 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
READ-PVLA: Recurrent Adapter with Partial Video-Language Alignment for Parameter-Efficient Transfer Learning in Low-Resource Video-Language Modeling
Dec 12, 2023

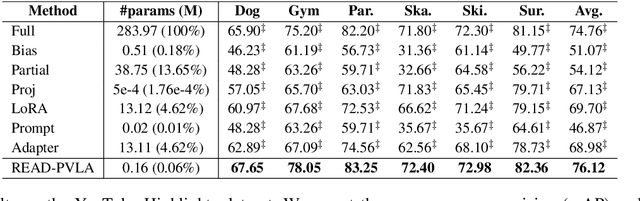
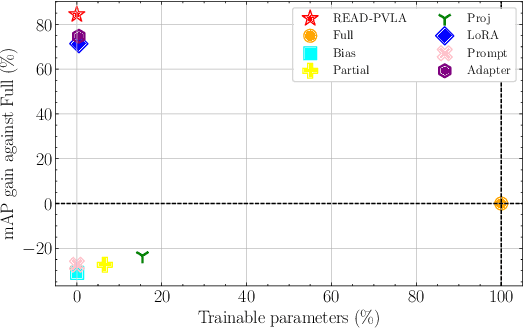
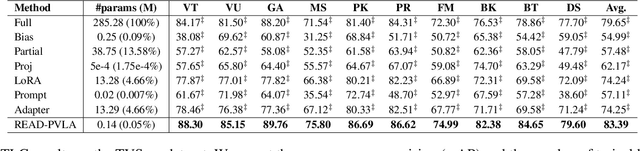
Fully fine-tuning pretrained large-scale transformer models has become a popular paradigm for video-language modeling tasks, such as temporal language grounding and video-language summarization. With a growing number of tasks and limited training data, such full fine-tuning approach leads to costly model storage and unstable training. To overcome these shortcomings, we introduce lightweight adapters to the pre-trained model and only update them at fine-tuning time. However, existing adapters fail to capture intrinsic temporal relations among video frames or textual words. Moreover, they neglect the preservation of critical task-related information that flows from the raw video-language input into the adapter's low-dimensional space. To address these issues, we first propose a novel REcurrent ADapter (READ) that employs recurrent computation to enable temporal modeling capability. Second, we propose Partial Video-Language Alignment (PVLA) objective via the use of partial optimal transport to maintain task-related information flowing into our READ modules. We validate our READ-PVLA framework through extensive experiments where READ-PVLA significantly outperforms all existing fine-tuning strategies on multiple low-resource temporal language grounding and video-language summarization benchmarks.
DiffuVST: Narrating Fictional Scenes with Global-History-Guided Denoising Models
Dec 12, 2023Recent advances in image and video creation, especially AI-based image synthesis, have led to the production of numerous visual scenes that exhibit a high level of abstractness and diversity. Consequently, Visual Storytelling (VST), a task that involves generating meaningful and coherent narratives from a collection of images, has become even more challenging and is increasingly desired beyond real-world imagery. While existing VST techniques, which typically use autoregressive decoders, have made significant progress, they suffer from low inference speed and are not well-suited for synthetic scenes. To this end, we propose a novel diffusion-based system DiffuVST, which models the generation of a series of visual descriptions as a single conditional denoising process. The stochastic and non-autoregressive nature of DiffuVST at inference time allows it to generate highly diverse narratives more efficiently. In addition, DiffuVST features a unique design with bi-directional text history guidance and multimodal adapter modules, which effectively improve inter-sentence coherence and image-to-text fidelity. Extensive experiments on the story generation task covering four fictional visual-story datasets demonstrate the superiority of DiffuVST over traditional autoregressive models in terms of both text quality and inference speed.
NVFi: Neural Velocity Fields for 3D Physics Learning from Dynamic Videos
Dec 11, 2023In this paper, we aim to model 3D scene dynamics from multi-view videos. Unlike the majority of existing works which usually focus on the common task of novel view synthesis within the training time period, we propose to simultaneously learn the geometry, appearance, and physical velocity of 3D scenes only from video frames, such that multiple desirable applications can be supported, including future frame extrapolation, unsupervised 3D semantic scene decomposition, and dynamic motion transfer. Our method consists of three major components, 1) the keyframe dynamic radiance field, 2) the interframe velocity field, and 3) a joint keyframe and interframe optimization module which is the core of our framework to effectively train both networks. To validate our method, we further introduce two dynamic 3D datasets: 1) Dynamic Object dataset, and 2) Dynamic Indoor Scene dataset. We conduct extensive experiments on multiple datasets, demonstrating the superior performance of our method over all baselines, particularly in the critical tasks of future frame extrapolation and unsupervised 3D semantic scene decomposition.
