 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prediction and Control in Continual Reinforcement Learning
Dec 18, 2023
Temporal difference (TD) learning is often used to update the estimate of the value function which is used by RL agents to extract useful policies. In this paper, we focus on value function estimation in continual reinforcement learning. We propose to decompose the value function into two components which update at different timescales: a permanent value function, which holds general knowledge that persists over time, and a transient value function, which allows quick adaptation to new situations. We establish theoretical results showing that our approach is well suited for continual learning and draw connections to the complementary learning systems (CLS) theory from neuroscience. Empirically, this approach improves performance significantly on both prediction and control problems.
BSS-Bench: Towards Reproducible and Effective Band Selection Search
Dec 22, 2023The key technology to overcome the drawbacks of hyperspectral imaging (expensive, high capture delay, and low spatial resolution) and make it widely applicable is to select only a few representative bands from hundreds of bands. However, current band selection (BS) methods face challenges in fair comparisons due to inconsistent train/validation settings, including the number of bands, dataset splits, and retraining settings. To make BS methods easy and reproducible, this paper presents the first band selection search benchmark (BSS-Bench) containing 52k training and evaluation records of numerous band combinations (BC) with different backbones for various hyperspectral analysis tasks. The creation of BSS-Bench required a significant computational effort of 1.26k GPU days. By querying BSS-Bench, BS experiments can be performed easily and reproducibly, and the gap between the searched result and the best achievable performance can be measured. Based on BSS-Bench, we further discuss the impact of various factors on BS, such as the number of bands, unsupervised statistics, and different backbones. In addition to BSS-Bench, we present an effective one-shot BS method called Single Combination One Shot (SCOS), which learns the priority of any BCs through one-time training, eliminating the need for repetitive retraining on different BCs. Furthermore, the search process of SCOS is flexible and does not require training, making it efficient and effective. Our extensive evaluations demonstrate that SCOS outperforms current BS methods on multiple tasks, even with much fewer bands. Our BSS-Bench and codes are available in the supplementary material and will be publicly available.
Dreaming of Electrical Waves: Generative Modeling of Cardiac Excitation Waves using Diffusion Models
Dec 22, 2023Electrical waves in the heart form rotating spiral or scroll waves during life-threatening arrhythmias such as atrial or ventricular fibrillation. The wave dynamics are typically modeled using coupled partial differential equations, which describe reaction-diffusion dynamics in excitable media. More recently, data-driven generative modeling has emerged as an alternative to generate spatio-temporal patterns in physical and biological systems. Here, we explore denoising diffusion probabilistic models for the generative modeling of electrical wave patterns in cardiac tissue. We trained diffusion models with simulated electrical wave patterns to be able to generate such wave patterns in unconditional and conditional generation tasks. For instance, we explored inpainting tasks, such as reconstructing three-dimensional wave dynamics from superficial two-dimensional measurements, and evolving and generating parameter-specific dynamics. We characterized and compared the diffusion-generated solutions to solutions obtained with biophysical models and found that diffusion models learn to replicate spiral and scroll waves dynamics so well that they could serve as an alternative data-driven approach for the modeling of excitation waves in cardiac tissue. For instance, we found that it is possible to initiate ventricular fibrillation (VF) dynamics instantaneously without having to apply pacing protocols in order to induce wavebreak. The VF dynamics can be created in arbitrary ventricular geometries and can be evolved over time. However, we also found that diffusion models `hallucinate' wave patterns when given insufficient constraints. Regardless of these limitations, diffusion models are an interesting and powerful tool with many potential applications in cardiac arrhythmia research and diagnostics.
