 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Riemannian Complex Matrix Convolution Network for PolSAR Image Classification
Dec 06, 2023
Recently, deep learning methods have achieved superior performance for Polarimetric Synthetic Aperture Radar(PolSAR) image classification. Existing deep learning methods learn PolSAR data by converting the covariance matrix into a feature vector or complex-valued vector as the input. However, all these methods cannot learn the structure of complex matrix directly and destroy the channel correlation. To learn geometric structure of complex matrix, we propose a Riemannian complex matrix convolution network for PolSAR image classification in Riemannian space for the first time, which directly utilizes the complex matrix as the network input and defines the Riemannian operations to learn complex matrix's features. The proposed Riemannian complex matrix convolution network considers PolSAR complex matrix endowed in Riemannian manifold, and defines a series of new Riemannian convolution, ReLu and LogEig operations in Riemannian space, which breaks through the Euclidean constraint of conventional networks. Then, a CNN module is appended to enhance contextual Riemannian features. Besides, a fast kernel learning method is developed for the proposed method to learn class-specific features and reduce the computation time effectively. Experiments are conducted on three sets of real PolSAR data with different bands and sensors. Experiments results demonstrates the proposed method can obtain superior performance than the state-of-the-art methods.
Impact of Array Configuration on Head-Mounted Display Performance at mmWave Bands
Dec 12, 2023Immersing a user in life-like extended reality (XR) scenery using a head-mounted display (HMD) with a constrained form factor and hardware complexity requires remote rendering on a nearby edge server or computer. Millimeter-wave (mmWave) communication technology can provide sufficient data rate for wireless XR content transmission. However, mmWave channels exhibit severe sparsity in the angular domain. This means that distributed antenna arrays are required to cover a larger angular area and to combat outage during HMD rotation. At the same time, one would prefer fewer antenna elements/arrays for a lower complexity system. Therefore, it is important to evaluate the trade-off between the number of antenna arrays and the achievable performance to find a proper practical solution. This work presents indoor 28 GHz mmWave channel measurement data, collected during HMD mobility, and studies the dominant eigenmode (DE) gain. DE gain is a significant factor in understanding system performance since mmWave channel sparsity and eigenmode imbalance often results in provisioning the majority of the available power to the DE. Moreover, it provides the upper performance bounds for widely-adopted analog beamformers. We propose 3 performance metrics - gain trade-off, gain volatility, and minimum service trade-off - for evaluating the performance of a multi-array HMD and apply the metrics to indoor 28 GHz channel measurement data. Evaluation results indicate, that 3 arrays provide stable temporal channel gain. Adding a 4th array further increases channel capacity, while any additional arrays do not significantly increase physical layer performance.
Attacking the Loop: Adversarial Attacks on Graph-based Loop Closure Detection
Dec 12, 2023With the advancement in robotics, it is becoming increasingly common for large factories and warehouses to incorporate visual SLAM (vSLAM) enabled automated robots that operate closely next to humans. This makes any adversarial attacks on vSLAM components potentially detrimental to humans working alongside them. Loop Closure Detection (LCD) is a crucial component in vSLAM that minimizes the accumulation of drift in mapping, since even a small drift can accumulate into a significant drift over time. A prior work by Kim et al., SymbioLCD2, unified visual features and semantic objects into a single graph structure for finding loop closure candidates. While this provided a performance improvement over visual feature-based LCD, it also created a single point of vulnerability for potential graph-based adversarial attacks. Unlike previously reported visual-patch based attacks, small graph perturbations are far more challenging to detect, making them a more significant threat. In this paper, we present Adversarial-LCD, a novel black-box evasion attack framework that employs an eigencentrality-based perturbation method and an SVM-RBF surrogate model with a Weisfeiler-Lehman feature extractor for attacking graph-based LCD. Our evaluation shows that the attack performance of Adversarial-LCD with the SVM-RBF surrogate model was superior to that of other machine learning surrogate algorithms, including SVM-linear, SVM-polynomial, and Bayesian classifier, demonstrating the effectiveness of our attack framework. Furthermore, we show that our eigencentrality-based perturbation method outperforms other algorithms, such as Random-walk and Shortest-path, highlighting the efficiency of Adversarial-LCD's perturbation selection method.