Compensation Sampling for Improved Convergence in Diffusion Models
Dec 11, 2023Diffusion models achieve remarkable quality in image generation, but at a cost. Iterative denoising requires many time steps to produce high fidelity images. We argue that the denoising process is crucially limited by an accumulation of the reconstruction error due to an initial inaccurate reconstruction of the target data. This leads to lower quality outputs, and slower convergence. To address this issue, we propose compensation sampling to guide the generation towards the target domain. We introduce a compensation term, implemented as a U-Net, which adds negligible computation overhead during training and, optionally, inference. Our approach is flexible and we demonstrate its application in unconditional generation, face inpainting, and face de-occlusion using benchmark datasets CIFAR-10, CelebA, CelebA-HQ, FFHQ-256, and FSG. Our approach consistently yields state-of-the-art results in terms of image quality, while accelerating the denoising process to converge during training by up to an order of magnitude.
From Text to Motion: Grounding GPT-4 in a Humanoid Robot "Alter3"
Dec 11, 2023We report the development of Alter3, a humanoid robot capable of generating spontaneous motion using a Large Language Model (LLM), specifically GPT-4. This achievement was realized by integrating GPT-4 into our proprietary android, Alter3, thereby effectively grounding the LLM with Alter's bodily movement. Typically, low-level robot control is hardware-dependent and falls outside the scope of LLM corpora, presenting challenges for direct LLM-based robot control. However, in the case of humanoid robots like Alter3, direct control is feasible by mapping the linguistic expressions of human actions onto the robot's body through program code. Remarkably, this approach enables Alter3 to adopt various poses, such as a 'selfie' stance or 'pretending to be a ghost,' and generate sequences of actions over time without explicit programming for each body part. This demonstrates the robot's zero-shot learning capabilities. Additionally, verbal feedback can adjust poses, obviating the need for fine-tuning. A video of Alter3's generated motions is available at https://tnoinkwms.github.io/ALTER-LLM/
User Friendly and Adaptable Discriminative AI: Using the Lessons from the Success of LLMs and Image Generation Models
Dec 11, 2023While there is significant interest in using generative AI tools as general-purpose models for specific ML applications, discriminative models are much more widely deployed currently. One of the key shortcomings of these discriminative AI tools that have been already deployed is that they are not adaptable and user-friendly compared to generative AI tools (e.g., GPT4, Stable Diffusion, Bard, etc.), where a non-expert user can iteratively refine model inputs and give real-time feedback that can be accounted for immediately, allowing users to build trust from the start. Inspired by this emerging collaborative workflow, we develop a new system architecture that enables users to work with discriminative models (such as for object detection, sentiment classification, etc.) in a fashion similar to generative AI tools, where they can easily provide immediate feedback as well as adapt the deployed models as desired. Our approach has implications on improving trust, user-friendliness, and adaptability of these versatile but traditional prediction models.
Beyond Classification: Definition and Density-based Estimation of Calibration in Object Detection
Dec 11, 2023Despite their impressive predictive performance in various computer vision tasks, deep neural networks (DNNs) tend to make overly confident predictions, which hinders their widespread use in safety-critical applications. While there have been recent attempts to calibrate DNNs, most of these efforts have primarily been focused on classification tasks, thus neglecting DNN-based object detectors. Although several recent works addressed calibration for object detection and proposed differentiable penalties, none of them are consistent estimators of established concepts in calibration. In this work, we tackle the challenge of defining and estimating calibration error specifically for this task. In particular, we adapt the definition of classification calibration error to handle the nuances associated with object detection, and predictions in structured output spaces more generally. Furthermore, we propose a consistent and differentiable estimator of the detection calibration error, utilizing kernel density estimation. Our experiments demonstrate the effectiveness of our estimator against competing train-time and post-hoc calibration methods, while maintaining similar detection performance.
