 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Designing Heterogeneous Robot Fleets for Task Allocation and Sequencing
Dec 12, 2023
We study the problem of selecting a fleet of robots to service spatially distributed tasks with diverse requirements within time-windows. The problem of allocating tasks to a fleet of potentially heterogeneous robots and finding an optimal sequence for each robot is known as multi-robot task assignment (MRTA). Most state-of-the-art methods focus on the problem when the fleet of robots is fixed. In contrast, we consider that we are given a set of available robot types and requested tasks, and need to assemble a fleet that optimally services the tasks while the cost of the fleet remains under a budget limit. We characterize the complexity of the problem and provide a Mixed-Integer Linear Program (MILP) formulation. Due to poor scalability of the MILP, we propose a heuristic solution based on a Large Neighbourhood Search (LNS). In simulations, we demonstrate that the proposed method requires substantially lower budgets than a greedy algorithm to service all tasks.
DDMT: Denoising Diffusion Mask Transformer Models for Multivariate Time Series Anomaly Detection
Oct 30, 2023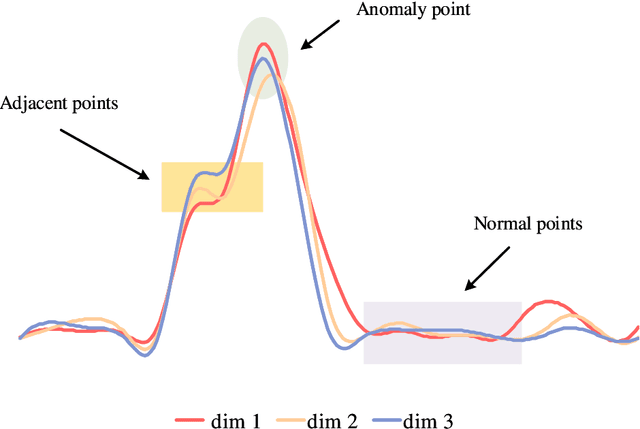

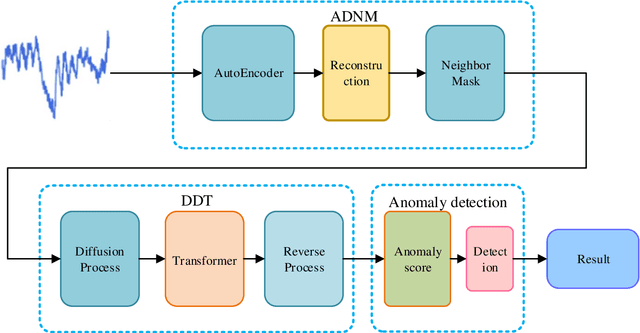
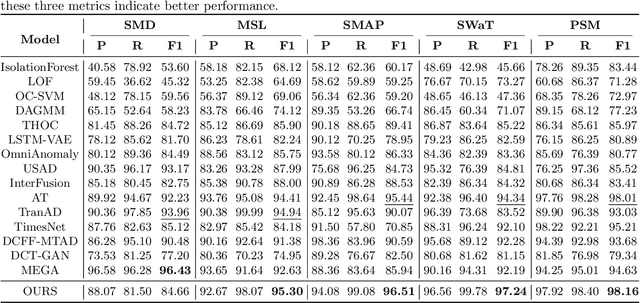
Anomaly detection in multivariate time series has emerged as a crucial challenge in time series research, with significant research implications in various fields such as fraud detection, fault diagnosis, and system state estimation. Reconstruction-based models have shown promising potential in recent years for detecting anomalies in time series data. However, due to the rapid increase in data scale and dimensionality, the issues of noise and Weak Identity Mapping (WIM) during time series reconstruction have become increasingly pronounced. To address this, we introduce a novel Adaptive Dynamic Neighbor Mask (ADNM) mechanism and integrate it with the Transformer and Denoising Diffusion Model, creating a new framework for multivariate time series anomaly detection, named Denoising Diffusion Mask Transformer (DDMT). The ADNM module is introduced to mitigate information leakage between input and output features during data reconstruction, thereby alleviating the problem of WIM during reconstruction. The Denoising Diffusion Transformer (DDT) employs the Transformer as an internal neural network structure for Denoising Diffusion Model. It learns the stepwise generation process of time series data to model the probability distribution of the data, capturing normal data patterns and progressively restoring time series data by removing noise, resulting in a clear recovery of anomalies. To the best of our knowledge, this is the first model that combines Denoising Diffusion Model and the Transformer for multivariate time series anomaly detection. Experimental evaluations were conducted on five publicly available multivariate time series anomaly detection datasets. The results demonstrate that the model effectively identifies anomalies in time series data, achieving state-of-the-art performance in anomaly detection.
