 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Embodied Adversarial Attack: A Dynamic Robust Physical Attack in Autonomous Driving
Dec 15, 2023
As physical adversarial attacks become extensively applied in unearthing the potential risk of security-critical scenarios, especially in autonomous driving, their vulnerability to environmental changes has also been brought to light. The non-robust nature of physical adversarial attack methods brings less-than-stable performance consequently. To enhance the robustness of physical adversarial attacks in the real world, instead of statically optimizing a robust adversarial example via an off-line training manner like the existing methods, this paper proposes a brand new robust adversarial attack framework: Embodied Adversarial Attack (EAA) from the perspective of dynamic adaptation, which aims to employ the paradigm of embodied intelligence: Perception-Decision-Control to dynamically adjust the optimal attack strategy according to the current situations in real time. For the perception module, given the challenge of needing simulation for the victim's viewpoint, EAA innovatively devises a Perspective Transformation Network to estimate the target's transformation from the attacker's perspective. For the decision and control module, EAA adopts the laser-a highly manipulable medium to implement physical attacks, and further trains an attack agent with reinforcement learning to make it capable of instantaneously determining the best attack strategy based on the perceived information. Finally, we apply our framework to the autonomous driving scenario. A variety of experiments verify the high effectiveness of our method under complex scenes.
N-Gram Unsupervised Compoundation and Feature Injection for Better Symbolic Music Understanding
Dec 15, 2023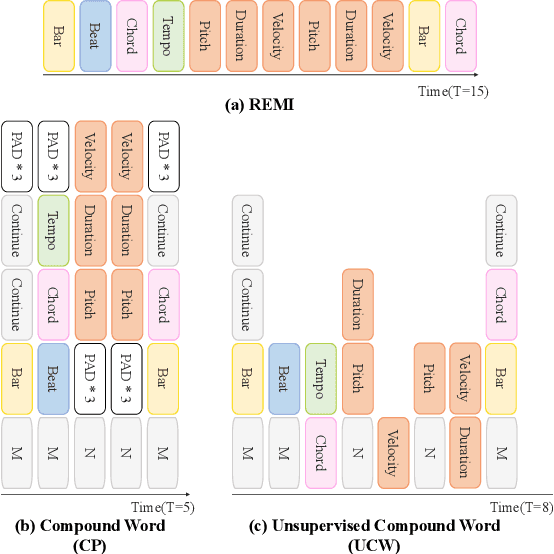
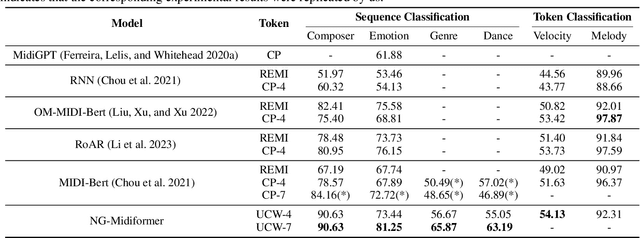
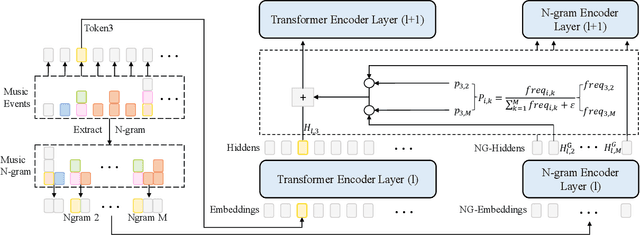
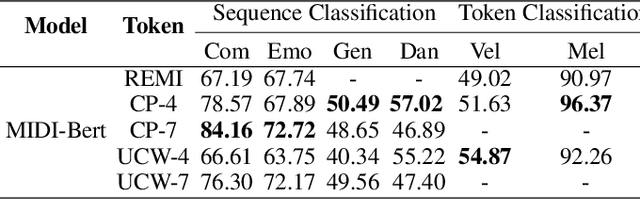
The first step to apply deep learning techniques for symbolic music understanding is to transform musical pieces (mainly in MIDI format) into sequences of predefined tokens like note pitch, note velocity, and chords. Subsequently, the sequences are fed into a neural sequence model to accomplish specific tasks. Music sequences exhibit strong correlations between adjacent elements, making them prime candidates for N-gram techniques from Natural Language Processing (NLP). Consider classical piano music: specific melodies might recur throughout a piece, with subtle variations each time. In this paper, we propose a novel method, NG-Midiformer, for understanding symbolic music sequences that leverages the N-gram approach. Our method involves first processing music pieces into word-like sequences with our proposed unsupervised compoundation, followed by using our N-gram Transformer encoder, which can effectively incorporate N-gram information to enhance the primary encoder part for better understanding of music sequences. The pre-training process on large-scale music datasets enables the model to thoroughly learn the N-gram information contained within music sequences, and subsequently apply this information for making inferences during the fine-tuning stage. Experiment on various datasets demonstrate the effectiveness of our method and achieved state-of-the-art performance on a series of music understanding downstream tasks. The code and model weights will be released at https://github.com/CinqueOrigin/NG-Midiformer.
