 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SlimmeRF: Slimmable Radiance Fields
Dec 15, 2023
Neural Radiance Field (NeRF) and its variants have recently emerged as successful methods for novel view synthesis and 3D scene reconstruction. However, most current NeRF models either achieve high accuracy using large model sizes, or achieve high memory-efficiency by trading off accuracy. This limits the applicable scope of any single model, since high-accuracy models might not fit in low-memory devices, and memory-efficient models might not satisfy high-quality requirements. To this end, we present SlimmeRF, a model that allows for instant test-time trade-offs between model size and accuracy through slimming, thus making the model simultaneously suitable for scenarios with different computing budgets. We achieve this through a newly proposed algorithm named Tensorial Rank Incrementation (TRaIn) which increases the rank of the model's tensorial representation gradually during training. We also observe that our model allows for more effective trade-offs in sparse-view scenarios, at times even achieving higher accuracy after being slimmed. We credit this to the fact that erroneous information such as floaters tend to be stored in components corresponding to higher ranks. Our implementation is available at https://github.com/Shiran-Yuan/SlimmeRF.
Distributed Learning of Mixtures of Experts
Dec 15, 2023In modern machine learning problems we deal with datasets that are either distributed by nature or potentially large for which distributing the computations is usually a standard way to proceed, since centralized algorithms are in general ineffective. We propose a distributed learning approach for mixtures of experts (MoE) models with an aggregation strategy to construct a reduction estimator from local estimators fitted parallelly to distributed subsets of the data. The aggregation is based on an optimal minimization of an expected transportation divergence between the large MoE composed of local estimators and the unknown desired MoE model. We show that the provided reduction estimator is consistent as soon as the local estimators to be aggregated are consistent, and its construction is performed by a proposed majorization-minimization (MM) algorithm that is computationally effective. We study the statistical and numerical properties for the proposed reduction estimator on experiments that demonstrate its performance compared to namely the global estimator constructed in a centralized way from the full dataset. For some situations, the computation time is more than ten times faster, for a comparable performance. Our source codes are publicly available on Github.
Focus on Your Instruction: Fine-grained and Multi-instruction Image Editing by Attention Modulation
Dec 15, 2023Recently, diffusion-based methods, like InstructPix2Pix (IP2P), have achieved effective instruction-based image editing, requiring only natural language instructions from the user. However, these methods often inadvertently alter unintended areas and struggle with multi-instruction editing, resulting in compromised outcomes. To address these issues, we introduce the Focus on Your Instruction (FoI), a method designed to ensure precise and harmonious editing across multiple instructions without extra training or test-time optimization. In the FoI, we primarily emphasize two aspects: (1) precisely extracting regions of interest for each instruction and (2) guiding the denoising process to concentrate within these regions of interest. For the first objective, we identify the implicit grounding capability of IP2P from the cross-attention between instruction and image, then develop an effective mask extraction method. For the second objective, we introduce a cross attention modulation module for rough isolation of target editing regions and unrelated regions. Additionally, we introduce a mask-guided disentangle sampling strategy to further ensure clear region isolation. Experimental results demonstrate that FoI surpasses existing methods in both quantitative and qualitative evaluations, especially excelling in multi-instruction editing task.
Pixel-Superpixel Contrastive Learning and Pseudo-Label Correction for Hyperspectral Image Clustering
Dec 15, 2023Hyperspectral image (HSI) clustering is gaining considerable attention owing to recent methods that overcome the inefficiency and misleading results from the absence of supervised information. Contrastive learning methods excel at existing pixel level and super pixel level HSI clustering tasks. The pixel-level contrastive learning method can effectively improve the ability of the model to capture fine features of HSI but requires a large time overhead. The super pixel-level contrastive learning method utilizes the homogeneity of HSI and reduces computing resources; however, it yields rough classification results. To exploit the strengths of both methods, we present a pixel super pixel contrastive learning and pseudo-label correction (PSCPC) method for the HSI clustering. PSCPC can reasonably capture domain-specific and fine-grained features through super pixels and the comparative learning of a small number of pixels within the super pixels. To improve the clustering performance of super pixels, this paper proposes a pseudo-label correction module that aligns the clustering pseudo-labels of pixels and super-pixels. In addition, pixel-level clustering results are used to supervise super pixel-level clustering, improving the generalization ability of the model. Extensive experiments demonstrate the effectiveness and efficiency of PSCPC.