Real-time unobtrusive sleep monitoring of in-patients with affective disorders: a feasibility study
Nov 22, 2023
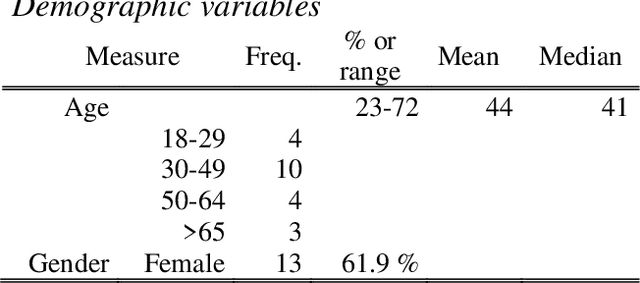
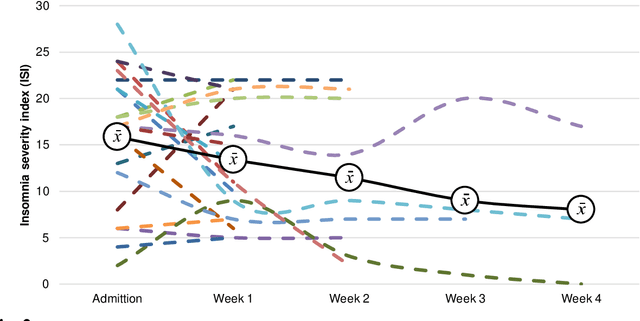
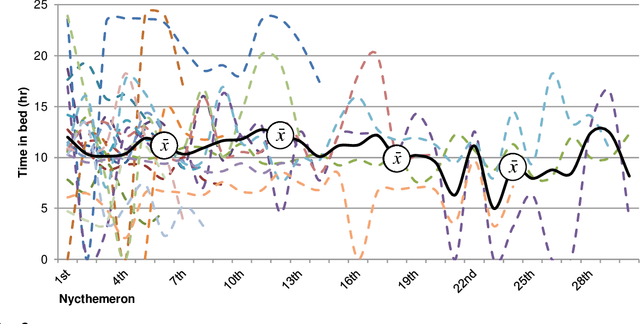
Sleep and mental health are highly related concepts, and it is an important research and clinical priority to understand their interactions. In-bed sensors using ballistocardiography provide the possibility of unobtrusive measurements of sleep. In this study, we examined the feasibility of ballistocardiography in measuring key aspects of sleep in psychiatric in-patients. Specifically, we examined a sample of patients diagnosed with depression and bipolar disorder. The subjective experiences of the researchers conducting the study are explored and descriptive analyses of patient sleep are subsequently presented. The practicalities of using the ballistocardiography device seem to be favourable. There were no apparent issues regarding data quality or data integrity. Of clinical interest, we found no link between length of stay and reduced time in bed (b = -0.06, SE = 0.03, t = -1.76, p = .08). Using ballistocardiography for measurements on in-patients with affective disorders seems to be a feasible approach.
Temporal Supervised Contrastive Learning for Modeling Patient Risk Progression
Dec 10, 2023We consider the problem of predicting how the likelihood of an outcome of interest for a patient changes over time as we observe more of the patient data. To solve this problem, we propose a supervised contrastive learning framework that learns an embedding representation for each time step of a patient time series. Our framework learns the embedding space to have the following properties: (1) nearby points in the embedding space have similar predicted class probabilities, (2) adjacent time steps of the same time series map to nearby points in the embedding space, and (3) time steps with very different raw feature vectors map to far apart regions of the embedding space. To achieve property (3), we employ a nearest neighbor pairing mechanism in the raw feature space. This mechanism also serves as an alternative to data augmentation, a key ingredient of contrastive learning, which lacks a standard procedure that is adequately realistic for clinical tabular data, to our knowledge. We demonstrate that our approach outperforms state-of-the-art baselines in predicting mortality of septic patients (MIMIC-III dataset) and tracking progression of cognitive impairment (ADNI dataset). Our method also consistently recovers the correct synthetic dataset embedding structure across experiments, a feat not achieved by baselines. Our ablation experiments show the pivotal role of our nearest neighbor pairing.
Time-Uniform Confidence Spheres for Means of Random Vectors
Nov 14, 2023We derive and study time-uniform confidence spheres - termed confidence sphere sequences (CSSs) - which contain the mean of random vectors with high probability simultaneously across all sample sizes. Inspired by the original work of Catoni and Giulini, we unify and extend their analysis to cover both the sequential setting and to handle a variety of distributional assumptions. More concretely, our results include an empirical-Bernstein CSS for bounded random vectors (resulting in a novel empirical-Bernstein confidence interval), a CSS for sub-$\psi$ random vectors, and a CSS for heavy-tailed random vectors based on a sequentially valid Catoni-Giulini estimator. Finally, we provide a version of our empirical-Bernstein CSS that is robust to contamination by Huber noise.