EEG-Based Reaction Time Prediction with Fuzzy Common Spatial Patterns and Phase Cohesion using Deep Autoencoder Based Data Fusion
Dec 01, 2023Drowsiness state of a driver is a topic of extensive discussion due to its significant role in causing traffic accidents. This research presents a novel approach that combines Fuzzy Common Spatial Patterns (CSP) optimised Phase Cohesive Sequence (PCS) representations and fuzzy CSP-optimized signal amplitude representations. The research aims to examine alterations in Electroencephalogram (EEG) synchronisation between a state of alertness and drowsiness, forecast drivers' reaction times by analysing EEG data, and subsequently identify the presence of drowsiness. The study's findings indicate that this approach successfully distinguishes between alert and drowsy mental states. By employing a Deep Autoencoder-based data fusion technique and a regression model such as Support Vector Regression (SVR) or Least Absolute Shrinkage and Selection Operator (LASSO), the proposed method outperforms using individual feature sets in combination with a regressor model. This superiority is measured by evaluating the Root Mean Squared Error (RMSE), Mean Absolute Percentage Error (MAPE), and Correlation Coefficient (CC). In other words, the fusion of autoencoder-based amplitude EEG power features and PCS features, when used in regression, outperforms using either of these features alone in a regressor model. Specifically, the proposed data fusion method achieves a 14.36% reduction in RMSE, a 25.12% reduction in MAPE, and a 10.12% increase in CC compared to the baseline model using only individual amplitude EEG power features and regression.
HybridNeRF: Efficient Neural Rendering via Adaptive Volumetric Surfaces
