 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VitalLens: Take A Vital Selfie
Dec 11, 2023
This report introduces VitalLens, an app that estimates vital signs such as heart rate and respiration rate from selfie video in real time. VitalLens uses a computer vision model trained on a diverse dataset of video and physiological sensor data. We benchmark performance on several diverse datasets, including VV-Medium, which consists of 289 unique participants. VitalLens outperforms several existing methods including POS and MTTS-CAN on all datasets while maintaining a fast inference speed. On VV-Medium, VitalLens achieves absolute errors of 0.71 bpm for heart rate estimation, and 0.76 rpm for respiratory rate estimation.
Extrapolating tipping points and simulating non-stationary dynamics of complex systems using efficient machine learning
Dec 11, 2023Model-free and data-driven prediction of tipping point transitions in nonlinear dynamical systems is a challenging and outstanding task in complex systems science. We propose a novel, fully data-driven machine learning algorithm based on next-generation reservoir computing to extrapolate the bifurcation behavior of nonlinear dynamical systems using stationary training data samples. We show that this method can extrapolate tipping point transitions. Furthermore, it is demonstrated that the trained next-generation reservoir computing architecture can be used to predict non-stationary dynamics with time-varying bifurcation parameters. In doing so, post-tipping point dynamics of unseen parameter regions can be simulated.
Daily Assistive View Control Learning of Low-Cost Low-Rigidity Robot via Large-Scale Vision-Language Model
Dec 12, 2023In this study, we develop a simple daily assistive robot that controls its own vision according to linguistic instructions. The robot performs several daily tasks such as recording a user's face, hands, or screen, and remotely capturing images of desired locations. To construct such a robot, we combine a pre-trained large-scale vision-language model with a low-cost low-rigidity robot arm. The correlation between the robot's physical and visual information is learned probabilistically using a neural network, and changes in the probability distribution based on changes in time and environment are considered by parametric bias, which is a learnable network input variable. We demonstrate the effectiveness of this learning method by open-vocabulary view control experiments with an actual robot arm, MyCobot.
Neural Architecture Codesign for Fast Bragg Peak Analysis
Dec 12, 2023We develop an automated pipeline to streamline neural architecture codesign for fast, real-time Bragg peak analysis in high-energy diffraction microscopy. Traditional approaches, notably pseudo-Voigt fitting, demand significant computational resources, prompting interest in deep learning models for more efficient solutions. Our method employs neural architecture search and AutoML to enhance these models, including hardware costs, leading to the discovery of more hardware-efficient neural architectures. Our results match the performance, while achieving a 13$\times$ reduction in bit operations compared to the previous state-of-the-art. We show further speedup through model compression techniques such as quantization-aware-training and neural network pruning. Additionally, our hierarchical search space provides greater flexibility in optimization, which can easily extend to other tasks and domains.
MusER: Musical Element-Based Regularization for Generating Symbolic Music with Emotion
Dec 16, 2023Generating music with emotion is an important task in automatic music generation, in which emotion is evoked through a variety of musical elements (such as pitch and duration) that change over time and collaborate with each other. However, prior research on deep learning-based emotional music generation has rarely explored the contribution of different musical elements to emotions, let alone the deliberate manipulation of these elements to alter the emotion of music, which is not conducive to fine-grained element-level control over emotions. To address this gap, we present a novel approach employing musical element-based regularization in the latent space to disentangle distinct elements, investigate their roles in distinguishing emotions, and further manipulate elements to alter musical emotions. Specifically, we propose a novel VQ-VAE-based model named MusER. MusER incorporates a regularization loss to enforce the correspondence between the musical element sequences and the specific dimensions of latent variable sequences, providing a new solution for disentangling discrete sequences. Taking advantage of the disentangled latent vectors, a two-level decoding strategy that includes multiple decoders attending to latent vectors with different semantics is devised to better predict the elements. By visualizing latent space, we conclude that MusER yields a disentangled and interpretable latent space and gain insights into the contribution of distinct elements to the emotional dimensions (i.e., arousal and valence). Experimental results demonstrate that MusER outperforms the state-of-the-art models for generating emotional music in both objective and subjective evaluation. Besides, we rearrange music through element transfer and attempt to alter the emotion of music by transferring emotion-distinguishable elements.
