 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Golden Gemini is All You Need: Finding the Sweet Spots for Speaker Verification
Dec 06, 2023
Previous studies demonstrate the impressive performance of residual neural networks (ResNet) in speaker verification. The ResNet models treat the time and frequency dimensions equally. They follow the default stride configuration designed for image recognition, where the horizontal and vertical axes exhibit similarities. This approach ignores the fact that time and frequency are asymmetric in speech representation. In this paper, we address this issue and look for optimal stride configurations specifically tailored for speaker verification. We represent the stride space on a trellis diagram, and conduct a systematic study on the impact of temporal and frequency resolutions on the performance and further identify two optimal points, namely Golden Gemini, which serves as a guiding principle for designing 2D ResNet-based speaker verification models. By following the principle, a state-of-the-art ResNet baseline model gains a significant performance improvement on VoxCeleb, SITW, and CNCeleb datasets with 7.70%/11.76% average EER/minDCF reductions, respectively, across different network depths (ResNet18, 34, 50, and 101), while reducing the number of parameters by 16.5% and FLOPs by 4.1%. We refer to it as Gemini ResNet. Further investigation reveals the efficacy of the proposed Golden Gemini operating points across various training conditions and architectures. Furthermore, we present a new benchmark, namely the Gemini DF-ResNet, using a cutting-edge model.
Deep Learning-Based Pilotless Spatial Multiplexing
Dec 08, 2023This paper investigates the feasibility of machine learning (ML)-based pilotless spatial multiplexing in multiple-input and multiple-output (MIMO) communication systems. Especially, it is shown that by training the transmitter and receiver jointly, the transmitter can learn such constellation shapes for the spatial streams which facilitate completely blind separation and detection by the simultaneously learned receiver. To the best of our knowledge, this is the first time ML-based spatial multiplexing without channel estimation pilots is demonstrated. The results show that the learned pilotless scheme can outperform a conventional pilot-based system by as much as 15-20% in terms of spectral efficiency, depending on the modulation order and signal-to-noise ratio.
Interpretable Underwater Diver Gesture Recognition
Dec 08, 2023In recent years, usage and applications of Autonomous Underwater Vehicles has grown rapidly. Interaction of divers with the AUVs remains an integral part of the usage of AUVs for various applications and makes building robust and efficient underwater gesture recognition systems extremely important. In this paper, we propose an Underwater Gesture Recognition system trained on the Cognitive Autonomous Diving Buddy Underwater gesture dataset using deep learning that achieves 98.01\% accuracy on the dataset, which to the best of our knowledge is the best performance achieved on this dataset at the time of writing this paper. We also improve the Gesture Recognition System Interpretability by using XAI techniques to visualize the model's predictions.
A Novel Differentiable Loss Function for Unsupervised Graph Neural Networks in Graph Partitioning
Dec 11, 2023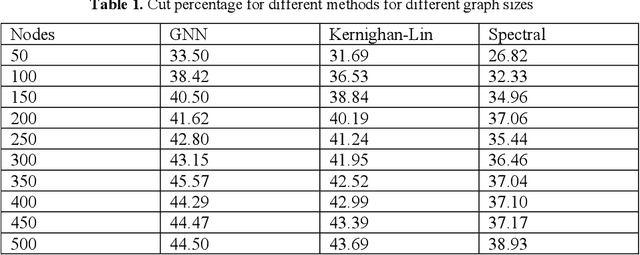
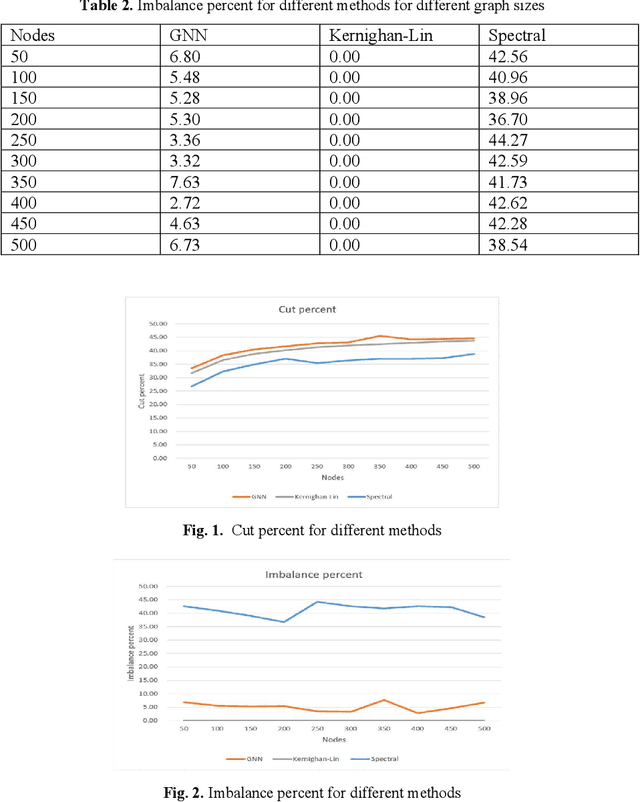