Dec 05, 2023Neural radiance fields provide state-of-the-art view synthesis quality but tend to be slow to render. One reason is that they make use of volume rendering, thus requiring many samples (and model queries) per ray at render time. Although this representation is flexible and easy to optimize, most real-world objects can be modeled more efficiently with surfaces instead of volumes, requiring far fewer samples per ray. This observation has spurred considerable progress in surface representations such as signed distance functions, but these may struggle to model semi-opaque and thin structures. We propose a method, HybridNeRF, that leverages the strengths of both representations by rendering most objects as surfaces while modeling the (typically) small fraction of challenging regions volumetrically. We evaluate HybridNeRF against the challenging Eyeful Tower dataset along with other commonly used view synthesis datasets. When comparing to state-of-the-art baselines, including recent rasterization-based approaches, we improve error rates by 15-30% while achieving real-time framerates (at least 36 FPS) for virtual-reality resolutions (2Kx2K).
Efficient Collision Detection Oriented Motion Primitives for Path Planning
Dec 05, 2023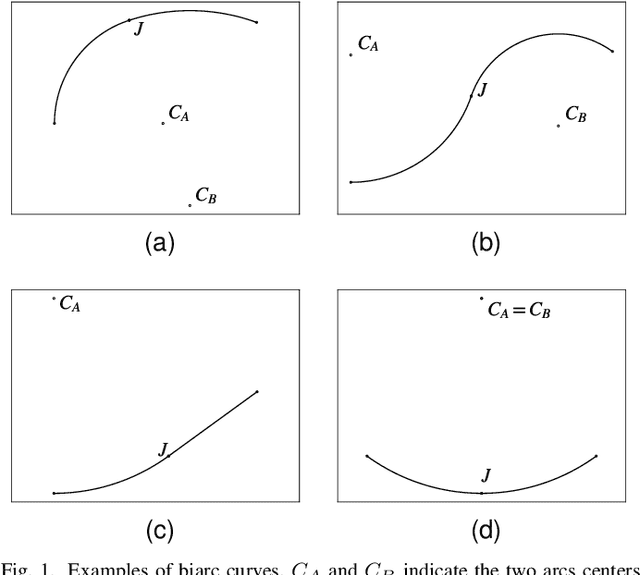
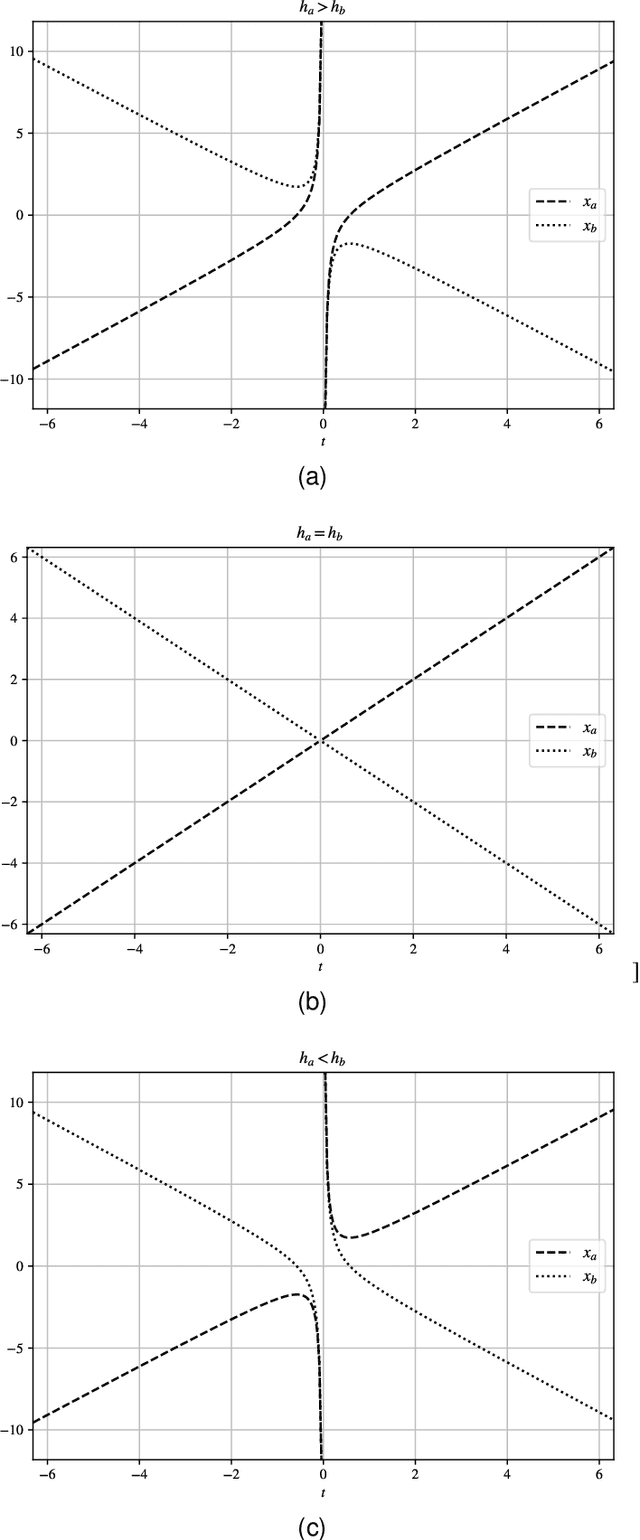
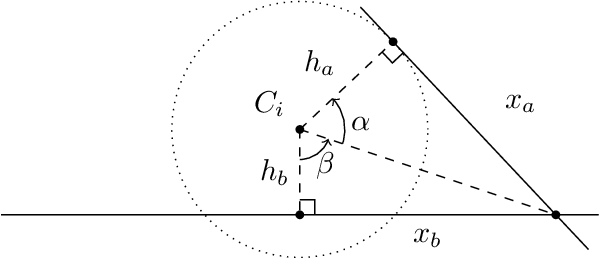
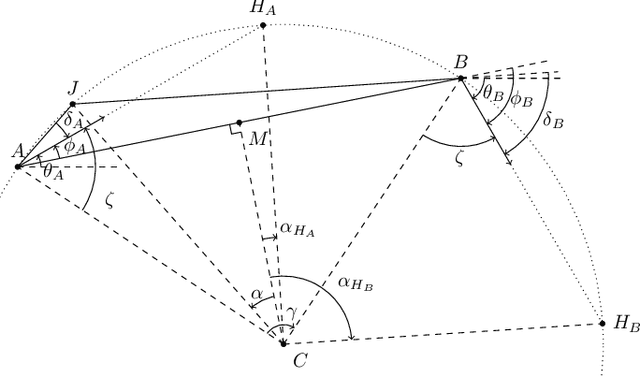
Mobile robots in dynamic environments require fast planning, especially when onboard computational resources are limited. While classic potential field based algorithms may suffice in simple scenarios, in most cases algorithms able to escape local minima are necessary. Configuration-space search algorithms have proven to provide a good trade-off between quality of the solutions and search time. Literature presents a wide variety of approaches that speed up this search by reducing the number of edges that need to be inspected. Much less attention was instead given to reducing the time necessary to evaluate the cost of a single edge. This paper addresses this point by associating edges to motion primitives that prioritize fast collision detection. We show how biarcs can be