Graph Deep Learning for Time Series Forecasting
Oct 24, 2023Graph-based deep learning methods have become popular tools to process collections of correlated time series. Differently from traditional multivariate forecasting methods, neural graph-based predictors take advantage of pairwise relationships by conditioning forecasts on a (possibly dynamic) graph spanning the time series collection. The conditioning can take the form of an architectural inductive bias on the neural forecasting architecture, resulting in a family of deep learning models called spatiotemporal graph neural networks. Such relational inductive biases enable the training of global forecasting models on large time-series collections, while at the same time localizing predictions w.r.t. each element in the set (i.e., graph nodes) by accounting for local correlations among them (i.e., graph edges). Indeed, recent theoretical and practical advances in graph neural networks and deep learning for time series forecasting make the adoption of such processing frameworks appealing and timely. However, most of the studies in the literature focus on proposing variations of existing neural architectures by taking advantage of modern deep learning practices, while foundational and methodological aspects have not been subject to systematic investigation. To fill the gap, this paper aims to introduce a comprehensive methodological framework that formalizes the forecasting problem and provides design principles for graph-based predictive models and methods to assess their performance. At the same time, together with an overview of the field, we provide design guidelines, recommendations, and best practices, as well as an in-depth discussion of open challenges and future research directions.
Human motion trajectory prediction using the Social Force Model for real-time and low computational cost applications
Nov 17, 2023Human motion trajectory prediction is a very important functionality for human-robot collaboration, specifically in accompanying, guiding, or approaching tasks, but also in social robotics, self-driving vehicles, or security systems. In this paper, a novel trajectory prediction model, Social Force Generative Adversarial Network (SoFGAN), is proposed. SoFGAN uses a Generative Adversarial Network (GAN) and Social Force Model (SFM) to generate different plausible people trajectories reducing collisions in a scene. Furthermore, a Conditional Variational Autoencoder (CVAE) module is added to emphasize the destination learning. We show that our method is more accurate in making predictions in UCY or BIWI datasets than most of the current state-of-the-art models and also reduces collisions in comparison to other approaches. Through real-life experiments, we demonstrate that the model can be used in real-time without GPU's to perform good quality predictions with a low computational cost.
