 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BasisFormer: Attention-based Time Series Forecasting with Learnable and Interpretable Basis
Oct 31, 2023
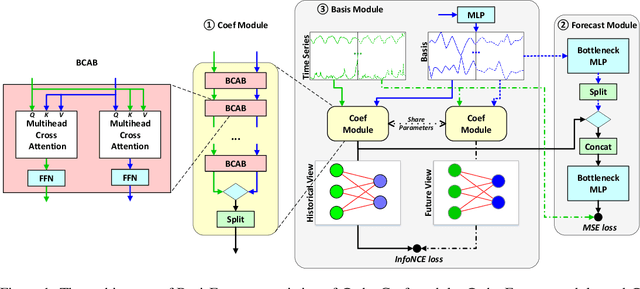
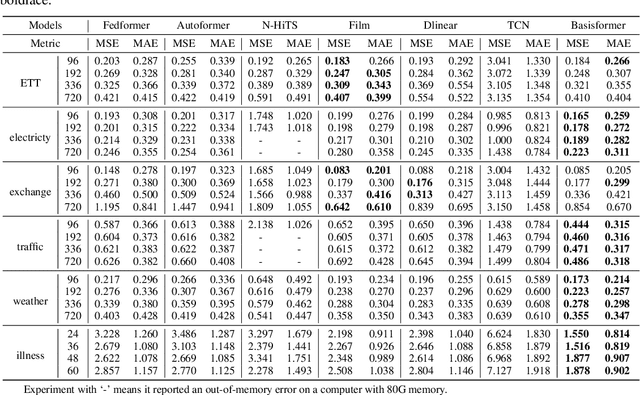
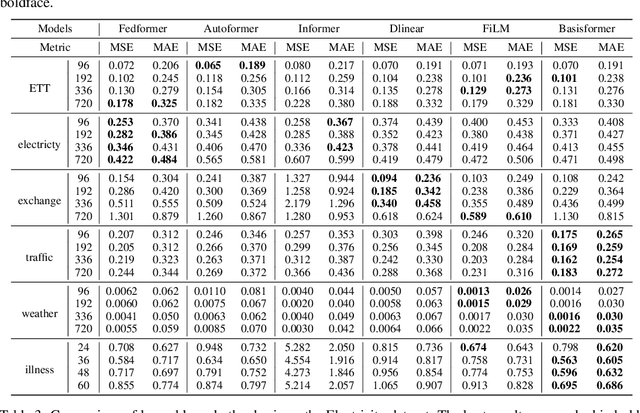
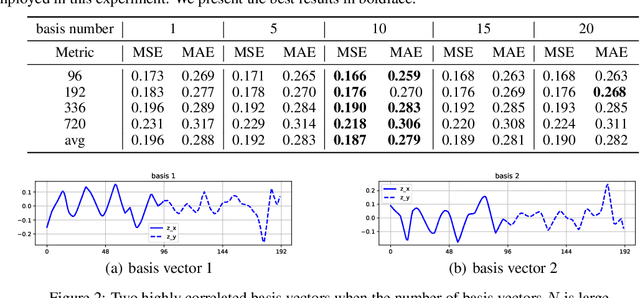
Bases have become an integral part of modern deep learning-based models for time series forecasting due to their ability to act as feature extractors or future references. To be effective, a basis must be tailored to the specific set of time series data and exhibit distinct correlation with each time series within the set. However, current state-of-the-art methods are limited in their ability to satisfy both of these requirements simultaneously. To address this challenge, we propose BasisFormer, an end-to-end time series forecasting architecture that leverages learnable and interpretable bases. This architecture comprises three components: First, we acquire bases through adaptive self-supervised learning, which treats the historical and future sections of the time series as two distinct views and employs contrastive learning. Next, we design a Coef module that calculates the similarity coefficients between the time series and bases in the historical view via bidirectional cross-attention. Finally, we present a Forecast module that selects and consolidates the bases in the future view based on the similarity coefficients, resulting in accurate future predictions. Through extensive experiments on six datasets, we demonstrate that BasisFormer outperforms previous state-of-the-art methods by 11.04\% and 15.78\% respectively for univariate and multivariate forecasting tasks. Code is available at: \url{https://github.com/nzl5116190/Basisformer}