Structured Two-Stage True-Time-Delay Array Codebook Design for Multi-User Data Communication
Nov 15, 2023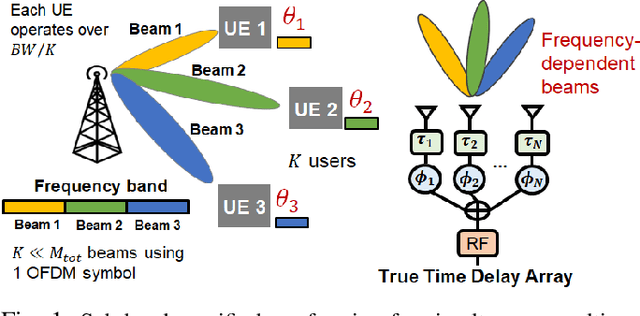
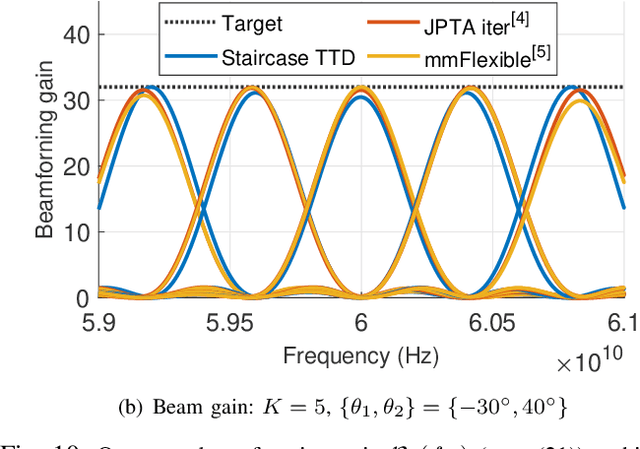
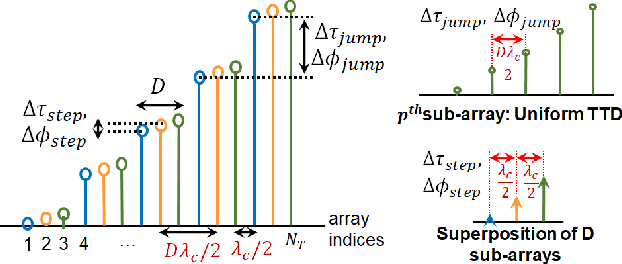
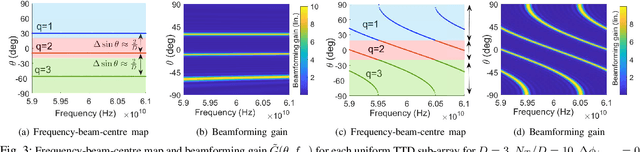
Wideband millimeter-wave and terahertz (THz) systems can facilitate simultaneous data communication with multiple spatially separated users. It is desirable to orthogonalize users across sub-bands by deploying frequency-dependent beams with a sub-band-specific spatial response. True-Time-Delay (TTD) antenna arrays are a promising wideband architecture to implement sub-band-specific dispersion of beams across space using a single radio frequency (RF) chain. This paper proposes a structured design of analog TTD codebooks to generate beams that exhibit quantized sub-band-to-angle mapping. We introduce a structured Staircase TTD codebook and analyze the frequency-spatial behaviour of the resulting beam patterns. We develop the closed-form two-stage design of the proposed codebook to achieve the desired sub-band-specific beams and evaluate their performance in multi-user communication networks.
Multimodal Industrial Anomaly Detection by Crossmodal Feature Mapping
Dec 07, 2023The paper explores the industrial multimodal Anomaly Detection (AD) task, which exploits point clouds and RGB images to localize anomalies. We introduce a novel light and fast framework that learns to map features from one modality to the other on nominal samples. At test time, anomalies are detected by pinpointing inconsistencies between observed and mapped features. Extensive experiments show that our approach achieves state-of-the-art detection and segmentation performance in both the standard and few-shot settings on the MVTec 3D-AD dataset while achieving faster inference and occupying less memory than previous multimodal AD methods. Moreover, we propose a layer-pruning technique to improve memory and time efficiency with a marginal sacrifice in performance.
Raising the ClaSS of Streaming Time Series Segmentation
Oct 31, 2023Ubiquitous sensors today emit high frequency streams of numerical measurements that reflect properties of human, animal, industrial, commercial, and natural processes. Shifts in such processes, e.g. caused by external events or internal state changes, manifest as changes in the recorded signals. The task of streaming time series segmentation (STSS) is to partition the stream into consecutive variable-sized segments that correspond to states of the observed processes or entities. The partition operation itself must in performance be able to cope with the input frequency of the signals. We introduce ClaSS, a novel, efficient, and highly accurate algorithm for STSS. ClaSS assesses the homogeneity of potential partitions using self-supervised time series classification and applies statistical tests to detect significant change points (CPs). In our experimental evaluation using two large benchmarks and six real-world data archives, we found ClaSS to be significantly more precise than eight state-of-the-art competitors. Its space and time complexity is independent of segment sizes and linear only in the sliding window size. We also provide ClaSS as a window operator with an average throughput of 538 data points per second for the Apache Flink streaming engine.
