 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explosive Legged Robotic Hopping: Energy Accumulation and Power Amplification via Pneumatic Augmentation
Dec 10, 2023
We present a novel pneumatic augmentation to traditional electric motor-actuated legged robot to increase intermittent power density to perform infrequent explosive hopping behaviors. The pneumatic system is composed of a pneumatic pump, a tank, and a pneumatic actuator. The tank is charged up by the pump during regular hopping motion that is created by the electric motors. At any time after reaching a desired air pressure in the tank, a solenoid valve is utilized to rapidly release the air pressure to the pneumatic actuator (piston) which is used in conjunction with the electric motors to perform explosive hopping, increasing maximum hopping height for one or subsequent cycles. We show that, on a custom-designed one-legged hopping robot, without any additional power source and with this novel pneumatic augmentation system, their associated system identification and optimal control, the robot is able to realize highly explosive hopping with power amplification per cycle by a factor of approximately 5.4 times the power of electric motor actuation alone.
Separate-and-Enhance: Compositional Finetuning for Text2Image Diffusion Models
Dec 10, 2023Despite recent significant strides achieved by diffusion-based Text-to-Image (T2I) models, current systems are still less capable of ensuring decent compositional generation aligned with text prompts, particularly for the multi-object generation. This work illuminates the fundamental reasons for such misalignment, pinpointing issues related to low attention activation scores and mask overlaps. While previous research efforts have individually tackled these issues, we assert that a holistic approach is paramount. Thus, we propose two novel objectives, the Separate loss and the Enhance loss, that reduce object mask overlaps and maximize attention scores, respectively. Our method diverges from conventional test-time-adaptation techniques, focusing on finetuning critical parameters, which enhances scalability and generalizability. Comprehensive evaluations demonstrate the superior performance of our model in terms of image realism, text-image alignment, and adaptability, notably outperforming prominent baselines. Ultimately, this research paves the way for T2I diffusion models with enhanced compositional capacities and broader applicability. The project webpage is available at https://zpbao.github.io/projects/SepEn/.
Language-Informed Visual Concept Learning
Dec 06, 2023Our understanding of the visual world is centered around various concept axes, characterizing different aspects of visual entities. While different concept axes can be easily specified by language, e.g. color, the exact visual nuances along each axis often exceed the limitations of linguistic articulations, e.g. a particular style of painting. In this work, our goal is to learn a language-informed visual concept representation, by simply distilling large pre-trained vision-language models. Specifically, we train a set of concept encoders to encode the information pertinent to a set of language-informed concept axes, with an objective of reproducing the input image through a pre-trained Text-to-Image (T2I) model. To encourage better disentanglement of different concept encoders, we anchor the concept embeddings to a set of text embeddings obtained from a pre-trained Visual Question Answering (VQA) model. At inference time, the model extracts concept embeddings along various axes from new test images, which can be remixed to generate images with novel compositions of visual concepts. With a lightweight test-time finetuning procedure, it can also generalize to novel concepts unseen at training.
Encoding Surgical Videos as Latent Spatiotemporal Graphs for Object and Anatomy-Driven Reasoning
Dec 11, 2023Recently, spatiotemporal graphs have emerged as a concise and elegant manner of representing video clips in an object-centric fashion, and have shown to be useful for downstream tasks such as action recognition. In this work, we investigate the use of latent spatiotemporal graphs to represent a surgical video in terms of the constituent anatomical structures and tools and their evolving properties over time. To build the graphs, we first predict frame-wise graphs using a pre-trained model, then add temporal edges between nodes based on spatial coherence and visual and semantic similarity. Unlike previous approaches, we incorporate long-term temporal edges in our graphs to better model the evolution of the surgical scene and increase robustness to temporary occlusions. We also introduce a novel graph-editing module that incorporates prior knowledge and temporal coherence to correct errors in the graph, enabling improved downstream task performance. Using our graph representations, we evaluate two downstream tasks, critical view of safety prediction and surgical phase recognition, obtaining strong results that demonstrate the quality and flexibility of the learned representations. Code is available at github.com/CAMMA-public/SurgLatentGraph.