In this paper, we explore the graph partitioning problem, a pivotal combina-torial optimization challenge with extensive applications in various fields such as science, technology, and business. Recognized as an NP-hard prob-lem, graph partitioning lacks polynomial-time algorithms for its resolution. Recently, there has been a burgeoning interest in leveraging machine learn-ing, particularly approaches like supervised, unsupervised, and reinforce-ment learning, to tackle such NP-hard problems. However, these methods face significant hurdles: supervised learning is constrained by the necessity of labeled solution instances, which are often computationally impractical to obtain; reinforcement learning grapples with instability in the learning pro-cess; and unsupervised learning contends with the absence of a differentia-ble loss function, a consequence of the discrete nature of most combinatorial optimization problems. Addressing these challenges, our research introduces a novel pipeline employing an unsupervised graph neural network to solve the graph partitioning problem. The core innovation of this study is the for-mulation of a differentiable loss function tailored for this purpose. We rigor-ously evaluate our methodology against contemporary state-of-the-art tech-niques, focusing on metrics: cuts and balance, and our findings reveal that our is competitive with these leading methods.
Sparse but Strong: Crafting Adversarially Robust Graph Lottery Tickets
Dec 11, 2023Graph Lottery Tickets (GLTs), comprising a sparse adjacency matrix and a sparse graph neural network (GNN), can significantly reduce the inference latency and compute footprint compared to their dense counterparts. Despite these benefits, their performance against adversarial structure perturbations remains to be fully explored. In this work, we first investigate the resilience of GLTs against different structure perturbation attacks and observe that they are highly vulnerable and show a large drop in classification accuracy. Based on this observation, we then present an adversarially robust graph sparsification (ARGS) framework that prunes the adjacency matrix and the GNN weights by optimizing a novel loss function capturing the graph homophily property and information associated with both the true labels of the train nodes and the pseudo labels of the test nodes. By iteratively applying ARGS to prune both the perturbed graph adjacency matrix and the GNN model weights, we can find adversarially robust graph lottery tickets that are highly sparse yet achieve competitive performance under different untargeted training-time structure attacks. Evaluations conducted on various benchmarks, considering different poisoning structure attacks, namely, PGD, MetaAttack, Meta-PGD, and PR-BCD demonstrate that the GLTs generated by ARGS can significantly improve the robustness, even when subjected to high levels of sparsity.
Intraoperative 2D/3D Image Registration via Differentiable X-ray Rendering
Dec 11, 2023Surgical decisions are informed by aligning rapid portable 2D intraoperative images (e.g., X-rays) to a high-fidelity 3D preoperative reference scan (e.g., CT). 2D/3D image registration often fails in practice: conventional optimization methods are prohibitively slow and susceptible to local minima, while neural networks trained on small datasets fail on new patients or require impractical landmark supervision. We present DiffPose, a self-supervised approach that leverages patient-specific simulation and differentiable physics-based rendering to achieve accurate 2D/3D registration without relying on manually labeled data. Preoperatively, a CNN is trained to regress the pose of a randomly oriented synthetic X-ray rendered from the preoperative CT. The CNN then initializes rapid intraoperative test-time optimization that uses the differentiable X-ray renderer to refine the solution. Our work further proposes several geometrically principled methods for sampling camera poses from $\mathbf{SE}(3)$, for sparse differentiable rendering, and for driving registration in the tangent space $\mathfrak{se}(3)$ with geodesic and multiscale locality-sensitive losses. DiffPose achieves sub-millimeter accuracy across surgical datasets at intraoperative speeds, improving upon existing unsupervised methods by an order of magnitude and even outperforming supervised baselines. Our code is available at https://github.com/eigenvivek/DiffPose.