Empowering remittance management in the digitised landscape: A real-time Data-Driven Decision Support with predictive abilities for financial transactions
Nov 20, 2023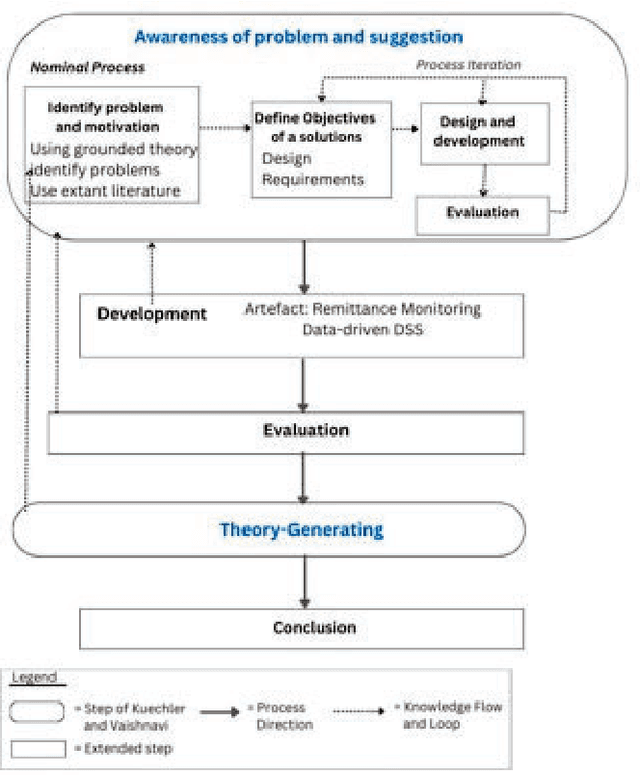
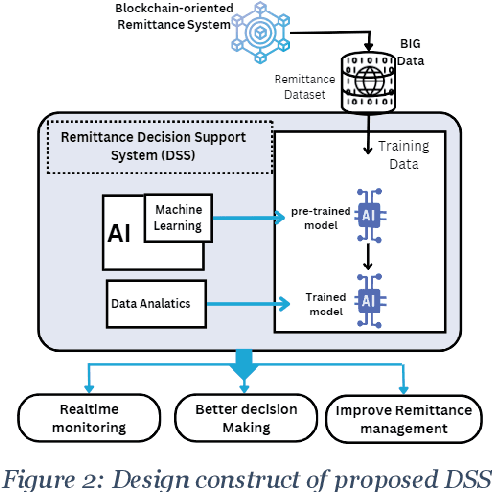

The advent of Blockchain technology (BT) revolutionised the way remittance transactions are recorded. Banks and remittance organisations have shown a growing interest in exploring blockchain's potential advantages over traditional practices. This paper presents a data-driven predictive decision support approach as an innovative artefact designed for the blockchain-oriented remittance industry. Employing a theory-generating Design Science Research (DSR) approach, we have uncovered the emergence of predictive capabilities driven by transactional big data. The artefact integrates predictive analytics and Machine Learning (ML) to enable real-time remittance monitoring, empowering management decision-makers to address challenges in the uncertain digitised landscape of blockchain-oriented remittance companies. Bridging the gap between theory and practice, this research not only enhances the security of the remittance ecosystem but also lays the foundation for future predictive decision support solutions, extending the potential of predictive analytics to other domains. Additionally, the generated theory from the artifact's implementation enriches the DSR approach and fosters grounded and stakeholder theory development in the information systems domain.