Variational Auto-Encoder Based Deep Learning Technique For Filling Gaps in Reacting PIV Data
Dec 11, 2023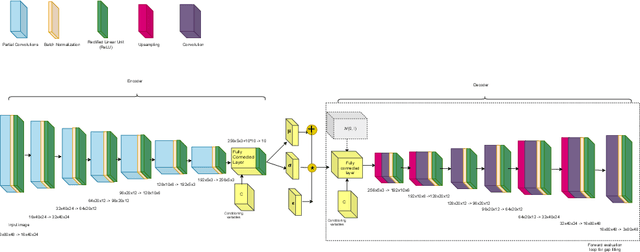
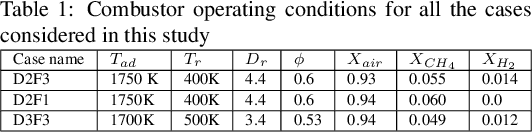
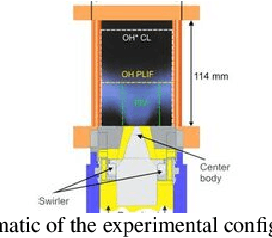
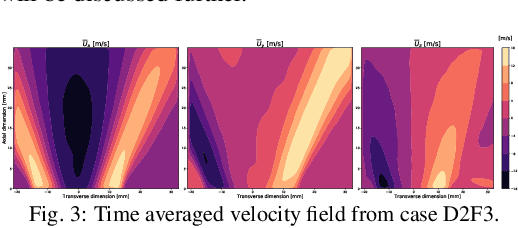
In this study, a deep learning based conditional density estimation technique known as conditional variational auto-encoder (CVAE) is used to fill gaps typically observed in particle image velocimetry (PIV) measurements in combustion systems. The proposed CVAE technique is trained using time resolved gappy PIV fields, typically observed in industrially relevant combustors. Stereo-PIV (SPIV) data from a swirl combustor with very a high vector yield is used to showcase the accuracy of the proposed CVAE technique. Various error metrics evaluated on the reconstructed velocity field in the gaps are presented from data sets corresponding to three sets of combustor operating conditions. In addition to accurate data reproduction, the proposed CVAE technique offers data compression by reducing the latent space dimension, enabling the efficient processing of large-scale PIV data.
Self-supervised Machine Learning Based Approach to Orbit Modelling Applied to Space Traffic Management
Dec 11, 2023This paper presents a novel methodology for improving the performance of machine learning based space traffic management tasks through the use of a pre-trained orbit model. Taking inspiration from BERT-like self-supervised language models in the field of natural language processing, we introduce ORBERT, and demonstrate the ability of such a model to leverage large quantities of readily available orbit data to learn meaningful representations that can be used to aid in downstream tasks. As a proof of concept of this approach we consider the task of all vs. all conjunction screening, phrased here as a machine learning time series classification task. We show that leveraging unlabelled orbit data leads to improved performance, and that the proposed approach can be particularly beneficial for tasks where the availability of labelled data is limited.
* Presented at the 2021 International Association for the Advancement of Space Safety (IAASS) Conf
Time-Efficient Reinforcement Learning with Stochastic Stateful Policies
Nov 07, 2023Stateful policies play an important role in reinforcement learning, such as handling partially observable environments, enhancing robustness, or imposing an inductive bias directly into the policy structure. The conventional method for training stateful policies is Backpropagation Through Time (BPTT), which comes with significant drawbacks, such as slow training due to sequential gradient propagation and the occurrence of vanishing or exploding gradients. The gradient is often truncated to address these issues, resulting in a biased policy update. We present a novel approach for training stateful policies by decomposing the latter into a stochastic internal state kernel and a stateless policy, jointly optimized by following the stateful policy gradient. We introduce different versions of the stateful policy gradient theorem, enabling us to easily instantiate stateful variants of popular reinforcement learning and imitation learning algorithms. Furthermore, we provide a theoretical analysis of our new gradient estimator and compare it with BPTT. We evaluate our approach on complex continuous control tasks, e.g., humanoid locomotion, and demonstrate that our gradient estimator scales effectively with task complexity while offering a faster and simpler alternative to BPTT.
