 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards A Flexible Accuracy-Oriented Deep Learning Module Inference Latency Prediction Framework for Adaptive Optimization Algorithms
Dec 11, 2023
With the rapid development of Deep Learning, more and more applications on the cloud and edge tend to utilize large DNN (Deep Neural Network) models for improved task execution efficiency as well as decision-making quality. Due to memory constraints, models are commonly optimized using compression, pruning, and partitioning algorithms to become deployable onto resource-constrained devices. As the conditions in the computational platform change dynamically, the deployed optimization algorithms should accordingly adapt their solutions. To perform frequent evaluations of these solutions in a timely fashion, RMs (Regression Models) are commonly trained to predict the relevant solution quality metrics, such as the resulted DNN module inference latency, which is the focus of this paper. Existing prediction frameworks specify different RM training workflows, but none of them allow flexible configurations of the input parameters (e.g., batch size, device utilization rate) and of the selected RMs for different modules. In this paper, a deep learning module inference latency prediction framework is proposed, which i) hosts a set of customizable input parameters to train multiple different RMs per DNN module (e.g., convolutional layer) with self-generated datasets, and ii) automatically selects a set of trained RMs leading to the highest possible overall prediction accuracy, while keeping the prediction time / space consumption as low as possible. Furthermore, a new RM, namely MEDN (Multi-task Encoder-Decoder Network), is proposed as an alternative solution. Comprehensive experiment results show that MEDN is fast and lightweight, and capable of achieving the highest overall prediction accuracy and R-squared value. The Time/Space-efficient Auto-selection algorithm also manages to improve the overall accuracy by 2.5% and R-squared by 0.39%, compared to the MEDN single-selection scheme.
Contact-Implicit MPC: Controlling Diverse Quadruped Motions Without Pre-Planned Contact Modes or Trajectories
Dec 14, 2023
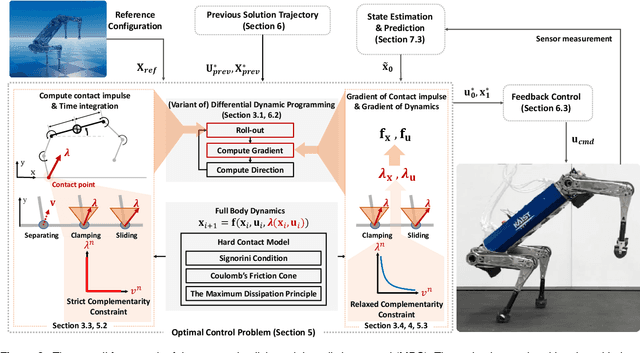
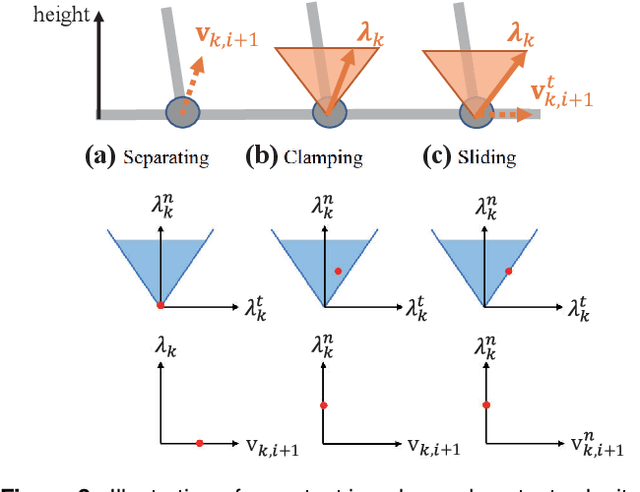
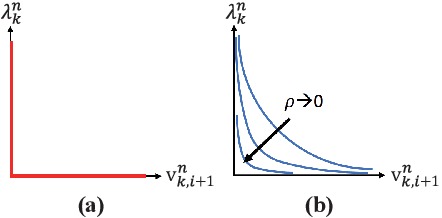
This paper presents a contact-implicit model predictive control (MPC) framework for the real-time discovery of multi-contact motions, without predefined contact mode sequences or foothold positions. This approach utilizes the contact-implicit differential dynamic programming (DDP) framework, merging the hard contact model with a linear complementarity constraint. We propose the analytical gradient of the contact impulse based on relaxed complementarity constraints to further the exploration of a variety of contact modes. By leveraging a hard contact model-based simulation and computation of search direction through a smooth gradient, our methodology identifies dynamically feasible state trajectories, control inputs, and contact forces while simultaneously unveiling new contact mode sequences. However, the broadened scope of contact modes does not always ensure real-world applicability. Recognizing this, we implemented differentiable cost terms to guide foot trajectories and make gait patterns. Furthermore, to address the challenge of unstable initial roll-outs in an MPC setting, we employ the multiple shooting variant of DDP. The efficacy of the proposed framework is validated through simulations and real-world demonstrations using a 45 kg HOUND quadruped robot, performing various tasks in simulation and showcasing actual experiments involving a forward trot and a front-leg rearing motion.