BakedAvatar: Baking Neural Fields for Real-Time Head Avatar Synthesis
Nov 09, 2023Synthesizing photorealistic 4D human head avatars from videos is essential for VR/AR, telepresence, and video game applications. Although existing Neural Radiance Fields (NeRF)-based methods achieve high-fidelity results, the computational expense limits their use in real-time applications. To overcome this limitation, we introduce BakedAvatar, a novel representation for real-time neural head avatar synthesis, deployable in a standard polygon rasterization pipeline. Our approach extracts deformable multi-layer meshes from learned isosurfaces of the head and computes expression-, pose-, and view-dependent appearances that can be baked into static textures for efficient rasterization. We thus propose a three-stage pipeline for neural head avatar synthesis, which includes learning continuous deformation, manifold, and radiance fields, extracting layered meshes and textures, and fine-tuning texture details with differential rasterization. Experimental results demonstrate that our representation generates synthesis results of comparable quality to other state-of-the-art methods while significantly reducing the inference time required. We further showcase various head avatar synthesis results from monocular videos, including view synthesis, face reenactment, expression editing, and pose editing, all at interactive frame rates.
* ACM Transactions on Graphics (SIGGRAPH Asia 2023)
Optimised Storage for Datalog Reasoning
Dec 19, 2023Materialisation facilitates Datalog reasoning by precomputing all consequences of the facts and the rules so that queries can be directly answered over the materialised facts. However, storing all materialised facts may be infeasible in practice, especially when the rules are complex and the given set of facts is large. We observe that for certain combinations of rules, there exist data structures that compactly represent the reasoning result and can be efficiently queried when necessary. In this paper, we present a general framework that allows for the integration of such optimised storage schemes with standard materialisation algorithms. Moreover, we devise optimised storage schemes targeting at transitive rules and union rules, two types of (combination of) rules that commonly occur in practice. Our experimental evaluation shows that our approach significantly improves memory consumption, sometimes by orders of magnitude, while remaining competitive in terms of query answering time.
Active contours driven by local and global intensity fitting energy with application to SAR image segmentation and its fast solvers
Dec 19, 2023In this paper, we propose a novel variational active contour model based on Aubert-Aujol (AA) denoising model, which hybrides geodesic active contour (GAC) model with active contours without edges (ACWE) model and can be used to segment images corrupted by multiplicative gamma noise. We transform the proposed model into classic ROF model by adding a proximity term. Inspired by a fast denosing algorithm proposed by Jia-Zhao recently, we propose two fast fixed point algorithms to solve SAR image segmentation question. Experimental results for real SAR images show that the proposed image segmentation model can efficiently stop the contours at weak or blurred edges, and can automatically detect the exterior and interior boundaries of images with multiplicative gamma noise. The proposed fast fixed point algorithms are robustness to initialization contour, and can further reduce about 15% of the time needed for algorithm proposed by Goldstein-Osher.
MineObserver 2.0: A Deep Learning & In-Game Framework for Assessing Natural Language Descriptions of Minecraft Imagery
Dec 19, 2023MineObserver 2.0 is an AI framework that uses Computer Vision and Natural Language Processing for assessing the accuracy of learner-generated descriptions of Minecraft images that include some scientifically relevant content. The system automatically assesses the accuracy of participant observations, written in natural language, made during science learning activities that take place in Minecraft. We demonstrate our system working in real-time and describe a teacher support dashboard to showcase observations, both of which advance our previous work. We present the results of a study showing that MineObserver 2.0 improves over its predecessor both in perceived accuracy of the system's generated descriptions as well as in usefulness of the system's feedback. In future work we intend improve system-generated descriptions, give teachers more control and upgrade the system to perform continuous learning to more effectively and rapidly respond to novel observations made by learners.