 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Novel Differentiable Loss Function for Unsupervised Graph Neural Networks in Graph Partitioning
Dec 11, 2023
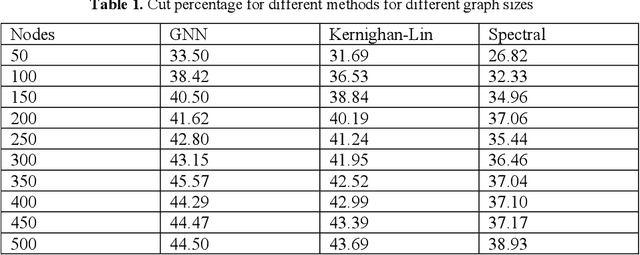
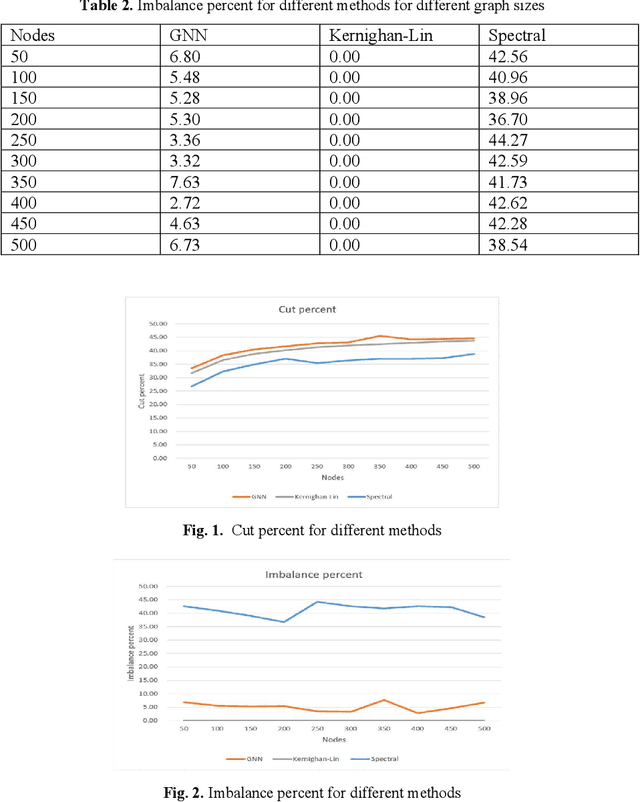
In this paper, we explore the graph partitioning problem, a pivotal combina-torial optimization challenge with extensive applications in various fields such as science, technology, and business. Recognized as an NP-hard prob-lem, graph partitioning lacks polynomial-time algorithms for its resolution. Recently, there has been a burgeoning interest in leveraging machine learn-ing, particularly approaches like supervised, unsupervised, and reinforce-ment learning, to tackle such NP-hard problems. However, these methods face significant hurdles: supervised learning is constrained by the necessity of labeled solution instances, which are often computationally impractical to obtain; reinforcement learning grapples with instability in the learning pro-cess; and unsupervised learning contends with the absence of a differentia-ble loss function, a consequence of the discrete nature of most combinatorial optimization problems. Addressing these challenges, our research introduces a novel pipeline employing an unsupervised graph neural network to solve the graph partitioning problem. The core innovation of this study is the for-mulation of a differentiable loss function tailored for this purpose. We rigor-ously evaluate our methodology against contemporary state-of-the-art tech-niques, focusing on metrics: cuts and balance, and our findings reveal that our is competitive with these leading methods.
Sparse but Strong: Crafting Adversarially Robust Graph Lottery Tickets
Dec 11, 2023Graph Lottery Tickets (GLTs), comprising a sparse adjacency matrix and a sparse graph neural network (GNN), can significantly reduce the inference latency and compute footprint compared to their dense counterparts. Despite these benefits, their performance against adversarial structure perturbations remains to be fully explored. In this work, we first investigate the resilience of GLTs against different structure perturbation attacks and observe that they are highly vulnerable and show a large drop in classification accuracy. Based on this observation, we then present an adversarially robust graph sparsification (ARGS) framework that prunes the adjacency matrix and the GNN weights by optimizing a novel loss function capturing the graph homophily property and information associated with both the true labels of the train nodes and the pseudo labels of the test nodes. By iteratively applying ARGS to prune both the perturbed graph adjacency matrix and the GNN model weights, we can find adversarially robust graph lottery tickets that are highly sparse yet achieve competitive performance under different untargeted training-time structure attacks. Evaluations conducted on various benchmarks, considering different poisoning structure attacks, namely, PGD, MetaAttack, Meta-PGD, and PR-BCD demonstrate that the GLTs generated by ARGS can significantly improve the robustness, even when subjected to high levels of sparsity.