NeXt-TDNN: Modernizing Multi-Scale Temporal Convolution Backbone for Speaker Verification
Dec 15, 2023In speaker verification, ECAPA-TDNN has shown remarkable improvement by utilizing one-dimensional(1D) Res2Net block and squeeze-and-excitation(SE) module, along with multi-layer feature aggregation (MFA). Meanwhile, in vision tasks, ConvNet structures have been modernized by referring to Transformer, resulting in improved performance. In this paper, we present an improved block design for TDNN in speaker verification. Inspired by recent ConvNet structures, we replace the SE-Res2Net block in ECAPA-TDNN with a novel 1D two-step multi-scale ConvNeXt block, which we call TS-ConvNeXt. The TS-ConvNeXt block is constructed using two separated sub-modules: a temporal multi-scale convolution (MSC) and a frame-wise feed-forward network (FFN). This two-step design allows for flexible capturing of inter-frame and intra-frame contexts. Additionally, we introduce global response normalization (GRN) for the FFN modules to enable more selective feature propagation, similar to the SE module in ECAPA-TDNN. Experimental results demonstrate that NeXt-TDNN, with a modernized backbone block, significantly improved performance in speaker verification tasks while reducing parameter size and inference time. We have released our code for future studies.
In vivo learning-based control of microbial populations density in bioreactors
Dec 15, 2023
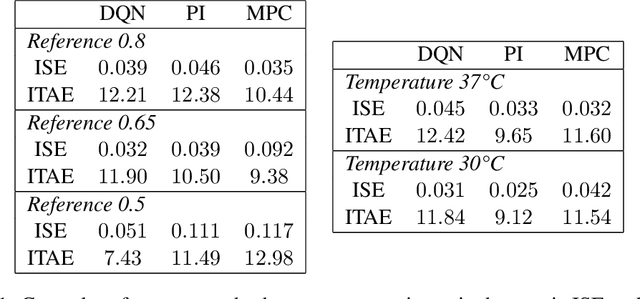
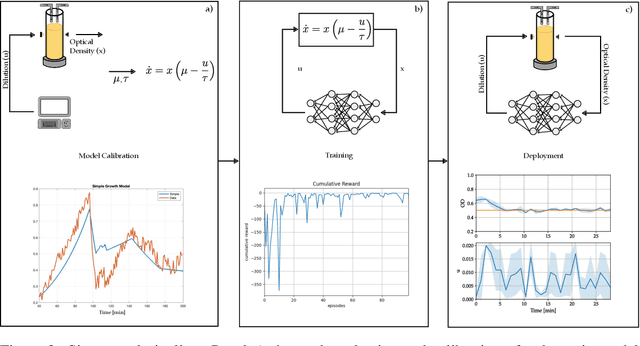
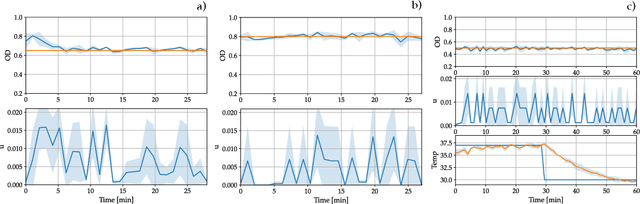
A key problem toward the use of microorganisms as bio-factories is reaching and maintaining cellular communities at a desired density and composition so that they can efficiently convert their biomass into useful compounds. Promising technological platforms for the real time, scalable control of cellular density are bioreactors. In this work, we developed a learning-based strategy to expand the toolbox of available control algorithms capable of regulating the density of a \textit{single} bacterial population in bioreactors. Specifically, we used a sim-to-real paradigm, where a simple mathematical model, calibrated using a few data, was adopted to generate synthetic data for the training of the controller. The resulting policy was then exhaustively tested in vivo using a low-cost bioreactor known as Chi.Bio, assessing performance and robustness. In addition, we compared the performance with more traditional controllers (namely, a PI and an MPC), confirming that the learning-based controller exhibits similar performance in vivo. Our work showcases the viability of learning-based strategies for the control of cellular density in bioreactors, making a step forward toward their use for the control of the composition of microbial consortia.