Distributional Latent Variable Models with an Application in Active Cognitive Testing
Dec 14, 2023
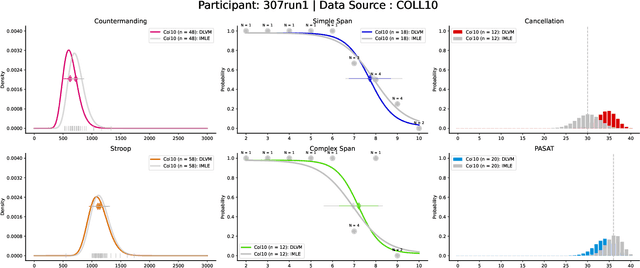
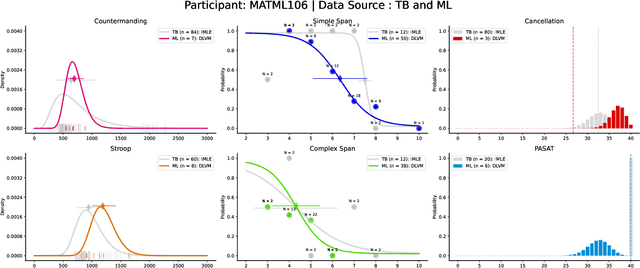
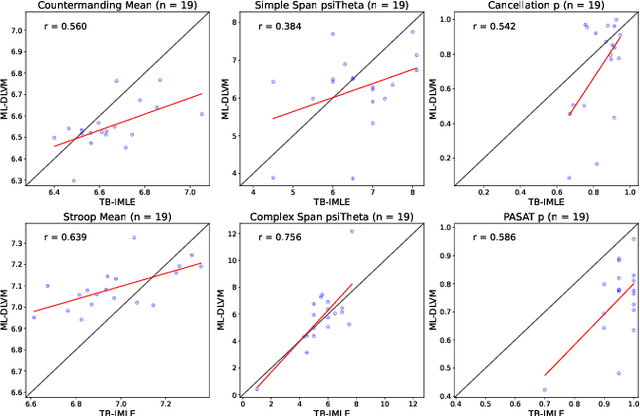
Cognitive modeling commonly relies on asking participants to complete a battery of varied tests in order to estimate attention, working memory, and other latent variables. In many cases, these tests result in highly variable observation models. A near-ubiquitous approach is to repeat many observations for each test, resulting in a distribution over the outcomes from each test given to each subject. In this paper, we explore the usage of latent variable modeling to enable learning across many correlated variables simultaneously. We extend latent variable models (LVMs) to the setting where observed data for each subject are a series of observations from many different distributions, rather than simple vectors to be reconstructed. By embedding test battery results for individuals in a latent space that is trained jointly across a population, we are able to leverage correlations both between tests for a single participant and between multiple participants. We then propose an active learning framework that leverages this model to conduct more efficient cognitive test batteries. We validate our approach by demonstrating with real-time data acquisition that it performs comparably to conventional methods in making item-level predictions with fewer test items.
Learning Long Sequences in Spiking Neural Networks
Dec 14, 2023Spiking neural networks (SNNs) take inspiration from the brain to enable energy-efficient computations. Since the advent of Transformers, SNNs have struggled to compete with artificial networks on modern sequential tasks, as they inherit limitations from recurrent neural networks (RNNs), with the added challenge of training with non-differentiable binary spiking activations. However, a recent renewed interest in efficient alternatives to Transformers has given rise to state-of-the-art recurrent architectures named state space models (SSMs). This work systematically investigates, for the first time, the intersection of state-of-the-art SSMs with SNNs for long-range sequence modelling. Results suggest that SSM-based SNNs can outperform the Transformer on all tasks of a well-established long-range sequence modelling benchmark. It is also shown that SSM-based SNNs can outperform current state-of-the-art SNNs with fewer parameters on sequential image classification. Finally, a novel feature mixing layer is introduced, improving SNN accuracy while challenging assumptions about the role of binary activations in SNNs. This work paves the way for deploying powerful SSM-based architectures, such as large language models, to neuromorphic hardware for energy-efficient long-range sequence modelling.