ControlNet-XS: Designing an Efficient and Effective Architecture for Controlling Text-to-Image Diffusion Models
Dec 11, 2023The field of image synthesis has made tremendous strides forward in the last years. Besides defining the desired output image with text-prompts, an intuitive approach is to additionally use spatial guidance in form of an image, such as a depth map. For this, a recent and highly popular approach is to use a controlling network, such as ControlNet, in combination with a pre-trained image generation model, such as Stable Diffusion. When evaluating the design of existing controlling networks, we observe that they all suffer from the same problem of a delay in information flowing between the generation and controlling process. This, in turn, means that the controlling network must have generative capabilities. In this work we propose a new controlling architecture, called ControlNet-XS, which does not suffer from this problem, and hence can focus on the given task of learning to control. In contrast to ControlNet, our model needs only a fraction of parameters, and hence is about twice as fast during inference and training time. Furthermore, the generated images are of higher quality and the control is of higher fidelity. All code and pre-trained models will be made publicly available.
Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual Segmentation
Dec 11, 2023Recently, an audio-visual segmentation (AVS) task has been introduced, aiming to group pixels with sounding objects within a given video. This task necessitates a first-ever audio-driven pixel-level understanding of the scene, posing significant challenges. In this paper, we propose an innovative audio-visual transformer framework, termed COMBO, an acronym for COoperation of Multi-order Bilateral relatiOns. For the first time, our framework explores three types of bilateral entanglements within AVS: pixel entanglement, modality entanglement, and temporal entanglement. Regarding pixel entanglement, we employ a Siam-Encoder Module (SEM) that leverages prior knowledge to generate more precise visual features from the foundational model. For modality entanglement, we design a Bilateral-Fusion Module (BFM), enabling COMBO to align corresponding visual and auditory signals bi-directionally. As for temporal entanglement, we introduce an innovative adaptive inter-frame consistency loss according to the inherent rules of temporal. Comprehensive experiments and ablation studies on AVSBench-object (84.7 mIoU on S4, 59.2 mIou on MS3) and AVSBench-semantic (42.1 mIoU on AVSS) datasets demonstrate that COMBO surpasses previous state-of-the-art methods. Code and more results will be publicly available at https://combo-avs.github.io/.
Detecting Contextual Network Anomalies with Graph Neural Networks
Dec 11, 2023Detecting anomalies on network traffic is a complex task due to the massive amount of traffic flows in today's networks, as well as the highly-dynamic nature of traffic over time. In this paper, we propose the use of Graph Neural Networks (GNN) for network traffic anomaly detection. We formulate the problem as contextual anomaly detection on network traffic measurements, and propose a custom GNN-based solution that detects traffic anomalies on origin-destination flows. In our evaluation, we use real-world data from Abilene (6 months), and make a comparison with other widely used methods for the same task (PCA, EWMA, RNN). The results show that the anomalies detected by our solution are quite complementary to those captured by the baselines (with a max. of 36.33% overlapping anomalies for PCA). Moreover, we manually inspect the anomalies detected by our method, and find that a large portion of them can be visually validated by a network expert (64% with high confidence, 18% with mid confidence, 18% normal traffic). Lastly, we analyze the characteristics of the anomalies through two paradigmatic cases that are quite representative of the bulk of anomalies.
EgoPlan-Bench: Benchmarking Egocentric Embodied Planning with Multimodal Large Language Models