FOSS: A Self-Learned Doctor for Query Optimizer
Dec 11, 2023Various works have utilized deep reinforcement learning (DRL) to address the query optimization problem in database system. They either learn to construct plans from scratch in a bottom-up manner or guide the plan generation behavior of traditional optimizer using hints. While these methods have achieved some success, they face challenges in either low training efficiency or limited plan search space. To address these challenges, we introduce FOSS, a novel DRL-based framework for query optimization. FOSS initiates optimization from the original plan generated by a traditional optimizer and incrementally refines suboptimal nodes of the plan through a sequence of actions. Additionally, we devise an asymmetric advantage model to evaluate the advantage between two plans. We integrate it with a traditional optimizer to form a simulated environment. Leveraging this simulated environment, FOSS can bootstrap itself to rapidly generate a large amount of high-quality simulated experiences. FOSS then learns and improves its optimization capability from these simulated experiences. We evaluate the performance of FOSS on Join Order Benchmark, TPC-DS, and Stack Overflow. The experimental results demonstrate that FOSS outperforms the state-of-the-art methods in terms of latency performance and optimization time. Compared to PostgreSQL, FOSS achieves savings ranging from 15% to 83% in total latency across different benchmarks.
Learning-Based UAV Path Planning for Data Collection with Integrated Collision Avoidance
Dec 11, 2023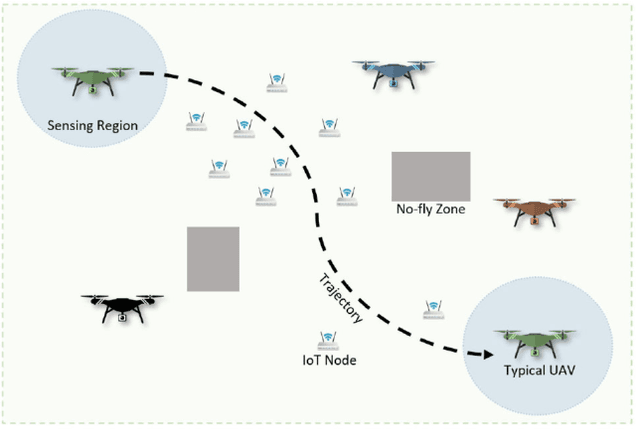
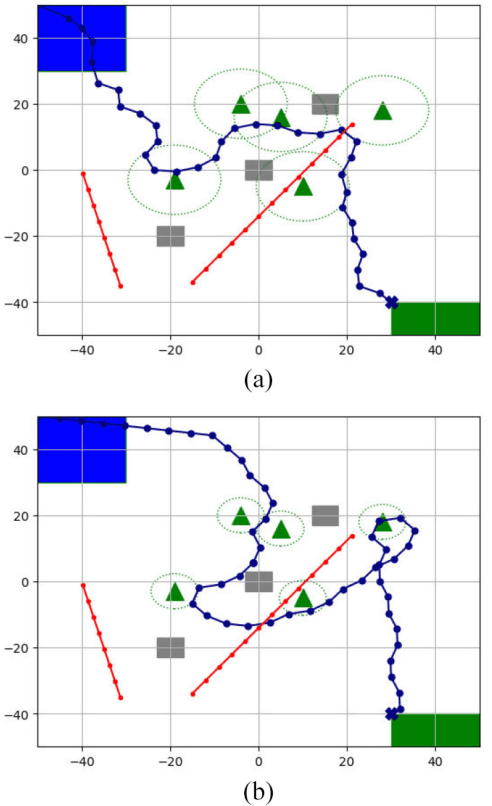
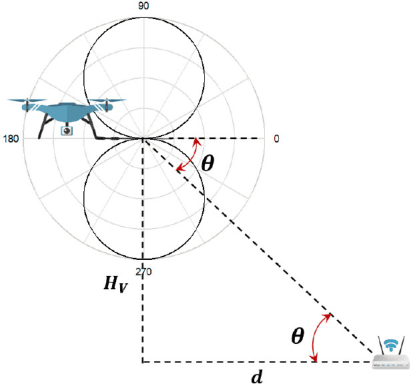
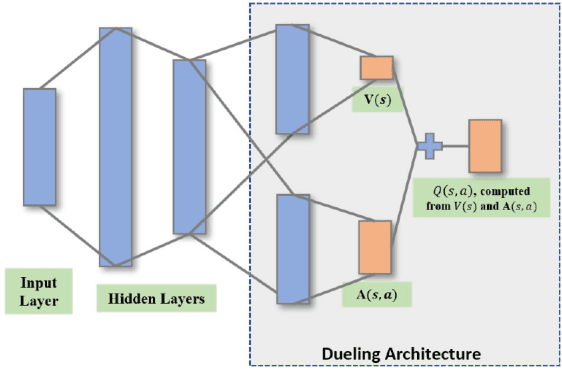
Unmanned aerial vehicles (UAVs) are expected to be an integral part of wireless networks, and determining collision-free trajectory in multi-UAV non-cooperative scenarios while collecting data from distributed Internet of Things (IoT) nodes is a challenging task. In this paper, we consider a path planning optimization problem to maximize the collected data from multiple IoT nodes under realistic constraints. The considered multi-UAV non-cooperative scenarios involve random number of other UAVs in addition to the typical UAV, and UAVs do not communicate or share information among each other. We translate the problem into a Markov decision process (MDP) with parameterized states, permissible actions, and detailed reward functions. Dueling double deep Q-network (D3QN) is proposed to learn the decision making policy for the typical UAV, without any prior knowledge of the environment (e.g., channel propagation model and locations of the obstacles) and other UAVs (e.g., their missions, movements, and policies). The proposed algorithm can adapt to various missions in various scenarios, e.g., different numbers and positions of IoT nodes, different amount of data to be collected, and different numbers and positions of other UAVs. Numerical results demonstrate that real-time navigation can be efficiently performed with high success rate, high data collection rate, and low collision rate.