UCMCTrack: Multi-Object Tracking with Uniform Camera Motion Compensation
Dec 14, 2023Multi-object tracking (MOT) in video sequences remains a challenging task, especially in scenarios with significant camera movements. This is because targets can drift considerably on the image plane, leading to erroneous tracking outcomes. Addressing such challenges typically requires supplementary appearance cues or Camera Motion Compensation (CMC). While these strategies are effective, they also introduce a considerable computational burden, posing challenges for real-time MOT. In response to this, we introduce UCMCTrack, a novel motion model-based tracker robust to camera movements. Unlike conventional CMC that computes compensation parameters frame-by-frame, UCMCTrack consistently applies the same compensation parameters throughout a video sequence. It employs a Kalman filter on the ground plane and introduces the Mapped Mahalanobis Distance (MMD) as an alternative to the traditional Intersection over Union (IoU) distance measure. By leveraging projected probability distributions on the ground plane, our approach efficiently captures motion patterns and adeptly manages uncertainties introduced by homography projections. Remarkably, UCMCTrack, relying solely on motion cues, achieves state-of-the-art performance across a variety of challenging datasets, including MOT17, MOT20, DanceTrack and KITTI, with an exceptional speed of over 1000 FPS on a single CPU. More details and code are available at https://github.com/corfyi/UCMCTrack
Panel Transitions for Genre Analysis in Visual Narratives
Dec 14, 2023Understanding how humans communicate and perceive narratives is important for media technology research and development. This is particularly important in current times when there are tools and algorithms that are easily available for amateur users to create high-quality content. Narrative media develops over time a set of recognizable patterns of features across similar artifacts. Genre is one such grouping of artifacts for narrative media with similar patterns, tropes, and story structures. While much work has been done on genre-based classifications in text and video, we present a novel approach to do a multi-modal analysis of genre based on comics and manga-style visual narratives. We present a systematic feature analysis of an annotated dataset that includes a variety of western and eastern visual books with annotations for high-level narrative patterns. We then present a detailed analysis of the contributions of high-level features to genre classification for this medium. We highlight some of the limitations and challenges of our existing computational approaches in modeling subjective labels. Our contributions to the community are: a dataset of annotated manga books, a multi-modal analysis of visual panels and text in a constrained and popular medium through high-level features, and a systematic process for incorporating subjective narrative patterns in computational models.
Optimizing Likelihood-free Inference using Self-supervised Neural Symmetry Embeddings
Dec 11, 2023Likelihood-free inference is quickly emerging as a powerful tool to perform fast/effective parameter estimation. We demonstrate a technique of optimizing likelihood-free inference to make it even faster by marginalizing symmetries in a physical problem. In this approach, physical symmetries, for example, time-translation are learned using joint-embedding via self-supervised learning with symmetry data augmentations. Subsequently, parameter inference is performed using a normalizing flow where the embedding network is used to summarize the data before conditioning the parameters. We present this approach on two simple physical problems and we show faster convergence in a smaller number of parameters compared to a normalizing flow that does not use a pre-trained symmetry-informed representation.
