 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
IR-UWB Radar-Based Contactless Silent Speech Recognition of Vowels, Consonants, Words, and Phrases
Dec 15, 2023
Several sensing techniques have been proposed for silent speech recognition (SSR); however, many of these methods require invasive processes or sensor attachment to the skin using adhesive tape or glue, rendering them unsuitable for frequent use in daily life. By contrast, impulse radio ultra-wideband (IR-UWB) radar can operate without physical contact with users' articulators and related body parts, offering several advantages for SSR. These advantages include high range resolution, high penetrability, low power consumption, robustness to external light or sound interference, and the ability to be embedded in space-constrained handheld devices. This study demonstrated IR-UWB radar-based contactless SSR using four types of speech stimuli (vowels, consonants, words, and phrases). To achieve this, a novel speech feature extraction algorithm specifically designed for IR-UWB radar-based SSR is proposed. Each speech stimulus is recognized by applying a classification algorithm to the extracted speech features. Two different algorithms, multidimensional dynamic time warping (MD-DTW) and deep neural network-hidden Markov model (DNN-HMM), were compared for the classification task. Additionally, a favorable radar antenna position, either in front of the user's lips or below the user's chin, was determined to achieve higher recognition accuracy. Experimental results demonstrated the efficacy of the proposed speech feature extraction algorithm combined with DNN-HMM for classifying vowels, consonants, words, and phrases. Notably, this study represents the first demonstration of phoneme-level SSR using contactless radar.
Optimized Control Invariance Conditions for Uncertain Input-Constrained Nonlinear Control Systems
Dec 15, 2023Providing safety guarantees for learning-based controllers is important for real-world applications. One approach to realizing safety for arbitrary control policies is safety filtering. If necessary, the filter modifies control inputs to ensure that the trajectories of a closed-loop system stay within a given state constraint set for all future time, referred to as the set being positive invariant or the system being safe. Under the assumption of fully known dynamics, safety can be certified using control barrier functions (CBFs). However, the dynamics model is often either unknown or only partially known in practice. Learning-based methods have been proposed to approximate the CBF condition for unknown or uncertain systems from data; however, these techniques do not account for input constraints and, as a result, may not yield a valid CBF condition to render the safe set invariant. In this work, we study conditions that guarantee control invariance of the system under input constraints and propose an optimization problem to reduce the conservativeness of CBF-based safety filters. Building on these theoretical insights, we further develop a probabilistic learning approach that allows us to build a safety filter that guarantees safety for uncertain, input-constrained systems with high probability. We demonstrate the efficacy of our proposed approach in simulation and real-world experiments on a quadrotor and show that we can achieve safe closed-loop behavior for a learned system while satisfying state and input constraints.
Human motion trajectory prediction using the Social Force Model for real-time and low computational cost applications
Nov 17, 2023Human motion trajectory prediction is a very important functionality for human-robot collaboration, specifically in accompanying, guiding, or approaching tasks, but also in social robotics, self-driving vehicles, or security systems. In this paper, a novel trajectory prediction model, Social Force Generative Adversarial Network (SoFGAN), is proposed. SoFGAN uses a Generative Adversarial Network (GAN) and Social Force Model (SFM) to generate different plausible people trajectories reducing collisions in a scene. Furthermore, a Conditional Variational Autoencoder (CVAE) module is added to emphasize the destination learning. We show that our method is more accurate in making predictions in UCY or BIWI datasets than most of the current state-of-the-art models and also reduces collisions in comparison to other approaches. Through real-life experiments, we demonstrate that the model can be used in real-time without GPU's to perform good quality predictions with a low computational cost.
Added Toxicity Mitigation at Inference Time for Multimodal and Massively Multilingual Translation
Nov 11, 2023Added toxicity in the context of translation refers to the fact of producing a translation output with more toxicity than there exists in the input. In this paper, we present MinTox which is a novel pipeline to identify added toxicity and mitigate this issue which works at inference time. MinTox uses a toxicity detection classifier which is multimodal (speech and text) and works in languages at scale. The mitigation method is applied to languages at scale and directly in text outputs. MinTox is applied to SEAMLESSM4T, which is the latest multimodal and massively multilingual machine translation system. For this system, MinTox achieves significant added toxicity mitigation across domains, modalities and language directions. MinTox manages to approximately filter out from 25% to 95% of added toxicity (depending on the modality and domain) while keeping translation quality.