used as motion primitives that enable fast collision detection, while still providing smooth, tangent continuous paths. The proposed approach does not assume a disc shaped hitbox, making it appealing for all robots with very different width and length or for differential drive robots with active wheels located far from the robot's center.
Ask One More Time: Self-Agreement Improves Reasoning of Language Models in (Almost) All Scenarios
Nov 14, 2023
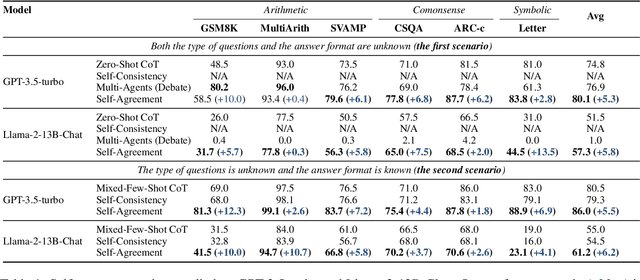

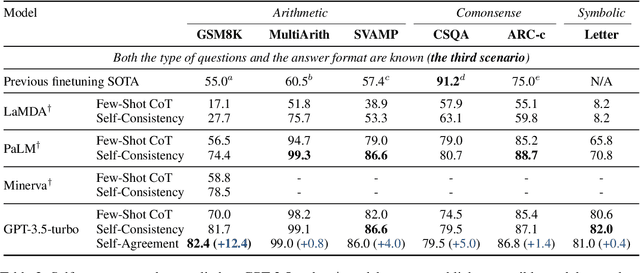
Although chain-of-thought (CoT) prompting combined with language models has achieved encouraging results on complex reasoning tasks, the naive greedy decoding used in CoT prompting usually causes the repetitiveness and local optimality. To address this shortcoming, ensemble-optimization tries to obtain multiple reasoning paths to get the final answer assembly. However, current ensemble-optimization methods either simply employ rule-based post-processing such as \textit{self-consistency}, or train an additional model based on several task-related human annotations to select the best one among multiple reasoning paths, yet fail to generalize to realistic settings where the type of input questions is unknown or the answer format of reasoning paths is unknown. To avoid their limitations, we propose \textbf{self-agreement}, a generalizable ensemble-optimization method applying in almost all scenarios where the type of input questions and the answer format of reasoning paths may be known or unknown. Self-agreement firstly samples from language model's decoder to generate a \textit{diverse} set of reasoning paths, and subsequently prompts the language model \textit{one more time} to determine the optimal answer by selecting the most \textit{agreed} answer among the sampled reasoning paths. Self-agreement simultaneously achieves remarkable performance on six public reasoning benchmarks and superior generalization capabilities.