Cross-codex Learning for Reliable Scribe Identification in Medieval Manuscripts
Dec 07, 2023Historic scribe identification is a substantial task for obtaining information about the past. Uniform script styles, such as the Carolingian minuscule, make it a difficult task for classification to focus on meaningful features. Therefore, we demonstrate in this paper the importance of cross-codex training data for CNN based text-independent off-line scribe identification, to overcome codex dependent overfitting. We report three main findings: First, we found that preprocessing with masked grayscale images instead of RGB images clearly increased the F1-score of the classification results. Second, we trained different neural networks on our complex data, validating time and accuracy differences in order to define the most reliable network architecture. With AlexNet, the network with the best trade-off between F1-score and time, we achieved for individual classes F1-scores of up to 0,96 on line level and up to 1.0 on page level in classification. Third, we could replicate the finding that the CNN output can be further improved by implementing a reject option, giving more stable results. We present the results on our large scale open source dataset -- the Codex Claustroneoburgensis database (CCl-DB) -- containing a significant number of writings from different scribes in several codices. We demonstrate for the first time on a dataset with such a variety of codices that paleographic decisions can be reproduced automatically and precisely with CNNs. This gives manifold new and fast possibilities for paleographers to gain insights into unlabeled material, but also to develop further hypotheses.
Wavelength-multiplexed Delayed Inputs for Memory Enhancement of Microring-based Reservoir Computing
Dec 07, 2023We numerically demonstrate a silicon add-drop microring-based reservoir computing scheme that combines parallel delayed inputs and wavelength division multiplexing. The scheme solves memory-demanding tasks like time-series prediction with good performance without requiring external optical feedback.
Noise Adaptor in Spiking Neural Networks
Dec 08, 2023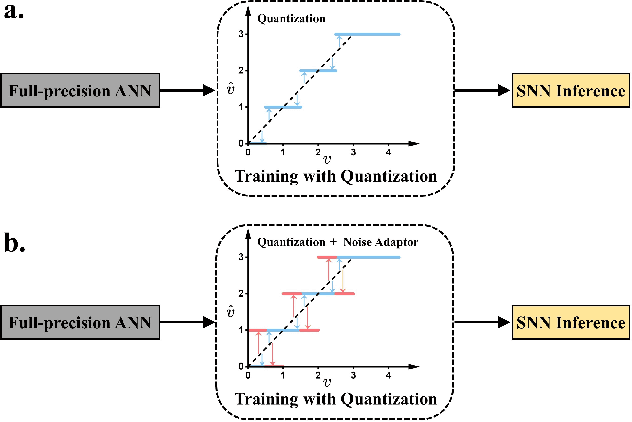
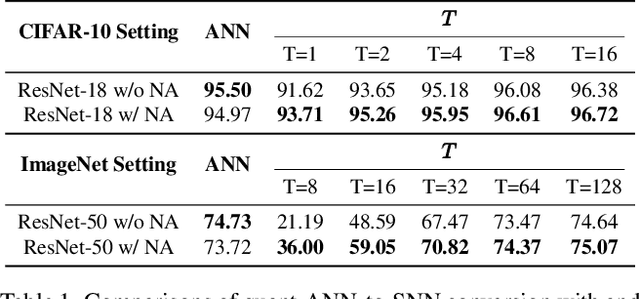
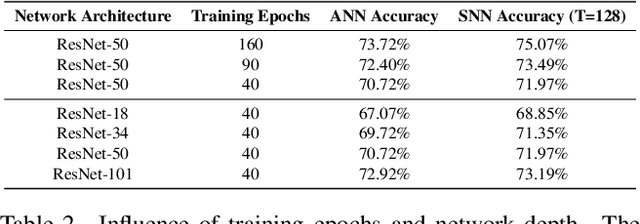
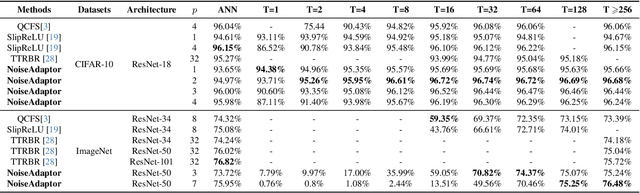
Recent strides in low-latency spiking neural network (SNN) algorithms have drawn significant interest, particularly due to their event-driven computing nature and fast inference capability. One of the most efficient ways to construct a low-latency SNN is by converting a pre-trained, low-bit artificial neural network (ANN) into an SNN. However, this conversion process faces two main challenges: First, converting SNNs from low-bit ANNs can lead to ``occasional noise" -- the phenomenon where occasional spikes are generated in spiking neurons where they should not be -- during inference, which significantly lowers SNN accuracy. Second, although low-latency SNNs initially show fast improvements in accuracy with time steps, these accuracy growths soon plateau, resulting in their peak accuracy lagging behind both full-precision ANNs and traditional ``long-latency SNNs'' that prioritize precision over speed. In response to these two