* The final version of this paper has been accepted in IEEE Internet of Things Journal
Style Injection in Diffusion: A Training-free Approach for Adapting Large-scale Diffusion Models for Style Transfer
Dec 11, 2023Despite the impressive generative capabilities of diffusion models, existing diffusion model-based style transfer methods require inference-stage optimization (e.g. fine-tuning or textual inversion of style) which is time-consuming, or fails to leverage the generative ability of large-scale diffusion models. To address these issues, we introduce a novel artistic style transfer method based on a pre-trained large-scale diffusion model without any optimization. Specifically, we manipulate the features of self-attention layers as the way the cross-attention mechanism works; in the generation process, substituting the key and value of content with those of style image. This approach provides several desirable characteristics for style transfer including 1) preservation of content by transferring similar styles into similar image patches and 2) transfer of style based on similarity of local texture (e.g. edge) between content and style images. Furthermore, we introduce query preservation and attention temperature scaling to mitigate the issue of disruption of original content, and initial latent Adaptive Instance Normalization (AdaIN) to deal with the disharmonious color (failure to transfer the colors of style). Our experimental results demonstrate that our proposed method surpasses state-of-the-art methods in both conventional and diffusion-based style transfer baselines.
RGNet: A Unified Retrieval and Grounding Network for Long Videos
Dec 11, 2023We present a novel end-to-end method for long-form video temporal grounding to locate specific moments described by natural language queries. Prior long-video methods for this task typically contain two stages: proposal selection and grounding regression. However, the proposal selection of these methods is disjoint from the grounding network and is not trained end-to-end, which limits the effectiveness of these methods. Moreover, these methods operate uniformly over the entire temporal window, which is suboptimal given redundant and irrelevant features in long videos. In contrast to these prior approaches, we introduce RGNet, a unified network designed for jointly selecting proposals from hour-long videos and locating moments specified by natural language queries within them. To achieve this, we redefine proposal selection as a video-text retrieval task, i.e., retrieving the correct candidate videos given a text query. The core component of RGNet is a unified cross-modal RG-Encoder that bridges the two stages with shared features and mutual optimization. The encoder strategically focuses on relevant time frames using a sparse sampling technique. RGNet outperforms previous methods, demonstrating state-of-the-art performance on long video temporal grounding datasets MAD and Ego4D. The code is released at https://github.com/Tanveer81/RGNet