Adaptive Test-Time Personalization for Federated Learning
Oct 28, 2023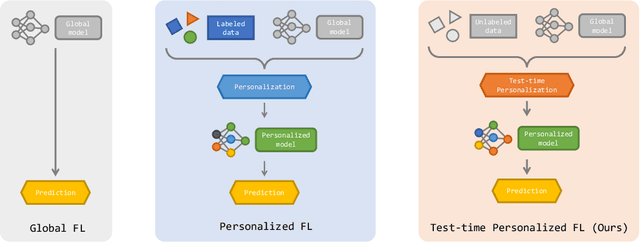
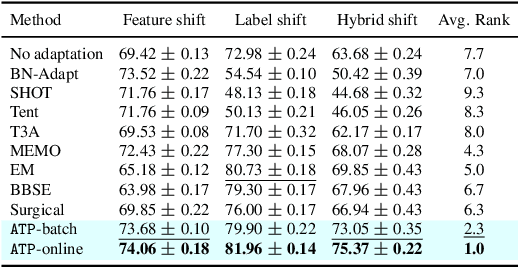
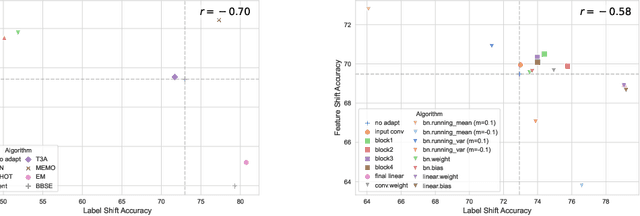
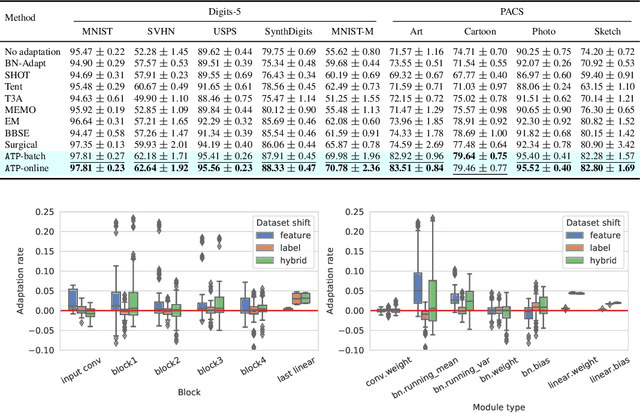
Personalized federated learning algorithms have shown promising results in adapting models to various distribution shifts. However, most of these methods require labeled data on testing clients for personalization, which is usually unavailable in real-world scenarios. In this paper, we introduce a novel setting called test-time personalized federated learning (TTPFL), where clients locally adapt a global model in an unsupervised way without relying on any labeled data during test-time. While traditional test-time adaptation (TTA) can be used in this scenario, most of them inherently assume training data come from a single domain, while they come from multiple clients (source domains) with different distributions. Overlooking these domain interrelationships can result in suboptimal generalization. Moreover, most TTA algorithms are designed for a specific kind of distribution shift and lack the flexibility to handle multiple kinds of distribution shifts in FL. In this paper, we find that this lack of flexibility partially results from their pre-defining which modules to adapt in the model. To tackle this challenge, we propose a novel algorithm called ATP to adaptively learns the adaptation rates for each module in the model from distribution shifts among source domains. Theoretical analysis proves the strong generalization of ATP. Extensive experiments demonstrate its superiority in handling various distribution shifts including label shift, image corruptions, and domain shift, outperforming existing TTA methods across multiple datasets and model architectures. Our code is available at https://github.com/baowenxuan/ATP .
Efficient 2D Graph SLAM for Sparse Sensing
Dec 04, 2023Simultaneous localization and mapping (SLAM) plays a vital role in mapping unknown spaces and aiding autonomous navigation. Virtually all state-of-the-art solutions today for 2D SLAM are designed for dense and accurate sensors such as laser range-finders (LiDARs). However, these sensors are not suitable for resource-limited nano robots, which become increasingly capable and ubiquitous nowadays, and these robots tend to mount economical and low-power sensors that can only provide sparse and noisy measurements. This introduces a challenging problem called SLAM with sparse sensing. This work addresses the problem by adopting the form of the state-of-the-art graph-based SLAM pipeline with a novel frontend and an improvement for loop closing in the backend, both of which are designed to work with sparse and uncertain range data. Experiments show that the maps constructed by our algorithm have superior quality compared to prior works on sparse sensing. Furthermore, our method is capable of running in real-time on a modern PC with an average processing time of 1/100th the input interval time.
