 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Near-Optimal Algorithms for Gaussians with Huber Contamination: Mean Estimation and Linear Regression
Dec 04, 2023
We study the fundamental problems of Gaussian mean estimation and linear regression with Gaussian covariates in the presence of Huber contamination. Our main contribution is the design of the first sample near-optimal and almost linear-time algorithms with optimal error guarantees for both of these problems. Specifically, for Gaussian robust mean estimation on $\mathbb{R}^d$ with contamination parameter $\epsilon \in (0, \epsilon_0)$ for a small absolute constant $\epsilon_0$, we give an algorithm with sample complexity $n = \tilde{O}(d/\epsilon^2)$ and almost linear runtime that approximates the target mean within $\ell_2$-error $O(\epsilon)$. This improves on prior work that achieved this error guarantee with polynomially suboptimal sample and time complexity. For robust linear regression, we give the first algorithm with sample complexity $n = \tilde{O}(d/\epsilon^2)$ and almost linear runtime that approximates the target regressor within $\ell_2$-error $O(\epsilon)$. This is the first polynomial sample and time algorithm achieving the optimal error guarantee, answering an open question in the literature. At the technical level, we develop a methodology that yields almost-linear time algorithms for multi-directional filtering that may be of broader interest.
Graph Deep Learning for Time Series Forecasting
Oct 24, 2023Graph-based deep learning methods have become popular tools to process collections of correlated time series. Differently from traditional multivariate forecasting methods, neural graph-based predictors take advantage of pairwise relationships by conditioning forecasts on a (possibly dynamic) graph spanning the time series collection. The conditioning can take the form of an architectural inductive bias on the neural forecasting architecture, resulting in a family of deep learning models called spatiotemporal graph neural networks. Such relational inductive biases enable the training of global forecasting models on large time-series collections, while at the same time localizing predictions w.r.t. each element in the set (i.e., graph nodes) by accounting for local correlations among them (i.e., graph edges). Indeed, recent theoretical and practical advances in graph neural networks and deep learning for time series forecasting make the adoption of such processing frameworks appealing and timely. However, most of the studies in the literature focus on proposing variations of existing neural architectures by taking advantage of modern deep learning practices, while foundational and methodological aspects have not been subject to systematic investigation. To fill the gap, this paper aims to introduce a comprehensive methodological framework that formalizes the forecasting problem and provides design principles for graph-based predictive models and methods to assess their performance. At the same time, together with an overview of the field, we provide design guidelines, recommendations, and best practices, as well as an in-depth discussion of open challenges and future research directions.
Understanding Concepts in Graph Signal Processing for Neurophysiological Signal Analysis
Dec 06, 2023Multivariate signals, which are measured simultaneously over time and acquired by sensor networks, are becoming increasingly common. The emerging field of graph signal processing (GSP) promises to analyse spectral characteristics of these multivariate signals, while at the same time taking the spatial structure between the time signals into account. A central idea in GSP is the graph Fourier transform, which projects a multivariate signal onto frequency-ordered graph Fourier modes, and can therefore be regarded as a spatial analog of the temporal Fourier transform. This chapter derives and discusses key concepts in GSP, with a specific focus on how the various concepts relate to one another. The experimental section focuses on the role of graph frequency in data classification, with applications to neuroimaging. To address the limited sample size of neurophysiological datasets, we introduce a minimalist simulation framework that can generate arbitrary amounts of data. Using this artificial data, we find that lower graph frequency signals are less suitable for classifying neurophysiological data as compared to higher graph frequency signals. Finally, we introduce a baseline testing framework for GSP. Employing this framework, our results suggest that GSP applications may attenuate spectral characteristics in the signals, highlighting current limitations of GSP for neuroimaging.