Automating reward function configuration for drug design
Dec 15, 2023Designing reward functions that guide generative molecular design (GMD) algorithms to desirable areas of chemical space is of critical importance in AI-driven drug discovery. Traditionally, this has been a manual and error-prone task; the selection of appropriate computational methods to approximate biological assays is challenging and the aggregation of computed values into a single score even more so, leading to potential reliance on trial-and-error approaches. We propose a novel approach for automated reward configuration that relies solely on experimental data, mitigating the challenges of manual reward adjustment on drug discovery projects. Our method achieves this by constructing a ranking over experimental data based on Pareto dominance over the multi-objective space, then training a neural network to approximate the reward function such that rankings determined by the predicted reward correlate with those determined by the Pareto dominance relation. We validate our method using two case studies. In the first study we simulate Design-Make-Test-Analyse (DMTA) cycles by alternating reward function updates and generative runs guided by that function. We show that the learned function adapts over time to yield compounds that score highly with respect to evaluation functions taken from the literature. In the second study we apply our algorithm to historical data from four real drug discovery projects. We show that our algorithm yields reward functions that outperform the predictive accuracy of human-defined functions, achieving an improvement of up to 0.4 in Spearman's correlation against a ground truth evaluation function that encodes the target drug profile for that project. Our method provides an efficient data-driven way to configure reward functions for GMD, and serves as a strong baseline for future research into transformative approaches for the automation of drug discovery.
Plasticine3D: Non-rigid 3D editting with text guidance
Dec 15, 2023With the help of Score Distillation Sampling(SDS) and the rapid development of various trainable 3D representations, Text-to-Image(T2I) diffusion models have been applied to 3D generation tasks and achieved considerable results. There are also some attempts toward the task of editing 3D objects leveraging this Text-to-3D pipeline. However, most methods currently focus on adding additional geometries, overwriting textures or both. But few of them can perform non-rigid transformation of 3D objects. For those who can perform non-rigid editing, on the other hand, suffer from low-resolution, lack of fidelity and poor flexibility. In order to address these issues, we present: Plasticine3D, a general, high-fidelity, photo-realistic and controllable non-rigid editing pipeline. Firstly, our work divides the editing process into a geometry editing stage and a texture editing stage to achieve more detailed and photo-realistic results ; Secondly, in order to perform non-rigid transformation with controllable results while maintain the fidelity towards original 3D models in the same time, we propose a multi-view-embedding(MVE) optimization strategy to ensure that the diffusion model learns the overall features of the original object and an embedding-fusion(EF) to control the degree of editing by adjusting the value of the fusing rate. We also design a geometry processing step before optimizing on the base geometry to cope with different needs of various editing tasks. Further more, to fully leverage the geometric prior from the original 3D object, we provide an optional replacement of score distillation sampling named score projection sampling(SPS) which enables us to directly perform optimization from the origin 3D mesh in most common median non-rigid editing scenarios. We demonstrate the effectiveness of our method on both the non-rigid 3D editing task and general 3D editing task.
Brain Diffuser with Hierarchical Transformer for MCI Causality Analysis
Dec 14, 2023Effective connectivity estimation plays a crucial role in understanding the interactions and information flow between different brain regions. However, the functional time series used for estimating effective connentivity is derived from certain software, which may lead to large computing errors because of different parameter settings and degrade the ability to model complex causal relationships between brain regions. In this paper, a brain diffuser with hierarchical transformer (BDHT) is proposed to estimate effective connectivity for mild cognitive impairment (MCI) analysis. To our best knowledge, the proposed brain diffuer is the first generative model to apply diffusion models in the application of generating and analyzing multimodal brain networks. Specifically, the BDHT leverages the structural connectivity to guide the reverse processes in an efficient way. It makes the denoising process more reliable and guarantees effective connectivity estimation accuracy. To improve denoising quality, the hierarchical denoising transformer is designed to learn multi-scale features in topological space. Furthermore, the GraphConFormer block can concentrate on both global and adjacent connectivity information. By stacking the multi-head attention and graph convolutional network, the proposed model enhances structure-function complementarity and improves the ability in noise estimation. Experimental evaluations of the denoising diffusion model demonstrate its effectiveness in estimating effective connectivity. The method achieves superior performance in terms of accuracy and robustness compared to existing approaches. It can captures both unidirectal and bidirectional interactions between brain regions, providing a comprehensive understanding of the brain's information processing mechanisms.