 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
Dec 03, 2023
Neural Radiance Fields (NeRFs) excel in photorealistically rendering static scenes. However, rendering dynamic, long-duration radiance fields on ubiquitous devices remains challenging, due to data storage and computational constraints. In this paper, we introduce VideoRF, the first approach to enable real-time streaming and rendering of dynamic radiance fields on mobile platforms. At the core is a serialized 2D feature image stream representing the 4D radiance field all in one. We introduce a tailored training scheme directly applied to this 2D domain to impose the temporal and spatial redundancy of the feature image stream. By leveraging the redundancy, we show that the feature image stream can be efficiently compressed by 2D video codecs, which allows us to exploit video hardware accelerators to achieve real-time decoding. On the other hand, based on the feature image stream, we propose a novel rendering pipeline for VideoRF, which has specialized space mappings to query radiance properties efficiently. Paired with a deferred shading model, VideoRF has the capability of real-time rendering on mobile devices thanks to its efficiency. We have developed a real-time interactive player that enables online streaming and rendering of dynamic scenes, offering a seamless and immersive free-viewpoint experience across a range of devices, from desktops to mobile phones.
Test-time Augmentation for Factual Probing
Oct 26, 2023Factual probing is a method that uses prompts to test if a language model "knows" certain world knowledge facts. A problem in factual probing is that small changes to the prompt can lead to large changes in model output. Previous work aimed to alleviate this problem by optimizing prompts via text mining or fine-tuning. However, such approaches are relation-specific and do not generalize to unseen relation types. Here, we propose to use test-time augmentation (TTA) as a relation-agnostic method for reducing sensitivity to prompt variations by automatically augmenting and ensembling prompts at test time. Experiments show improved model calibration, i.e., with TTA, model confidence better reflects prediction accuracy. Improvements in prediction accuracy are observed for some models, but for other models, TTA leads to degradation. Error analysis identifies the difficulty of producing high-quality prompt variations as the main challenge for TTA.
NearbyPatchCL: Leveraging Nearby Patches for Self-Supervised Patch-Level Multi-Class Classification in Whole-Slide Images
Dec 12, 2023Whole-slide image (WSI) analysis plays a crucial role in cancer diagnosis and treatment. In addressing the demands of this critical task, self-supervised learning (SSL) methods have emerged as a valuable resource, leveraging their efficiency in circumventing the need for a large number of annotations, which can be both costly and time-consuming to deploy supervised methods. Nevertheless, patch-wise representation may exhibit instability in performance, primarily due to class imbalances stemming from patch selection within WSIs. In this paper, we introduce Nearby Patch Contrastive Learning (NearbyPatchCL), a novel self-supervised learning method that leverages nearby patches as positive samples and a decoupled contrastive loss for robust representation learning. Our method demonstrates a tangible enhancement in performance for downstream tasks involving patch-level multi-class classification. Additionally, we curate a new dataset derived from WSIs sourced from the Canine Cutaneous Cancer Histology, thus establishing a benchmark for the rigorous evaluation of patch-level multi-class classification methodologies. Intensive experiments show that our method significantly outperforms the supervised baseline and state-of-the-art SSL methods with top-1 classification accuracy of 87.56%. Our method also achieves comparable results while utilizing a mere 1% of labeled data, a stark contrast to the 100% labeled data requirement of other approaches. Source code: https://github.com/nvtien457/NearbyPatchCL
Privacy-Aware Energy Consumption Modeling of Connected Battery Electric Vehicles using Federated Learning
Dec 12, 2023Battery Electric Vehicles (BEVs) are increasingly significant in modern cities due to their potential to reduce air pollution. Precise and real-time estimation of energy consumption for them is imperative for effective itinerary planning and optimizing vehicle systems, which can reduce driving range anxiety and decrease energy costs. As public awareness of data privacy increases, adopting approaches that safeguard data privacy in the context of BEV energy consumption modeling is crucial. Federated Learning (FL) is a promising solution mitigating the risk of exposing sensitive information to third parties by allowing local data to remain on devices and only sharing model updates with a central server. Our work investigates the potential of using FL methods, such as FedAvg, and FedPer, to improve BEV energy consumption prediction while maintaining user privacy. We conducted experiments using data from 10 BEVs under simulated real-world driving conditions. Our results demonstrate that the FedAvg-LSTM model achieved a reduction of up to 67.84\% in the MAE value of the prediction results. Furthermore, we explored various real-world scenarios and discussed how FL methods can be employed in those cases. Our findings show that FL methods can effectively improve the performance of BEV energy consumption prediction while maintaining user privacy.