* Ppaper has been accepted for presenting in the Australasian Conference on Information Systems 2023, Dec 6 to 8, Wellington, NZ
Language Modeling on a SpiNNaker 2 Neuromorphic Chip
Dec 14, 2023As large language models continue to scale in size rapidly, so too does the computational power required to run them. Event-based networks on neuromorphic devices offer a potential way to reduce energy consumption for inference significantly. However, to date, most event-based networks that can run on neuromorphic hardware, including spiking neural networks (SNNs), have not achieved task performance even on par with LSTM models for language modeling. As a result, language modeling on neuromorphic devices has seemed a distant prospect. In this work, we demonstrate the first-ever implementation of a language model on a neuromorphic device - specifically the SpiNNaker 2 chip - based on a recently published event-based architecture called the EGRU. SpiNNaker 2 is a many-core neuromorphic chip designed for large-scale asynchronous processing, while the EGRU is architected to leverage such hardware efficiently while maintaining competitive task performance. This implementation marks the first time a neuromorphic language model matches LSTMs, setting the stage for taking task performance to the level of large language models. We also demonstrate results on a gesture recognition task based on inputs from a DVS camera. Overall, our results showcase the feasibility of this neuro-inspired neural network in hardware, highlighting significant gains versus conventional hardware in energy efficiency for the common use case of single batch inference.
Dataset Distillation via Adversarial Prediction Matching
Dec 14, 2023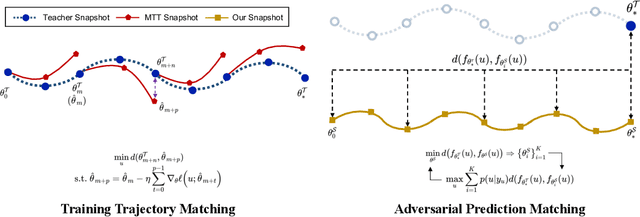
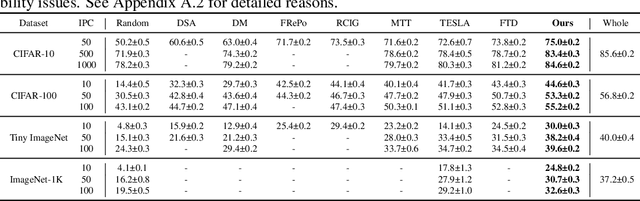
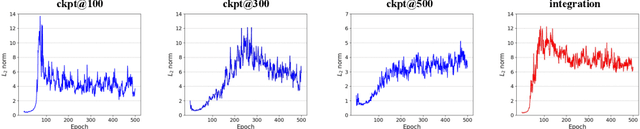
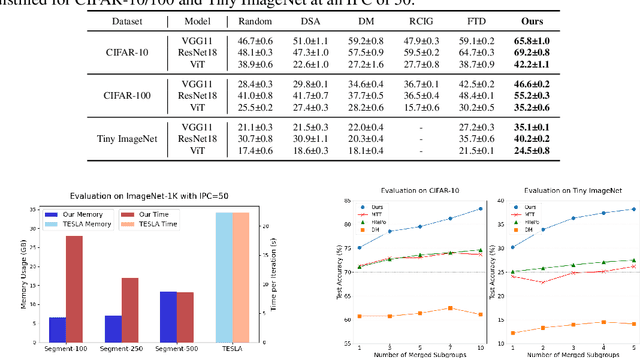
Dataset distillation is the technique of synthesizing smaller condensed datasets from large original datasets while retaining necessary information to persist the effect. In this paper, we approach the dataset distillation problem from a novel perspective: we regard minimizing the prediction discrepancy on the real data distribution between models, which are respectively trained on the large original dataset and on the small distilled dataset, as a conduit for condensing information from the raw data into the distilled version. An adversarial framework is proposed to solve the problem efficiently. In contrast to existing distillation methods involving nested optimization or long-range gradient unrolling, our approach hinges on single-level optimization. This ensures the memory efficiency of our method and provides a flexible tradeoff between time and memory budgets, allowing us to distil ImageNet-1K using a minimum of only 6.5GB of GPU memory. Under the optimal tradeoff strategy, it requires only 2.5$\times$ less memory and 5$\times$ less runtime compared to the state-of-the-art. Empirically, our method can produce synthetic datasets just 10% the size of the original, yet achieve, on average, 94% of the test accuracy of models trained on the full original datasets including ImageNet-1K, significantly surpassing state-of-the-art. Additionally, extensive tests reveal that our distilled datasets excel in cross-architecture generalization capabilities.