From Big to Small Without Losing It All: Text Augmentation with ChatGPT for Efficient Sentiment Analysis
Dec 07, 2023In the era of artificial intelligence, data is gold but costly to annotate. The paper demonstrates a groundbreaking solution to this dilemma using ChatGPT for text augmentation in sentiment analysis. We leverage ChatGPT's generative capabilities to create synthetic training data that significantly improves the performance of smaller models, making them competitive with, or even outperforming, their larger counterparts. This innovation enables models to be both efficient and effective, thereby reducing computational cost, inference time, and memory usage without compromising on quality. Our work marks a key advancement in the cost-effective development and deployment of robust sentiment analysis models.
Vehicle Lane Change Prediction based on Knowledge Graph Embeddings and Bayesian Inference
Dec 11, 2023Prediction of vehicle lane change maneuvers has gained a lot of momentum in the last few years. Some recent works focus on predicting a vehicle's intention by predicting its trajectory first. This is not enough, as it ignores the context of the scene and the state of the surrounding vehicles (as they might be risky to the target vehicle). Other works assessed the risk made by the surrounding vehicles only by considering their existence around the target vehicle, or by considering the distance and relative velocities between them and the target vehicle as two separate numerical features. In this work, we propose a solution that leverages Knowledge Graphs (KGs) to anticipate lane changes based on linguistic contextual information in a way that goes well beyond the capabilities of current perception systems. Our solution takes the Time To Collision (TTC) with surrounding vehicles as input to assess the risk on the target vehicle. Moreover, our KG is trained on the HighD dataset using the TransE model to obtain the Knowledge Graph Embeddings (KGE). Then, we apply Bayesian inference on top of the KG using the embeddings learned during training. Finally, the model can predict lane changes two seconds ahead with 97.95% f1-score, which surpassed the state of the art, and three seconds before changing lanes with 93.60% f1-score.
Modyn: A Platform for Model Training on Dynamic Datasets With Sample-Level Data Selection
Dec 11, 2023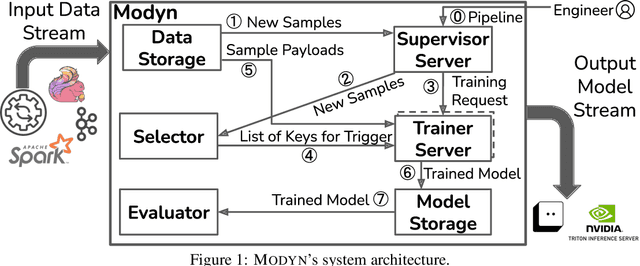

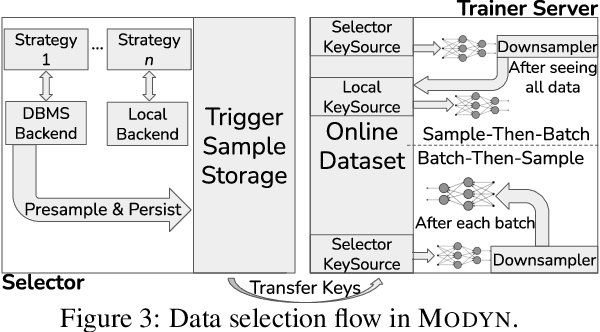
Machine learning training data is often dynamic in real-world use cases, i.e., data is added or removed and may experience distribution shifts over time. Models must incorporate this evolving training data to improve generalization, adapt to potential distribution shifts, and adhere to privacy regulations. However, the cost of model (re)training is proportional to how often the model trains and on how much data it trains on. While ML research explores these topics in isolation, there is no end-to-end open-source platform to facilitate the exploration of model retraining and data selection policies and the deployment these algorithms efficiently at scale. We present Modyn, a platform for model training on dynamic datasets that enables sample-level data selection and triggering policies. Modyn orchestrates continuous training pipelines while optimizing the underlying system infrastructure to support fast access to arbitrary data samples for efficient data selection. Modyn's extensible architecture allows users to run training pipelines without modifying the platform code, and enables researchers to effortlessly extend the system. We evaluate Modyn's training throughput, showing that even in memory-bound recommendation systems workloads, Modyn is able to reach 80 to 100 % of the throughput compared to loading big chunks of data locally without sample-level data selection. Additionally, we showcase Modyn's functionality with three different data selection policies.