Image Deblurring using GAN
Dec 15, 2023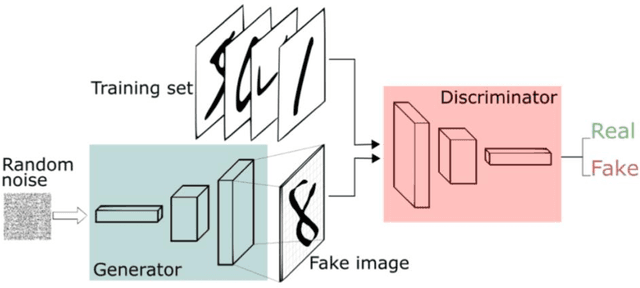
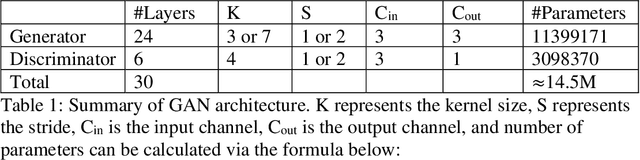
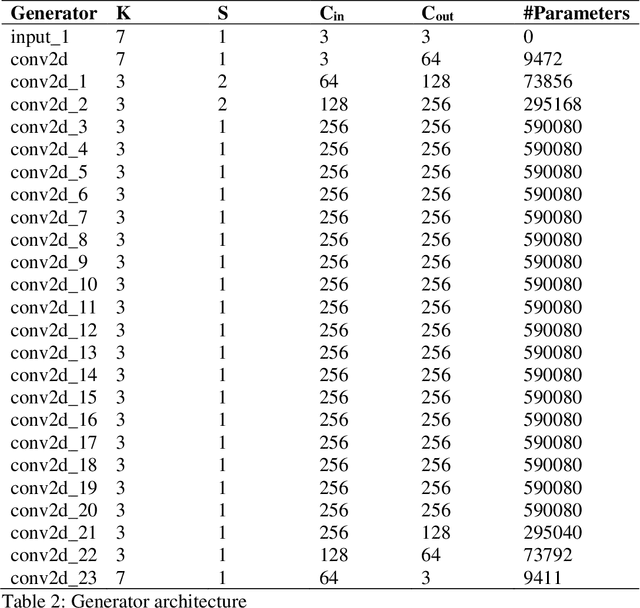

In recent years, deep generative models, such as Generative Adversarial Network (GAN), has grabbed significant attention in the field of computer vision. This project focuses on the application of GAN in image deblurring with the aim of generating clearer images from blurry inputs caused by factors such as motion blur. However, traditional image restoration techniques have limitations in handling complex blurring patterns. Hence, a GAN-based framework is proposed as a solution to generate high-quality deblurred images. The project defines a GAN model in Tensorflow and trains it with GoPRO dataset. The Generator will intake blur images directly to create fake images to convince the Discriminator which will receive clear images at the same time and distinguish between the real image and the fake image. After obtaining the trained parameters, the model was used to deblur motion-blur images taken in daily life as well as testing set for validation. The result shows that the pretrained network of GAN can obtain sharper pixels in image, achieving an average of 29.3 Peak Signal-to-Noise Ratio (PSNR) and 0.72 Structural Similarity Assessment (SSIM). This help to effectively address the challenges posed by image blurring, leading to the generation of visually pleasing and sharp images. By exploiting the adversarial learning framework, the proposed approach enhances the potential for real-world applications in image restoration.
Deep-Learning-Assisted Analysis of Cataract Surgery Videos
Dec 10, 2023Following the technological advancements in medicine, the operation rooms are evolving into intelligent environments. The context-aware systems (CAS) can comprehensively interpret the surgical state, enable real-time warning, and support decision-making, especially for novice surgeons. These systems can automatically analyze surgical videos and perform indexing, documentation, and post-operative report generation. The ever-increasing demand for such automatic systems has sparked machine-learning-based approaches for surgical video analysis. This thesis addresses the significant challenges in cataract surgery video analysis to pave the way for building efficient context-aware systems. The main contributions of this thesis are five folds: (1) This thesis demonstrates that spatio-temporal localization of the relevant content can considerably improve phase recognition accuracy. (2) This thesis proposes a novel deep-learning-based framework for relevance-based compression to enable real-time streaming and adaptive storage of cataract surgery videos. (3) Several convolutional modules are proposed to boost the networks' semantic interpretation performance in challenging conditions. These challenges include blur and reflection distortion, transparency, deformability, color and texture variation, blunt edges, and scale variation. (4) This thesis proposes and evaluates the first framework for automatic irregularity detection in cataract surgery videos. (5) To alleviate the requirement for manual pixel-based annotations, this thesis proposes novel strategies for self-supervised representation learning adapted to semantic segmentation.