Adaptive Test-Time Personalization for Federated Learning
Oct 28, 2023
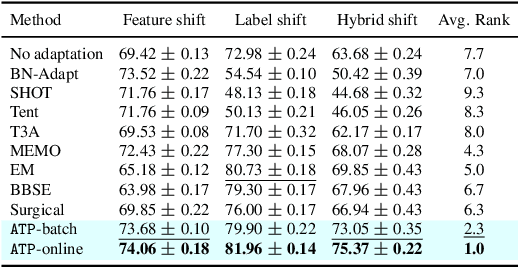
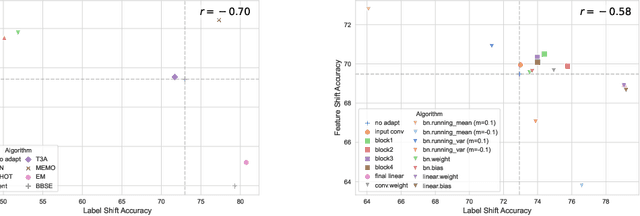
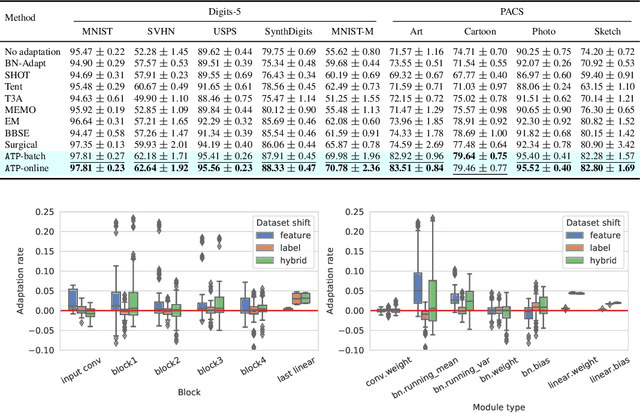
Personalized federated learning algorithms have shown promising results in adapting models to various distribution shifts. However, most of these methods require labeled data on testing clients for personalization, which is usually unavailable in real-world scenarios. In this paper, we introduce a novel setting called test-time personalized federated learning (TTPFL), where clients locally adapt a global model in an unsupervised way without relying on any labeled data during test-time. While traditional test-time adaptation (TTA) can be used in this scenario, most of them inherently assume training data come from a single domain, while they come from multiple clients (source domains) with different distributions. Overlooking these domain interrelationships can result in suboptimal generalization. Moreover, most TTA algorithms are designed for a specific kind of distribution shift and lack the flexibility to handle multiple kinds of distribution shifts in FL. In this paper, we find that this lack of flexibility partially results from their pre-defining which modules to adapt in the model. To tackle this challenge, we propose a novel algorithm called ATP to adaptively learns the adaptation rates for each module in the model from distribution shifts among source domains. Theoretical analysis proves the strong generalization of ATP. Extensive experiments demonstrate its superiority in handling various distribution shifts including label shift, image corruptions, and domain shift, outperforming existing TTA methods across multiple datasets and model architectures. Our code is available at https://github.com/baowenxuan/ATP .