Gaussian-Flow: 4D Reconstruction with Dynamic 3D Gaussian Particle
Dec 06, 2023We introduce Gaussian-Flow, a novel point-based approach for fast dynamic scene reconstruction and real-time rendering from both multi-view and monocular videos. In contrast to the prevalent NeRF-based approaches hampered by slow training and rendering speeds, our approach harnesses recent advancements in point-based 3D Gaussian Splatting (3DGS). Specifically, a novel Dual-Domain Deformation Model (DDDM) is proposed to explicitly model attribute deformations of each Gaussian point, where the time-dependent residual of each attribute is captured by a polynomial fitting in the time domain, and a Fourier series fitting in the frequency domain. The proposed DDDM is capable of modeling complex scene deformations across long video footage, eliminating the need for training separate 3DGS for each frame or introducing an additional implicit neural field to model 3D dynamics. Moreover, the explicit deformation modeling for discretized Gaussian points ensures ultra-fast training and rendering of a 4D scene, which is comparable to the original 3DGS designed for static 3D reconstruction. Our proposed approach showcases a substantial efficiency improvement, achieving a $5\times$ faster training speed compared to the per-frame 3DGS modeling. In addition, quantitative results demonstrate that the proposed Gaussian-Flow significantly outperforms previous leading methods in novel view rendering quality. Project page: https://nju-3dv.github.io/projects/Gaussian-Flow
Bile Duct Segmentation Methods Under 3D Slicer Applied to ERCP: Advantages and Disadvantages
Dec 06, 2023This article presents an evaluation of biliary tract segmentation methods used for 3D reconstruction, which may be very usefull in various critical interventions, such as endoscopic retrograde cholangiopancreatography (ERCP), using the 3D Slicer software. This article provides an assessment of biliary tract segmentation techniques employed for 3D reconstruction, which can prove highly valuable in diverse critical procedures like endoscopic retrograde cholangiopancreatography (ERCP) through the utilization of 3D Slicer software. Three different methods, namely thresholding, flood filling, and region growing, were assessed in terms of their advantages and disadvantages. The study involved 10 patient cases and employed quantitative indices and qualitative evaluation to assess the segmentations obtained by the different segmentation methods against ground truth. The results indicate that the thresholding method is almost manual and time-consuming, while the flood filling method is semi-automatic and also time-consuming. Although both methods improve segmentation quality, they are not reproducible. Therefore, an automatic method based on region growing was developed to reduce segmentation time, albeit at the expense of quality. These findings highlight the pros and cons of different conventional segmentation methods and underscore the need to explore alternative approaches, such as deep learning, to optimize biliary tract segmentation in the context of ERCP.
Combinatorial Stochastic-Greedy Bandit
Dec 13, 2023We propose a novel combinatorial stochastic-greedy bandit (SGB) algorithm for combinatorial multi-armed bandit problems when no extra information other than the joint reward of the selected set of $n$ arms at each time step $t\in [T]$ is observed. SGB adopts an optimized stochastic-explore-then-commit approach and is specifically designed for scenarios with a large set of base arms. Unlike existing methods that explore the entire set of unselected base arms during each selection step, our SGB algorithm samples only an optimized proportion of unselected arms and selects actions from this subset. We prove that our algorithm achieves a $(1-1/e)$-regret bound of $\mathcal{O}(n^{\frac{1}{3}} k^{\frac{2}{3}} T^{\frac{2}{3}} \log(T)^{\frac{2}{3}})$ for monotone stochastic submodular rewards, which outperforms the state-of-the-art in terms of the cardinality constraint $k$. Furthermore, we empirically evaluate the performance of our algorithm in the context of online constrained social influence maximization. Our results demonstrate that our proposed approach consistently outperforms the other algorithms, increasing the performance gap as $k$ grows.
Explainable Trajectory Representation through Dictionary Learning
Dec 13, 2023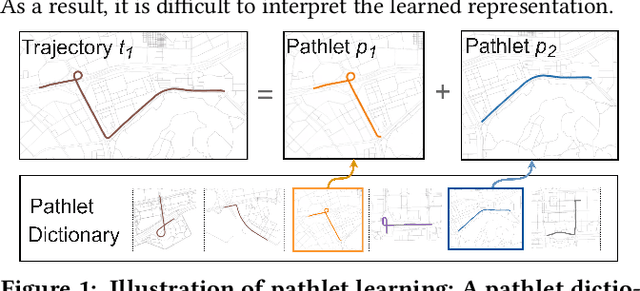

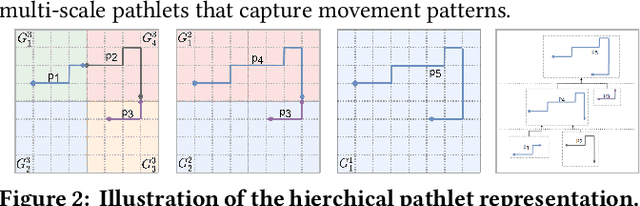
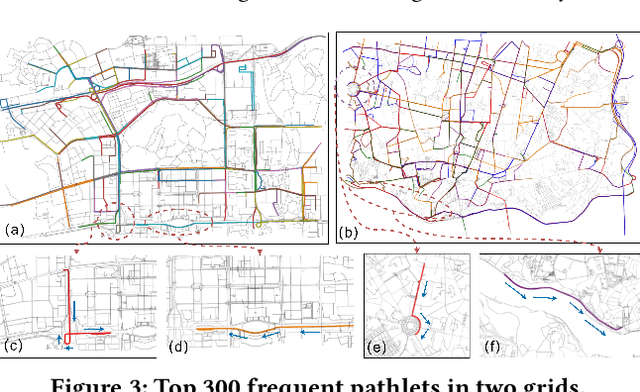