Active Wildfires Detection and Dynamic Escape Routes Planning for Humans through Information Fusion between Drones and Satellites
Dec 06, 2023UAVs are playing an increasingly important role in the field of wilderness rescue by virtue of their flexibility. This paper proposes a fusion of UAV vision technology and satellite image analysis technology for active wildfires detection and road networks extraction of wildfire areas and real-time dynamic escape route planning for people in distress. Firstly, the fire source location and the segmentation of smoke and flames are targeted based on Sentinel 2 satellite imagery. Secondly, the road segmentation and the road condition assessment are performed by D-linkNet and NDVI values in the central area of the fire source by UAV. Finally, the dynamic optimal route planning for humans in real time is performed by the weighted A* algorithm in the road network with the dynamic fire spread model. Taking the Chongqing wildfire on August 24, 2022, as a case study, the results demonstrate that the dynamic escape route planning algorithm can provide an optimal real-time navigation path for humans in the presence of fire through the information fusion of UAVs and satellites.
MusER: Musical Element-Based Regularization for Generating Symbolic Music with Emotion
Dec 16, 2023Generating music with emotion is an important task in automatic music generation, in which emotion is evoked through a variety of musical elements (such as pitch and duration) that change over time and collaborate with each other. However, prior research on deep learning-based emotional music generation has rarely explored the contribution of different musical elements to emotions, let alone the deliberate manipulation of these elements to alter the emotion of music, which is not conducive to fine-grained element-level control over emotions. To address this gap, we present a novel approach employing musical element-based regularization in the latent space to disentangle distinct elements, investigate their roles in distinguishing emotions, and further manipulate elements to alter musical emotions. Specifically, we propose a novel VQ-VAE-based model named MusER. MusER incorporates a regularization loss to enforce the correspondence between the musical element sequences and the specific dimensions of latent variable sequences, providing a new solution for disentangling discrete sequences. Taking advantage of the disentangled latent vectors, a two-level decoding strategy that includes multiple decoders attending to latent vectors with different semantics is devised to better predict the elements. By visualizing latent space, we conclude that MusER yields a disentangled and interpretable latent space and gain insights into the contribution of distinct elements to the emotional dimensions (i.e., arousal and valence). Experimental results demonstrate that MusER outperforms the state-of-the-art models for generating emotional music in both objective and subjective evaluation. Besides, we rearrange music through element transfer and attempt to alter the emotion of music by transferring emotion-distinguishable elements.
FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects
Dec 13, 2023We present FoundationPose, a unified foundation model for 6D object pose estimation and tracking, supporting both model-based and model-free setups. Our approach can be instantly applied at test-time to a novel object without fine-tuning, as long as its CAD model is given, or a small number of reference images are captured. We bridge the gap between these two setups with a neural implicit representation that allows for effective novel view synthesis, keeping the downstream pose estimation modules invariant under the same unified framework. Strong generalizability is achieved via large-scale synthetic training, aided by a large language model (LLM), a novel transformer-based architecture, and contrastive learning formulation. Extensive evaluation on multiple public datasets involving challenging scenarios and objects indicate our unified approach outperforms existing methods specialized for each task by a large margin. In addition, it even achieves comparable results to instance-level methods despite the reduced assumptions. Project page: https://nvlabs.github.io/FoundationPose/