Contrastive Moments: Unsupervised Halfspace Learning in Polynomial Time
Nov 02, 2023We give a polynomial-time algorithm for learning high-dimensional halfspaces with margins in $d$-dimensional space to within desired TV distance when the ambient distribution is an unknown affine transformation of the $d$-fold product of an (unknown) symmetric one-dimensional logconcave distribution, and the halfspace is introduced by deleting at least an $\epsilon$ fraction of the data in one of the component distributions. Notably, our algorithm does not need labels and establishes the unique (and efficient) identifiability of the hidden halfspace under this distributional assumption. The sample and time complexity of the algorithm are polynomial in the dimension and $1/\epsilon$. The algorithm uses only the first two moments of suitable re-weightings of the empirical distribution, which we call contrastive moments; its analysis uses classical facts about generalized Dirichlet polynomials and relies crucially on a new monotonicity property of the moment ratio of truncations of logconcave distributions. Such algorithms, based only on first and second moments were suggested in earlier work, but hitherto eluded rigorous guarantees. Prior work addressed the special case when the underlying distribution is Gaussian via Non-Gaussian Component Analysis. We improve on this by providing polytime guarantees based on Total Variation (TV) distance, in place of existing moment-bound guarantees that can be super-polynomial. Our work is also the first to go beyond Gaussians in this setting.
Neural Reasoning About Agents' Goals, Preferences, and Actions
Dec 12, 2023We propose the Intuitive Reasoning Network (IRENE) - a novel neural model for intuitive psychological reasoning about agents' goals, preferences, and actions that can generalise previous experiences to new situations. IRENE combines a graph neural network for learning agent and world state representations with a transformer to encode the task context. When evaluated on the challenging Baby Intuitions Benchmark, IRENE achieves new state-of-the-art performance on three out of its five tasks - with up to 48.9% improvement. In contrast to existing methods, IRENE is able to bind preferences to specific agents, to better distinguish between rational and irrational agents, and to better understand the role of blocking obstacles. We also investigate, for the first time, the influence of the training tasks on test performance. Our analyses demonstrate the effectiveness of IRENE in combining prior knowledge gained during training for unseen evaluation tasks.
Understanding the Effect of Model Compression on Social Bias in Large Language Models
Dec 12, 2023Large Language Models (LLMs) trained with self-supervision on vast corpora of web text fit to the social biases of that text. Without intervention, these social biases persist in the model's predictions in downstream tasks, leading to representational harm. Many strategies have been proposed to mitigate the effects of inappropriate social biases learned during pretraining. Simultaneously, methods for model compression have become increasingly popular to reduce the computational burden of LLMs. Despite the popularity and need for both approaches, little work has been done to explore the interplay between these two. We perform a carefully controlled study of the impact of model compression via quantization and knowledge distillation on measures of social bias in LLMs. Longer pretraining and larger models led to higher social bias, and quantization showed a regularizer effect with its best trade-off around 20% of the original pretraining time.
The Complexity of Envy-Free Graph Cutting
Dec 12, 2023We consider the problem of fairly dividing a set of heterogeneous divisible resources among agents with different preferences. We focus on the setting where the resources correspond to the edges of a connected graph, every agent must be assigned a connected piece of this graph, and the fairness notion considered is the classical envy freeness. The problem is NP-complete, and we analyze its complexity with respect to two natural complexity measures: the number of agents and the number of edges in the graph. While the problem remains NP-hard even for instances with 2 agents, we provide a dichotomy characterizing the complexity of the problem when the number of agents is constant based on structural properties of the graph. For the latter case, we design a polynomial-time algorithm when the graph has a constant number of edges.
The Gaussian-Linear Hidden Markov model: a Python package
Dec 12, 2023We propose the Gaussian-Linear Hidden Markov model (GLHMM), a generalisation of different types of HMMs commonly used in neuroscience. In short, the GLHMM is a general framework where linear regression is used to flexibly parameterise the Gaussian state distribution, thereby accommodating a wide range of uses -including unsupervised, encoding and decoding models. GLHMM is implemented as a Python toolbox with an emphasis on statistical testing and out-of-sample prediction -i.e. aimed at finding and characterising brain-behaviour associations. The toolbox uses a stochastic variational inference approach, enabling it to handle large data sets at reasonable computational time. Overall, the approach can be applied to several data modalities, including animal recordings or non-brain data, and applied over a broad range of experimental paradigms. For demonstration, we show examples with fMRI, electrocorticography, magnetoencephalo-graphy and pupillometry.