Diffusion for Natural Image Matting
Dec 10, 2023We aim to leverage diffusion to address the challenging image matting task. However, the presence of high computational overhead and the inconsistency of noise sampling between the training and inference processes pose significant obstacles to achieving this goal. In this paper, we present DiffMatte, a solution designed to effectively overcome these challenges. First, DiffMatte decouples the decoder from the intricately coupled matting network design, involving only one lightweight decoder in the iterations of the diffusion process. With such a strategy, DiffMatte mitigates the growth of computational overhead as the number of samples increases. Second, we employ a self-aligned training strategy with uniform time intervals, ensuring a consistent noise sampling between training and inference across the entire time domain. Our DiffMatte is designed with flexibility in mind and can seamlessly integrate into various modern matting architectures. Extensive experimental results demonstrate that DiffMatte not only reaches the state-of-the-art level on the Composition-1k test set, surpassing the best methods in the past by 5% and 15% in the SAD metric and MSE metric respectively, but also show stronger generalization ability in other benchmarks.
A Unified Sampling Framework for Solver Searching of Diffusion Probabilistic Models
Dec 12, 2023Recent years have witnessed the rapid progress and broad application of diffusion probabilistic models (DPMs). Sampling from DPMs can be viewed as solving an ordinary differential equation (ODE). Despite the promising performance, the generation of DPMs usually consumes much time due to the large number of function evaluations (NFE). Though recent works have accelerated the sampling to around 20 steps with high-order solvers, the sample quality with less than 10 NFE can still be improved. In this paper, we propose a unified sampling framework (USF) to study the optional strategies for solver. Under this framework, we further reveal that taking different solving strategies at different timesteps may help further decrease the truncation error, and a carefully designed \emph{solver schedule} has the potential to improve the sample quality by a large margin. Therefore, we propose a new sampling framework based on the exponential integral formulation that allows free choices of solver strategy at each step and design specific decisions for the framework. Moreover, we propose $S^3$, a predictor-based search method that automatically optimizes the solver schedule to get a better time-quality trade-off of sampling. We demonstrate that $S^3$ can find outstanding solver schedules which outperform the state-of-the-art sampling methods on CIFAR-10, CelebA, ImageNet, and LSUN-Bedroom datasets. Specifically, we achieve 2.69 FID with 10 NFE and 6.86 FID with 5 NFE on CIFAR-10 dataset, outperforming the SOTA method significantly. We further apply $S^3$ to Stable-Diffusion model and get an acceleration ratio of 2$\times$, showing the feasibility of sampling in very few steps without retraining the neural network.
Improving Entropy-Based Test-Time Adaptation from a Clustering View
Nov 07, 2023Domain shift is a common problem in the realistic world, where training data and test data follow different data distributions. To deal with this problem, fully test-time adaptation (TTA) leverages the unlabeled data encountered during test time to adapt the model. In particular, Entropy-Based TTA (EBTTA) methods, which minimize the prediction's entropy on test samples, have shown great success. In this paper, we introduce a new perspective on the EBTTA, which interprets these methods from a view of clustering. It is an iterative algorithm: 1) in the assignment step, the forward process of the EBTTA models is the assignment of labels for these test samples, and 2) in the updating step, the backward process is the update of the model via the assigned samples. Based on the interpretation, we can gain a deeper understanding of EBTTA, where we show that the entropy loss would further increase the largest probability. Accordingly, we offer an alternative explanation for why existing EBTTA methods are sensitive to initial assignments, outliers, and batch size. This observation can guide us to put forward the improvement of EBTTA. We propose robust label assignment, weight adjustment, and gradient accumulation to alleviate the above problems. Experimental results demonstrate that our method can achieve consistent improvements on various datasets. Code is provided in the supplementary material.
Converting Epics/Stories into Pseudocode using Transformers
Dec 08, 2023The conversion of user epics or stories into their appropriate representation in pseudocode or code is a time-consuming task, which can take up a large portion of the time in an industrial project. With this research paper, we aim to present a methodology to generate pseudocode from a given agile user story of small functionalities so as to reduce the overall time spent on the industrial project. Pseudocode is a programming language agnostic representation of the steps involved in a computer program, which can be easily converted into any programming language. Leveraging the potential of Natural Language Processing, we want to simplify the development process in organizations that use the Agile Model of Software Development. We present a methodology to convert a problem described in the English language into pseudocode. This methodology divides the Text to Pseudocode conversion task into two stages or subtasks, each of which is treated like an individual machine translation task. Stage 1 is Text to Code Conversion and Stage 2 is Code to Pseudocode Conversion. We find that the CodeT5 model gives the best results in terms of BLEU score when trained separately on the two subtasks mentioned above. BLEU score is a metric that is used to measure the similarity between a machine-translated text and a set of reference translations.