Momentum Particle Maximum Likelihood
Dec 12, 2023Maximum likelihood estimation (MLE) of latent variable models is often recast as an optimization problem over the extended space of parameters and probability distributions. For example, the Expectation Maximization (EM) algorithm can be interpreted as coordinate descent applied to a suitable free energy functional over this space. Recently, this perspective has been combined with insights from optimal transport and Wasserstein gradient flows to develop particle-based algorithms applicable to wider classes of models than standard EM. Drawing inspiration from prior works which interpret `momentum-enriched' optimisation algorithms as discretizations of ordinary differential equations, we propose an analogous dynamical systems-inspired approach to minimizing the free energy functional over the extended space of parameters and probability distributions. The result is a dynamic system that blends elements of Nesterov's Accelerated Gradient method, the underdamped Langevin diffusion, and particle methods. Under suitable assumptions, we establish quantitative convergence of the proposed system to the unique minimiser of the functional in continuous time. We then propose a numerical discretization of this system which enables its application to parameter estimation in latent variable models. Through numerical experiments, we demonstrate that the resulting algorithm converges faster than existing methods and compares favourably with other (approximate) MLE algorithms.
Permutation Entropy as a Conceptual Model to Analyse Brain Activity in Sleep
Dec 12, 2023Sleep stage classification is a widely discussed topic, due to its importance in the diagnosis of sleep disorders, e.g. insomnia. Analysis of the brain activity during sleep is necessary to gain further insight into the processing that occurs in our brains. We want to use permutation entropy as a model for this analysis. Therefore, the signal processing in terms of electroencephalography is described. This results in a time discrete signal, that can be further processed by applying the method of permutation entropy, which is a modification of the Shannon entropy as a measure of information processing. The method is applied to 18 data sets, nine electroencephalography measurements of patients suffering from insomnia and nine of people without a sleep disorder. A strong correlation between the permutation entropy value and the sleep stages was found during the simulation runs. The results are analysed and presented using boxplot diagrams of the permutation entropy over the sleep stages. Furthermore, it is investigated that there is a steady decrease in the value when the patient is in a deeper sleep. This suggests that the method is a good parameter for sleep stage classification. Finally, we propose an extension of the conceptual model to other pathological conditions and also to the analysis of brain activity during surgery.
DGNet: Dynamic Gradient-guided Network with Noise Suppression for Underwater Image Enhancement
Dec 12, 2023Underwater image enhancement (UIE) is a challenging task due to the complex degradation caused by underwater environments. To solve this issue, previous methods often idealize the degradation process, and neglect the impact of medium noise and object motion on the distribution of image features, limiting the generalization and adaptability of the model. Previous methods use the reference gradient that is constructed from original images and synthetic ground-truth images. This may cause the network performance to be influenced by some low-quality training data. Our approach utilizes predicted images to dynamically update pseudo-labels, adding a dynamic gradient to optimize the network's gradient space. This process improves image quality and avoids local optima. Moreover, we propose a Feature Restoration and Reconstruction module (FRR) based on a Channel Combination Inference (CCI) strategy and a Frequency Domain Smoothing module (FRS). These modules decouple other degradation features while reducing the impact of various types of noise on network performance. Experiments on multiple public datasets demonstrate the superiority of our method over existing state-of-the-art approaches, especially in achieving performance milestones: PSNR of 25.6dB and SSIM of 0.93 on the UIEB dataset. Its efficiency in terms of parameter size and inference time further attests to its broad practicality. The code will be made publicly available.