challenges, this paper introduces a novel technique named ``noise adaptor.'' Noise adaptor can model occasional noise during training and implicitly optimize SNN accuracy, particularly at high simulation times $T$. Our research utilizes the ResNet model for a comprehensive analysis of the impact of the noise adaptor on low-latency SNNs. The results demonstrate that our method outperforms the previously reported quant-ANN-to-SNN conversion technique. We achieved an accuracy of 95.95\% within 4 time steps on CIFAR-10 using ResNet-18, and an accuracy of 74.37\% within 64 time steps on ImageNet using ResNet-50. Remarkably, these results were obtained without resorting to any noise correction methods during SNN inference, such as negative spikes or two-stage SNN simulations. Our approach significantly boosts the peak accuracy of low-latency SNNs, bringing them on par with the accuracy of full-precision ANNs. Code will be open source.
Test-time Augmentation for Factual Probing
Oct 26, 2023Factual probing is a method that uses prompts to test if a language model "knows" certain world knowledge facts. A problem in factual probing is that small changes to the prompt can lead to large changes in model output. Previous work aimed to alleviate this problem by optimizing prompts via text mining or fine-tuning. However, such approaches are relation-specific and do not generalize to unseen relation types. Here, we propose to use test-time augmentation (TTA) as a relation-agnostic method for reducing sensitivity to prompt variations by automatically augmenting and ensembling prompts at test time. Experiments show improved model calibration, i.e., with TTA, model confidence better reflects prediction accuracy. Improvements in prediction accuracy are observed for some models, but for other models, TTA leads to degradation. Error analysis identifies the difficulty of producing high-quality prompt variations as the main challenge for TTA.
Rethinking materials simulations: Blending direct numerical simulations with neural operators
Dec 08, 2023Direct numerical simulations (DNS) are accurate but computationally expensive for predicting materials evolution across timescales, due to the complexity of the underlying evolution equations, the nature of multiscale spatio-temporal interactions, and the need to reach long-time integration. We develop a new method that blends numerical solvers with neural operators to accelerate such simulations. This methodology is based on the integration of a community numerical solver with a U-Net neural operator, enhanced by a temporal-conditioning mechanism that enables accurate extrapolation and efficient time-to-solution predictions of the dynamics. We demonstrate the effectiveness of this framework on simulations of microstructure evolution during physical vapor deposition modeled via the phase-field method. Such simulations exhibit high spatial gradients due to the co-evolution of different material phases with simultaneous slow and fast materials dynamics. We establish accurate extrapolation of the coupled solver with up to 16.5$\times$ speed-up compared to DNS. This methodology is generalizable to a broad range of evolutionary models, from solid mechanics, to fluid dynamics, geophysics, climate, and more.