Application of machine learning technique for a fast forecast of aggregation kinetics in space-inhomogeneous systems
Dec 07, 2023

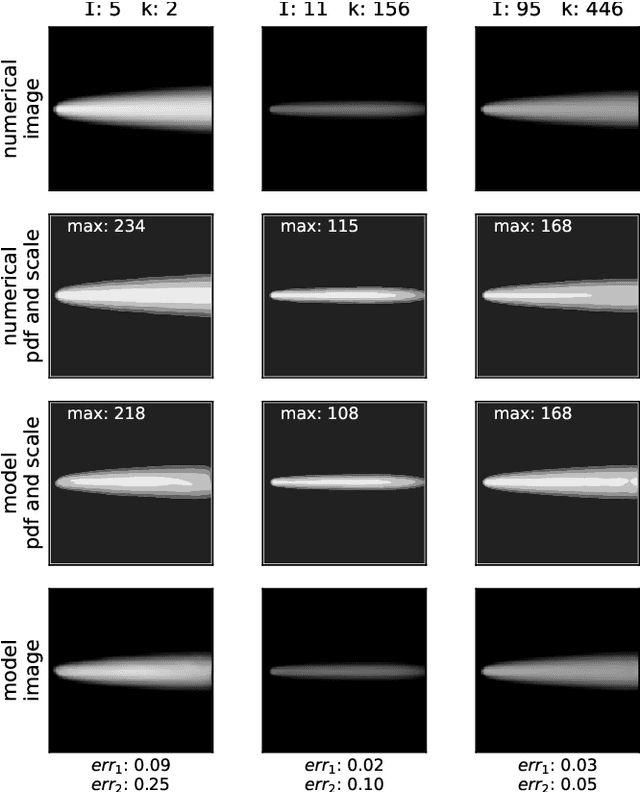
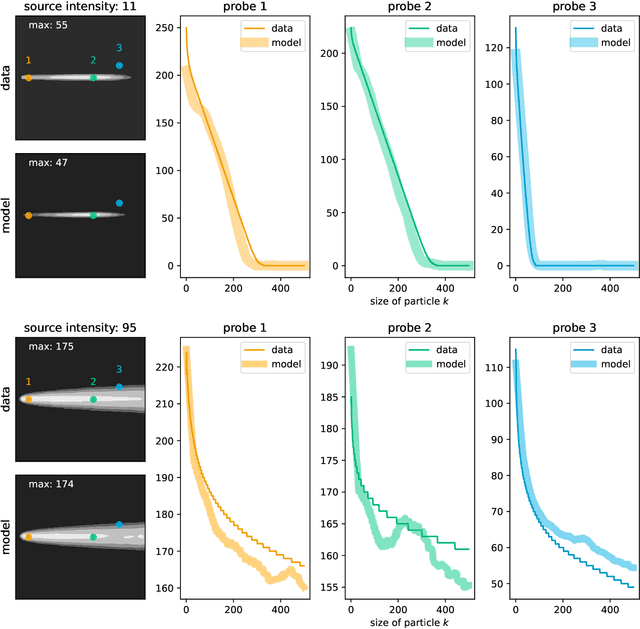
Modeling of aggregation processes in space-inhomogeneous systems is extremely numerically challenging since complicated aggregation equations -- Smoluchowski equations are to be solved at each space point along with the computation of particle propagation. Low rank approximation for the aggregation kernels can significantly speed up the solution of Smoluchowski equations, while particle propagation could be done in parallel. Yet the simulations with many aggregate sizes remain quite resource-demanding. Here, we explore the way to reduce the amount of direct computations with the use of modern machine learning (ML) techniques. Namely, we propose to replace the actual numerical solution of the Smoluchowki equations with the respective density transformations learned with the application of the conditional normalising flow. We demonstrate that the ML predictions for the space distribution of aggregates and their size distribution requires drastically less computation time and agrees fairly well with the results of direct numerical simulations. Such an opportunity of a quick forecast of space-dependent particle size distribution could be important in practice, especially for the online prediction and visualisation of pollution processes, providing a tool with a reasonable tradeoff between the prediction accuracy and the computational time.