Novel View Synthesis with View-Dependent Effects from a Single Image
Dec 13, 2023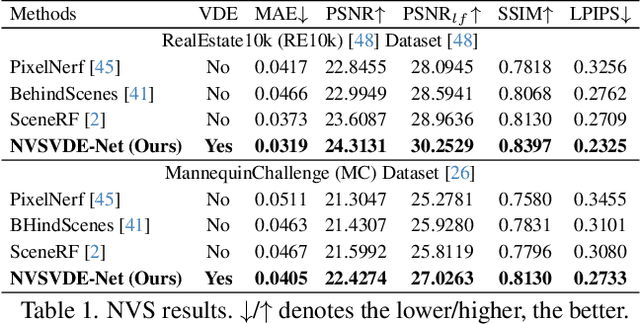
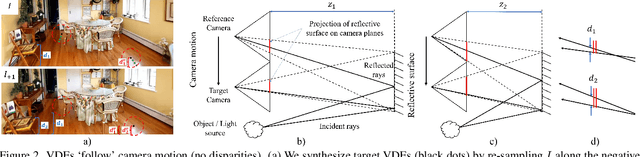
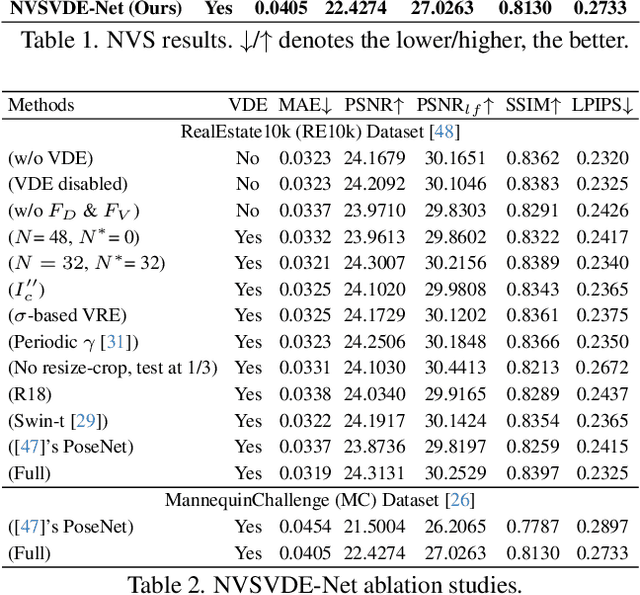
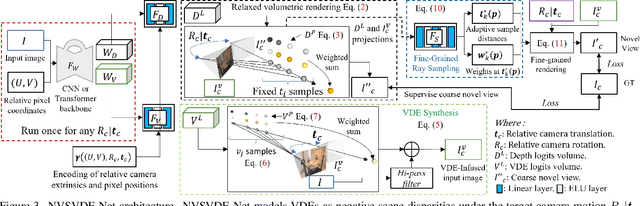
In this paper, we firstly consider view-dependent effects into single image-based novel view synthesis (NVS) problems. For this, we propose to exploit the camera motion priors in NVS to model view-dependent appearance or effects (VDE) as the negative disparity in the scene. By recognizing specularities "follow" the camera motion, we infuse VDEs into the input images by aggregating input pixel colors along the negative depth region of the epipolar lines. Also, we propose a `relaxed volumetric rendering' approximation that allows computing the densities in a single pass, improving efficiency for NVS from single images. Our method can learn single-image NVS from image sequences only, which is a completely self-supervised learning method, for the first time requiring neither depth nor camera pose annotations. We present extensive experiment results and show that our proposed method can learn NVS with VDEs, outperforming the SOTA single-view NVS methods on the RealEstate10k and MannequinChallenge datasets.
Secure Deep Reinforcement Learning for Dynamic Resource Allocation in Wireless MEC Networks
Dec 13, 2023This paper proposes a blockchain-secured deep reinforcement learning (BC-DRL) optimization framework for {data management and} resource allocation in decentralized {wireless mobile edge computing (MEC)} networks. In our framework, {we design a low-latency reputation-based proof-of-stake (RPoS) consensus protocol to select highly reliable blockchain-enabled BSs to securely store MEC user requests and prevent data tampering attacks.} {We formulate the MEC resource allocation optimization as a constrained Markov decision process that balances minimum processing latency and denial-of-service (DoS) probability}. {We use the MEC aggregated features as the DRL input to significantly reduce the high-dimensionality input of the remaining service processing time for individual MEC requests. Our designed constrained DRL effectively attains the optimal resource allocations that are adapted to the dynamic DoS requirements. We provide extensive simulation results and analysis to} validate that our BC-DRL framework achieves higher security, reliability, and resource utilization efficiency than benchmark blockchain consensus protocols and {MEC} resource allocation algorithms.
Markov Decision Processes with Noisy State Observation
Dec 13, 2023This paper addresses the challenge of a particular class of noisy state observations in Markov Decision Processes (MDPs), a common issue in various real-world applications. We focus on modeling this uncertainty through a confusion matrix that captures the probabilities of misidentifying the true state. Our primary goal is to estimate the inherent measurement noise, and to this end, we propose two novel algorithmic approaches. The first, the method of second-order repetitive actions, is designed for efficient noise estimation within a finite time window, providing identifiable conditions for system analysis. The second approach comprises a family of Bayesian algorithms, which we thoroughly analyze and compare in terms of performance and limitations. We substantiate our theoretical findings with simulations, demonstrating the effectiveness of our methods in different scenarios, particularly highlighting their behavior in environments with varying stationary distributions. Our work advances the understanding of reinforcement learning in noisy environments, offering robust techniques for more accurate state estimation in MDPs.