Orchestrated Robust Controller for the Precision Control of Heavy-duty Hydraulic Manipulators
Dec 11, 2023Vast industrial investment along with increased academic research on hydraulic heavy-duty manipulators has unavoidably paved the way for their automatization, necessitating the design of robust and high-precision controllers. In this study, an orchestrated robust controller is designed to address the mentioned issue. To do so, the entire robotic system is decomposed into subsystems, and a robust controller is designed at each local subsystem by considering unknown model uncertainties, unknown disturbances, and compound input constraints, thanks to virtual decomposition control (VDC). As such, radial basic function neural networks (RBFNNs) are incorporated into VDC to tackle unknown disturbances and uncertainties, resulting in novel decentralized RBFNNs. All these robust local controllers designed at each local subsystem are, then, orchestrated to accomplish high-precision control. In the end, for the first time in the context of VDC, a semi-globally uniformly ultimate boundedness is achieved under the designed controller. The validity of the theoretical results is verified by performing extensive simulations and experiments on a 6-degrees-of-freedom industrial manipulator with a nominal lifting capacity of $600\, kg$ at $5$ meters reach. Comparing the simulation result to state-of-the-art controller along with provided experimental results, demonstrates that the proposed method established all the promises and performed excellently.
Development of the Lifelike Head Unit for a Humanoid Cybernetic Avatar `Yui' and Its Operation Interface
Dec 11, 2023In the context of avatar-mediated communication, it is crucial for the face-to-face interlocutor to sense the operator's presence and emotions via the avatar. Although androids resembling humans have been developed to convey presence through appearance and movement, few studies have prioritized deepening the communication experience for both operator and interlocutor using android robot as an avatar. Addressing this gap, we introduce the ``Cybernetic Avatar `Yui','' featuring a human-like head unit with 28 degrees of freedom, capable of expressing gaze, facial emotions, and speech-related mouth movements. Through an eye-tracking unit in a Head-Mounted Display (HMD) and degrees of freedom on both eyes of Yui, operators can control the avatar's gaze naturally. Additionally, microphones embedded in Yui's ears allow operators to hear surrounding sounds in three dimensions, enabling them to discern the direction of calls based solely on auditory information. An HMD's face-tracking unit synchronizes the avatar's facial movements with those of the operator. This immersive interface, coupled with Yui's human-like appearance, enables real-time emotion transmission and communication, enhancing the sense of presence for both parties. Our experiments demonstrate Yui's facial expression capabilities, and validate the system's efficacy through teleoperation trials, suggesting potential advancements in avatar technology.
Style Transfer to Calvin and Hobbes comics using Stable Diffusion
Dec 07, 2023This project report summarizes our journey to perform stable diffusion fine-tuning on a dataset containing Calvin and Hobbes comics. The purpose is to convert any given input image into the comic style of Calvin and Hobbes, essentially performing style transfer. We train stable-diffusion-v1.5 using Low Rank Adaptation (LoRA) to efficiently speed up the fine-tuning process. The diffusion itself is handled by a Variational Autoencoder (VAE), which is a U-net. Our results were visually appealing for the amount of training time and the quality of input data that went into training.
Batched Low-Rank Adaptation of Foundation Models
Dec 09, 2023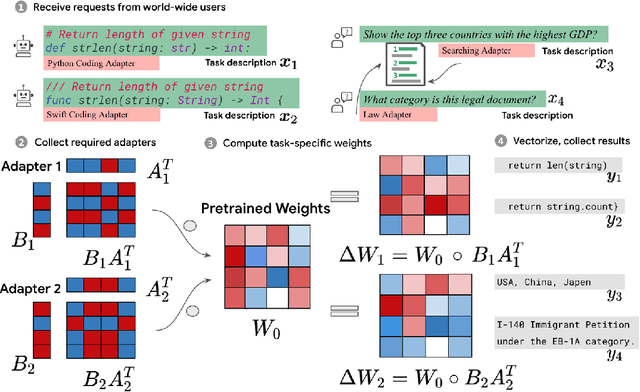
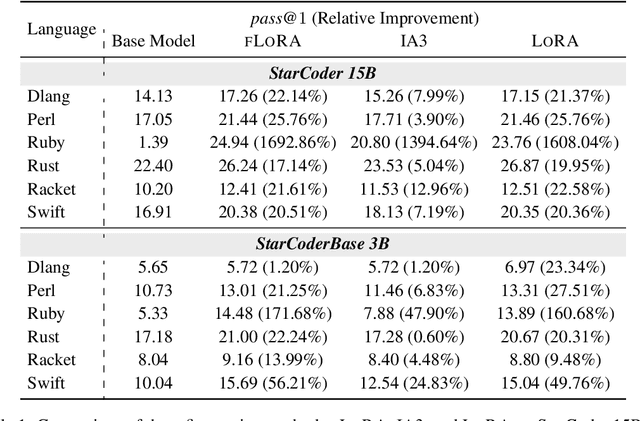
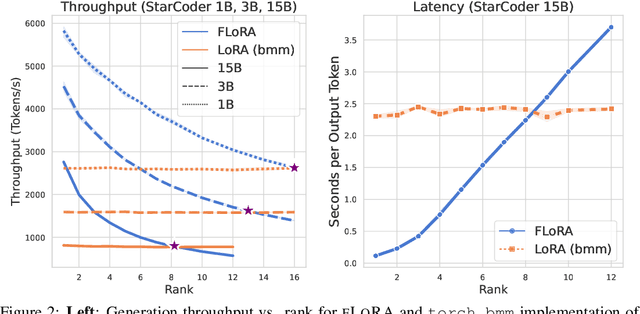

Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Position control of an acoustic cavitation bubble by reinforcement learning
Dec 09, 2023A control technique is developed via Reinforcement Learning that allows arbitrary controlling of the position of an acoustic cavitation bubble in a dual-frequency standing acoustic wave field. The agent must choose the optimal pressure amplitude values to manipulate the bubble position in the range of $x/\lambda_0\in[0.05, 0.25]$. To train the agent an actor-critic off-policy algorithm (Deep Deterministic Policy Gradient) was used that supports continuous action space, which allows setting the pressure amplitude values continuously within $0$ and $1\, \mathrm{bar}$. A shaped reward function is formulated that minimizes the distance between the bubble and the target position and implicitly encourages the agent to perform the position control within the shortest amount of time. In some cases, the optimal control can be 7 times faster than the solution expected from the linear theory.