Hourglass-AVSR: Down-Up Sampling-based Computational Efficiency Model for Audio-Visual Speech Recognition
Dec 14, 2023Recently audio-visual speech recognition (AVSR), which better leverages video modality as additional information to extend automatic speech recognition (ASR), has shown promising results in complex acoustic environments. However, there is still substantial space to improve as complex computation of visual modules and ineffective fusion of audio-visual modalities. To eliminate these drawbacks, we propose a down-up sampling-based AVSR model (Hourglass-AVSR) to enjoy high efficiency and performance, whose time length is scaled during the intermediate processing, resembling an hourglass. Firstly, we propose a context and residual aware video upsampling approach to improve the recognition performance, which utilizes contextual information from visual representations and captures residual information between adjacent video frames. Secondly, we introduce a visual-audio alignment approach during the upsampling by explicitly incorporating boundary constraint loss. Besides, we propose a cross-layer attention fusion to capture the modality dependencies within each visual encoder layer. Experiments conducted on the MISP-AVSR dataset reveal that our proposed Hourglass-AVSR model outperforms ASR model by 12.9% and 20.8% relative concatenated minimum permutation character error rate (cpCER) reduction on far-field and middle-field test sets, respectively. Moreover, compared to other state-of-the-art AVSR models, our model exhibits the highest improvement in cpCER for the visual module. Furthermore, on the benefit of our down-up sampling approach, Hourglass-AVSR model reduces 54.2% overall computation costs with minor performance degradation.
MotherNet: A Foundational Hypernetwork for Tabular Classification
Dec 14, 2023The advent of Foundation Models is transforming machine learning across many modalities (e.g., language, images, videos) with prompt engineering replacing training in many settings. Recent work on tabular data (e.g., TabPFN) hints at a similar opportunity to build Foundation Models for classification for numerical data. In this paper, we go one step further and propose a hypernetwork architecture that we call MotherNet, trained on millions of classification tasks, that, once prompted with a never-seen-before training set generates the weights of a trained ``child'' neural-network. Like other Foundation Models, MotherNet replaces training on specific datasets with in-context learning through a single forward pass. In contrast to existing hypernetworks that were either task-specific or trained for relatively constraint multi-task settings, MotherNet is trained to generate networks to perform multiclass classification on arbitrary tabular datasets without any dataset specific gradient descent. The child network generated by MotherNet using in-context learning outperforms neural networks trained using gradient descent on small datasets, and is competitive with predictions by TabPFN and standard ML methods like Gradient Boosting. Unlike a direct application of transformer models like TabPFN, MotherNet generated networks are highly efficient at inference time. This methodology opens up a new approach to building predictive models on tabular data that is both efficient and robust, without any dataset-specific training.
Satellite Imagery and AI: A New Era in Ocean Conservation, from Research to Deployment and Impact
Dec 06, 2023Illegal, unreported, and unregulated (IUU) fishing poses a global threat to ocean habitats. Publicly available satellite data offered by NASA and the European Space Agency (ESA) provide an opportunity to actively monitor this activity. Effectively leveraging satellite data for maritime conservation requires highly reliable machine learning models operating globally with minimal latency. This paper introduces three specialized computer vision models designed for synthetic aperture radar (Sentinel-1), optical imagery (Sentinel-2), and nighttime lights (Suomi-NPP/NOAA-20). It also presents best practices for developing and delivering real-time computer vision services for conservation. These models have been deployed in Skylight, a real time maritime monitoring platform, which is provided at no cost to users worldwide.