Trajectory representation learning on a network enhances our understanding of vehicular traffic patterns and benefits numerous downstream applications. Existing approaches using classic machine learning or deep learning embed trajectories as dense vectors, which lack interpretability and are inefficient to store and analyze in downstream tasks. In this paper, an explainable trajectory representation learning framework through dictionary learning is proposed. Given a collection of trajectories on a network, it extracts a compact dictionary of commonly used subpaths called "pathlets", which optimally reconstruct each trajectory by simple concatenations. The resulting representation is naturally sparse and encodes strong spatial semantics. Theoretical analysis of our proposed algorithm is conducted to provide a probabilistic bound on the estimation error of the optimal dictionary. A hierarchical dictionary learning scheme is also proposed to ensure the algorithm's scalability on large networks, leading to a multi-scale trajectory representation. Our framework is evaluated on two large-scale real-world taxi datasets. Compared to previous work, the dictionary learned by our method is more compact and has better reconstruction rate for new trajectories. We also demonstrate the promising performance of this method in downstream tasks including trip time prediction task and data compression.
Time-Efficient Reinforcement Learning with Stochastic Stateful Policies
Nov 07, 2023Stateful policies play an important role in reinforcement learning, such as handling partially observable environments, enhancing robustness, or imposing an inductive bias directly into the policy structure. The conventional method for training stateful policies is Backpropagation Through Time (BPTT), which comes with significant drawbacks, such as slow training due to sequential gradient propagation and the occurrence of vanishing or exploding gradients. The gradient is often truncated to address these issues, resulting in a biased policy update. We present a novel approach for training stateful policies by decomposing the latter into a stochastic internal state kernel and a stateless policy, jointly optimized by following the stateful policy gradient. We introduce different versions of the stateful policy gradient theorem, enabling us to easily instantiate stateful variants of popular reinforcement learning and imitation learning algorithms. Furthermore, we provide a theoretical analysis of our new gradient estimator and compare it with BPTT. We evaluate our approach on complex continuous control tasks, e.g., humanoid locomotion, and demonstrate that our gradient estimator scales effectively with task complexity while offering a faster and simpler alternative to BPTT.
A Data-driven Method for Safety-critical Control: Designing Control Barrier Functions from State Constraints
Dec 12, 2023This paper addresses the challenge of integrating explicit hard constraints into the control barrier function (CBF) framework for ensuring safety in autonomous systems, including robots. We propose a novel data-driven method to derive CBFs from these hard constraints in practical scenarios. Our approach assumes that the forward invariant safe set is either a subset or equal to the constrained set. The process consists of two main steps. First, we randomly sample states within the constraint boundaries and identify inputs meeting the time derivative criteria of the hard constraint; this iterative process converges using the Jaccard index. Next, we formulate CBFs that enclose the safe set using the sampled boundaries. This enables the creation of a control-invariant safe set, approaching the maximum attainable level of control invariance. This approach, therefore, addresses the complexities posed by complex autonomous systems with constrained control input spaces, culminating in a control-invariant safe set that closely approximates the maximal control invariant set.
NAC-TCN: Temporal Convolutional Networks with Causal Dilated Neighborhood Attention for Emotion Understanding
Dec 12, 2023In the task of emotion recognition from videos, a key improvement has been to focus on emotions over time rather than a single frame. There are many architectures to address this task such as GRUs, LSTMs, Self-Attention, Transformers, and Temporal Convolutional Networks (TCNs). However, these methods suffer from high memory usage, large amounts of operations, or poor gradients. We propose a method known as Neighborhood Attention with Convolutions TCN (NAC-TCN) which incorporates the benefits of attention and Temporal Convolutional Networks while ensuring that causal relationships are understood which results in a reduction in computation and memory cost. We accomplish this by introducing a causal version of Dilated Neighborhood Attention while incorporating it with convolutions. Our model achieves comparable, better, or state-of-the-art performance over TCNs, TCAN, LSTMs, and GRUs while requiring fewer parameters on standard emotion recognition datasets. We publish our code online for easy reproducibility and use in other projects.