Long-Term Rate-Fairness-Aware Beamforming Based Massive MIMO Systems
Dec 09, 2023This is the first treatise on multi-user (MU) beamforming designed for achieving long-term rate-fairness in fulldimensional MU massive multi-input multi-output (m-MIMO) systems. Explicitly, based on the channel covariances, which can be assumed to be known beforehand, we address this problem by optimizing the following objective functions: the users' signal-toleakage-noise ratios (SLNRs) using SLNR max-min optimization, geometric mean of SLNRs (GM-SLNR) based optimization, and SLNR soft max-min optimization. We develop a convex-solver based algorithm, which invokes a convex subproblem of cubic time-complexity at each iteration for solving the SLNR maxmin problem. We then develop closed-form expression based algorithms of scalable complexity for the solution of the GMSLNR and of the SLNR soft max-min problem. The simulations provided confirm the users' improved-fairness ergodic rate distributions.
Optimization-Free Test-Time Adaptation for Cross-Person Activity Recognition
Oct 28, 2023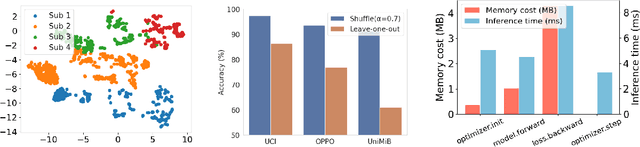
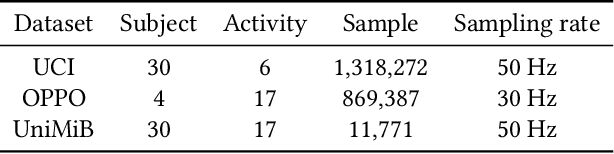


Human Activity Recognition (HAR) models often suffer from performance degradation in real-world applications due to distribution shifts in activity patterns across individuals. Test-Time Adaptation (TTA) is an emerging learning paradigm that aims to utilize the test stream to adjust predictions in real-time inference, which has not been explored in HAR before. However, the high computational cost of optimization-based TTA algorithms makes it intractable to run on resource-constrained edge devices. In this paper, we propose an Optimization-Free Test-Time Adaptation (OFTTA) framework for sensor-based HAR. OFTTA adjusts the feature extractor and linear classifier simultaneously in an optimization-free manner. For the feature extractor, we propose Exponential DecayTest-time Normalization (EDTN) to replace the conventional batch normalization (CBN) layers. EDTN combines CBN and Test-time batch Normalization (TBN) to extract reliable features against domain shifts with TBN's influence decreasing exponentially in deeper layers. For the classifier, we adjust the prediction by computing the distance between the feature and the prototype, which is calculated by a maintained support set. In addition, the update of the support set is based on the pseudo label, which can benefit from reliable features extracted by EDTN. Extensive experiments on three public cross-person HAR datasets and two different TTA settings demonstrate that OFTTA outperforms the state-of-the-art TTA approaches in both classification performance and computational efficiency. Finally, we verify the superiority of our proposed OFTTA on edge devices, indicating possible deployment in real applications. Our code is available at \href{https://github.com/Claydon-Wang/OFTTA}{this https URL}.
Deep Learning-Based Pilotless Spatial Multiplexing
Dec 08, 2023This paper investigates the feasibility of machine learning (ML)-based pilotless spatial multiplexing in multiple-input and multiple-output (MIMO) communication systems. Especially, it is shown that by training the transmitter and receiver jointly, the transmitter can learn such constellation shapes for the spatial streams which facilitate completely blind separation and detection by the simultaneously learned receiver. To the best of our knowledge, this is the first time ML-based spatial multiplexing without channel estimation pilots is demonstrated. The results show that the learned pilotless scheme can outperform a conventional pilot-based system by as much as 15-20% in terms of spectral efficiency, depending on the modulation order and signal-to-noise ratio.