Dec 11, 2023
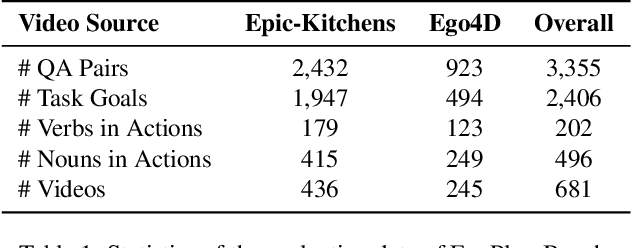
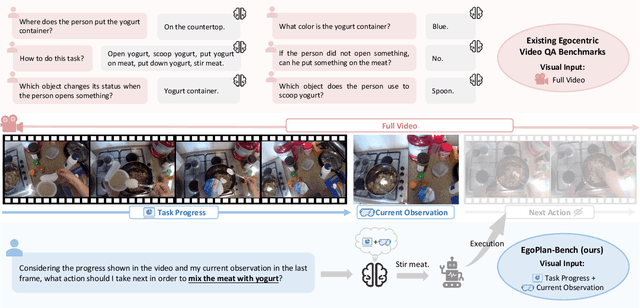
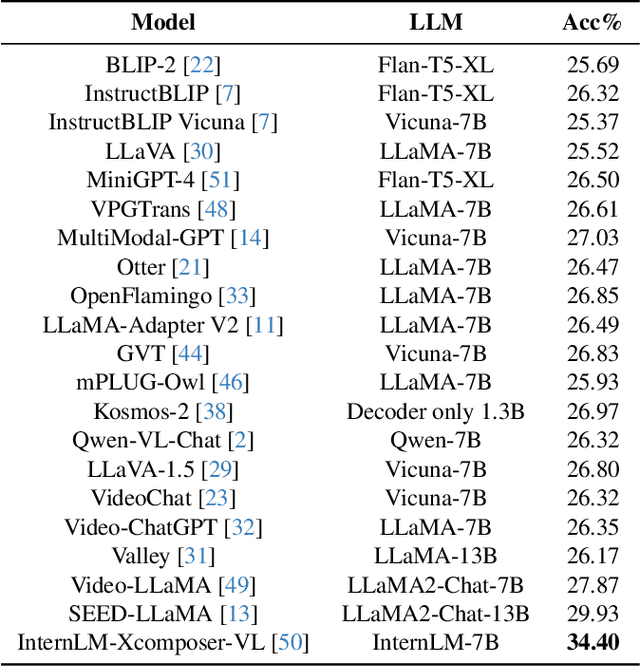
Multimodal Large Language Models (MLLMs), building upon the powerful Large Language Models (LLMs) with exceptional reasoning and generalization capability, have opened up new avenues for embodied task planning. MLLMs excel in their ability to integrate diverse environmental inputs, such as real-time task progress, visual observations, and open-form language instructions, which are crucial for executable task planning. In this work, we introduce a benchmark with human annotations, EgoPlan-Bench, to quantitatively investigate the potential of MLLMs as embodied task planners in real-world scenarios. Our benchmark is distinguished by realistic tasks derived from real-world videos, a diverse set of actions involving interactions with hundreds of different objects, and complex visual observations from varied environments. We evaluate various open-source MLLMs, revealing that these models have not yet evolved into embodied planning generalists (even GPT-4V). We further construct an instruction-tuning dataset EgoPlan-IT from videos of human-object interactions, to facilitate the learning of high-level task planning in intricate real-world situations. The experiment results demonstrate that the model tuned on EgoPlan-IT not only significantly improves performance on our benchmark, but also effectively acts as embodied planner in simulations.
DMS*: Minimizing Makespan for Multi-Agent Combinatorial Path Finding
Dec 11, 2023Multi-Agent Combinatorial Path Finding (MCPF) seeks collision-free paths for multiple agents from their initial to goal locations, while visiting a set of intermediate target locations in the middle of the paths. MCPF is challenging as it involves both planning collision-free paths for multiple agents and target sequencing, i.e., solving traveling salesman problems to assign targets to and find the visiting order for the agents. Recent work develops methods to address MCPF while minimizing the sum of individual arrival times at goals. Such a problem formulation may result in paths with different arrival times and lead to a long makespan, the maximum arrival time, among the agents. This paper proposes a min-max variant of MCPF, denoted as MCPF-max, that minimizes the makespan of the agents. While the existing methods (such as MS*) for MCPF can be adapted to solve MCPF-max, we further develop two new techniques based on MS* to defer the expensive target sequencing during planning to expedite the overall computation. We analyze the properties of the resulting algorithm Deferred MS* (DMS*), and test DMS* with up to 20 agents and 80 targets. We demonstrate the use of DMS* on differential-drive robots.
GauHuman: Articulated Gaussian Splatting from Monocular Human Videos
Dec 05, 2023We present, GauHuman, a 3D human model with Gaussian Splatting for both fast training (1 ~ 2 minutes) and real-time rendering (up to 189 FPS), compared with existing NeRF-based implicit representation modelling frameworks demanding hours of training and seconds of rendering per frame. Specifically, GauHuman encodes Gaussian Splatting in the canonical space and transforms 3D Gaussians from canonical space to posed space with linear blend skinning (LBS), in which effective pose and LBS refinement modules are designed to learn fine details of 3D humans under negligible computational cost. Moreover, to enable fast optimization of GauHuman, we initialize and prune 3D Gaussians with 3D human prior, while splitting/cloning via KL divergence guidance, along with a novel merge operation for further speeding up. Extensive experiments on ZJU_Mocap and MonoCap datasets demonstrate that GauHuman achieves state-of-the-art performance quantitatively and qualitatively with fast training and real-time rendering speed. Notably, without sacrificing rendering quality, GauHuman can fast model the 3D human performer with ~13k 3D Gaussians.