Multi-Modal Conformal Prediction Regions by Optimizing Convex Shape Templates
Dec 12, 2023Conformal prediction is a statistical tool for producing prediction regions for machine learning models that are valid with high probability. A key component of conformal prediction algorithms is a non-conformity score function that quantifies how different a model's prediction is from the unknown ground truth value. Essentially, these functions determine the shape and the size of the conformal prediction regions. However, little work has gone into finding non-conformity score functions that produce prediction regions that are multi-modal and practical, i.e., that can efficiently be used in engineering applications. We propose a method that optimizes parameterized shape template functions over calibration data, which results in non-conformity score functions that produce prediction regions with minimum volume. Our approach results in prediction regions that are multi-modal, so they can properly capture residuals of distributions that have multiple modes, and practical, so each region is convex and can be easily incorporated into downstream tasks, such as a motion planner using conformal prediction regions. Our method applies to general supervised learning tasks, while we illustrate its use in time-series prediction. We provide a toolbox and present illustrative case studies of F16 fighter jets and autonomous vehicles, showing an up to $68\%$ reduction in prediction region area.
Minimizing Robot Digging Times to Retrieve Bins in Robotic-Based Compact Storage and Retrieval Systems
Dec 08, 2023Robotic-based compact storage and retrieval systems provide high-density storage in distribution center and warehouse applications. In the system, items are stored in bins, and the bins are organized inside a three-dimensional grid. Robots move on top of the grid to retrieve and deliver bins. To retrieve a bin, a robot removes all bins above one by one with its gripper, called bin digging. The closer the target bin is to the top of the grid, the less digging is required to retrieve the bin. In this paper, we propose a policy to optimally arrange the bins in the grid while processing bin requests so that the most frequently accessed bins remain near the top of the grid. This improves the performance of the system and makes it responsive to changes in bin demand. Our solution approach identifies the optimal bin arrangement in the storage facility, initiates a transition to this optimal set-up, and subsequently ensures the ongoing maintenance of this arrangement for optimal performance. We perform extensive simulations on a custom-built discrete event model of the system. Our simulation results show that under the proposed policy more than half of the bins requested are located on top of the grid, reducing bin digging compared to existing policies. Compared to existing approaches, the proposed policy reduces the retrieval time of the requested bins by over 30% and the number of bin requests that exceed certain time thresholds by nearly 50%.
A Video is Worth 256 Bases: Spatial-Temporal Expectation-Maximization Inversion for Zero-Shot Video Editing
Dec 10, 2023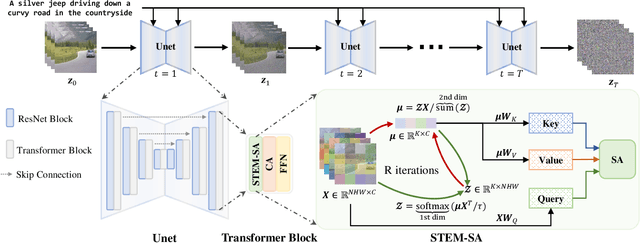
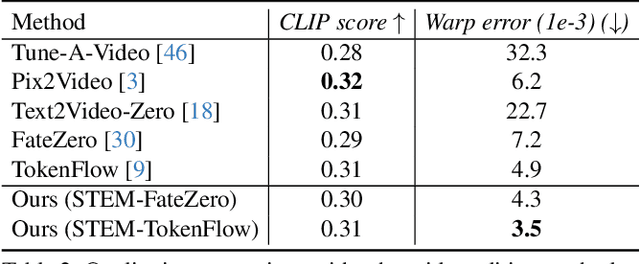


This paper presents a video inversion approach for zero-shot video editing, which aims to model the input video with low-rank representation during the inversion process. The existing video editing methods usually apply the typical 2D DDIM inversion or na\"ive spatial-temporal DDIM inversion before editing, which leverages time-varying representation for each frame to derive noisy latent. Unlike most existing approaches, we propose a Spatial-Temporal Expectation-Maximization (STEM) inversion, which formulates the dense video feature under an expectation-maximization manner and iteratively estimates a more compact basis set to represent the whole video. Each frame applies the fixed and global representation for inversion, which is more friendly for temporal consistency during reconstruction and editing. Extensive qualitative and quantitative experiments demonstrate that our STEM inversion can achieve consistent improvement on two state-of-the-art video editing methods.