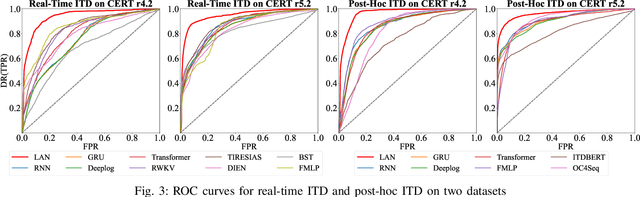
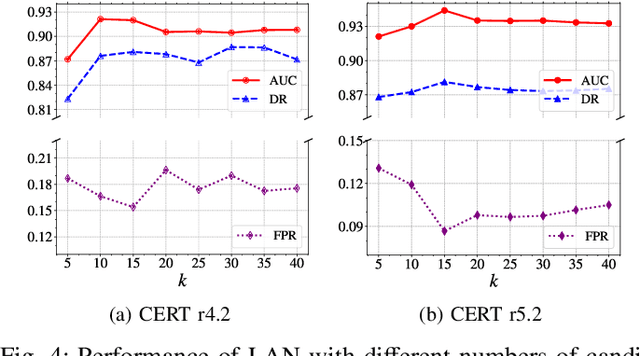
Enterprises and organizations are faced with potential threats from insider employees that may lead to serious consequences. Previous studies on insider threat detection (ITD) mainly focus on detecting abnormal users or abnormal time periods (e.g., a week or a day). However, a user may have hundreds of thousands of activities in the log, and even within a day there may exist thousands of activities for a user, requiring a high investigation budget to verify abnormal users or activities given the detection results. On the other hand, existing works are mainly post-hoc methods rather than real-time detection, which can not report insider threats in time before they cause loss. In this paper, we conduct the first study towards real-time ITD at activity level, and present a fine-grained and efficient framework LAN. Specifically, LAN simultaneously learns the temporal dependencies within an activity sequence and the relationships between activities across sequences with graph structure learning. Moreover, to mitigate the data imbalance problem in ITD, we propose a novel hybrid prediction loss, which integrates self-supervision signals from normal activities and supervision signals from abnormal activities into a unified loss for anomaly detection. We evaluate the performance of LAN on two widely used datasets, i.e., CERT r4.2 and CERT r5.2. Extensive and comparative experiments demonstrate the superiority of LAN, outperforming 9 state-of-the-art baselines by at least 9.92% and 6.35% in AUC for real-time ITD on CERT r4.2 and r5.2, respectively. Moreover, LAN can be also applied to post-hoc ITD, surpassing 8 competitive baselines by at least 7.70% and 4.03% in AUC on two datasets. Finally, the ablation study, parameter analysis, and compatibility analysis evaluate the impact of each module and hyper-parameter in LAN. The source code can be obtained from https://github.com/Li1Neo/LAN.
Visual-inertial state estimation based on Chebyshev polynomial optimization
Apr 01, 2024This paper proposes an innovative state estimation method for visual-inertial fusion based on Chebyshev polynomial optimization. Specifically, the pose is modeled as a Chebyshev polynomial of a certain order, and its time derivatives are used to calculate linear acceleration and angular velocity, which, along with inertial measurements, constitute dynamic constraints. This is coupled with a visual measurement model to construct a visual-inertial bundle adjustment formulation. Simulation and public dataset experiments show that the proposed method has better accuracy than the discrete-form preintegration method.