MobileSAMv2: Faster Segment Anything to Everything
Dec 15, 2023Segment anything model (SAM) addresses two practical yet challenging segmentation tasks: \textbf{segment anything (SegAny)}, which utilizes a certain point to predict the mask for a single object of interest, and \textbf{segment everything (SegEvery)}, which predicts the masks for all objects on the image. What makes SegAny slow for SAM is its heavyweight image encoder, which has been addressed by MobileSAM via decoupled knowledge distillation. The efficiency bottleneck of SegEvery with SAM, however, lies in its mask decoder because it needs to first generate numerous masks with redundant grid-search prompts and then perform filtering to obtain the final valid masks. We propose to improve its efficiency by directly generating the final masks with only valid prompts, which can be obtained through object discovery. Our proposed approach not only helps reduce the total time on the mask decoder by at least 16 times but also achieves superior performance. Specifically, our approach yields an average performance boost of 3.6\% (42.5\% \textit{v.s.} 38.9\%) for zero-shot object proposal on the LVIS dataset with the mask AR@$K$ metric. Qualitative results show that our approach generates fine-grained masks while avoiding over-segmenting things. This project targeting faster SegEvery than the original SAM is termed MobileSAMv2 to differentiate from MobileSAM which targets faster SegAny. Moreover, we demonstrate that our new prompt sampling is also compatible with the distilled image encoders in MobileSAM, contributing to a unified framework for efficient SegAny and SegEvery. The code is available at the same link as MobileSAM Project \href{https://github.com/ChaoningZhang/MobileSAM}{\textcolor{red}{https://github.com/ChaoningZhang/MobileSAM}}. \end{abstract}
Maximising Quantum-Computing Expressive Power through Randomised Circuits
Dec 04, 2023In the noisy intermediate-scale quantum era, variational quantum algorithms (VQAs) have emerged as a promising avenue to obtain quantum advantage. However, the success of VQAs depends on the expressive power of parameterised quantum circuits, which is constrained by the limited gate number and the presence of barren plateaus. In this work, we propose and numerically demonstrate a novel approach for VQAs, utilizing randomised quantum circuits to generate the variational wavefunction. We parameterize the distribution function of these random circuits using artificial neural networks and optimize it to find the solution. This random-circuit approach presents a trade-off between the expressive power of the variational wavefunction and time cost, in terms of the sampling cost of quantum circuits. Given a fixed gate number, we can systematically increase the expressive power by extending the quantum-computing time. With a sufficiently large permissible time cost, the variational wavefunction can approximate any quantum state with arbitrary accuracy. Furthermore, we establish explicit relationships between expressive power, time cost, and gate number for variational quantum eigensolvers. These results highlight the promising potential of the random-circuit approach in achieving a high expressive power in quantum computing.
Near-Optimal Algorithms for Gaussians with Huber Contamination: Mean Estimation and Linear Regression
Dec 04, 2023We study the fundamental problems of Gaussian mean estimation and linear regression with Gaussian covariates in the presence of Huber contamination. Our main contribution is the design of the first sample near-optimal and almost linear-time algorithms with optimal error guarantees for both of these problems. Specifically, for Gaussian robust mean estimation on $\mathbb{R}^d$ with contamination parameter $\epsilon \in (0, \epsilon_0)$ for a small absolute constant $\epsilon_0$, we give an algorithm with sample complexity $n = \tilde{O}(d/\epsilon^2)$ and almost linear runtime that approximates the target mean within $\ell_2$-error $O(\epsilon)$. This improves on prior work that achieved this error guarantee with polynomially suboptimal sample and time complexity. For robust linear regression, we give the first algorithm with sample complexity $n = \tilde{O}(d/\epsilon^2)$ and almost linear runtime that approximates the target regressor within $\ell_2$-error $O(\epsilon)$. This is the first polynomial sample and time algorithm achieving the optimal error guarantee, answering an open question in the literature. At the technical level, we develop a methodology that yields almost-linear time algorithms for multi-directional filtering that may be of broader interest.