 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scalable 3D Reconstruction From Single Particle X-Ray Diffraction Images Based on Online Machine Learning
Dec 22, 2023
X-ray free-electron lasers (XFELs) offer unique capabilities for measuring the structure and dynamics of biomolecules, helping us understand the basic building blocks of life. Notably, high-repetition-rate XFELs enable single particle imaging (X-ray SPI) where individual, weakly scattering biomolecules are imaged under near-physiological conditions with the opportunity to access fleeting states that cannot be captured in cryogenic or crystallized conditions. Existing X-ray SPI reconstruction algorithms, which estimate the unknown orientation of a particle in each captured image as well as its shared 3D structure, are inadequate in handling the massive datasets generated by these emerging XFELs. Here, we introduce X-RAI, an online reconstruction framework that estimates the structure of a 3D macromolecule from large X-ray SPI datasets. X-RAI consists of a convolutional encoder, which amortizes pose estimation over large datasets, as well as a physics-based decoder, which employs an implicit neural representation to enable high-quality 3D reconstruction in an end-to-end, self-supervised manner. We demonstrate that X-RAI achieves state-of-the-art performance for small-scale datasets in simulation and challenging experimental settings and demonstrate its unprecedented ability to process large datasets containing millions of diffraction images in an online fashion. These abilities signify a paradigm shift in X-ray SPI towards real-time capture and reconstruction.
Sampling and estimation on manifolds using the Langevin diffusion
Dec 22, 2023Error bounds are derived for sampling and estimation using a discretization of an intrinsically defined Langevin diffusion with invariant measure $d\mu_\phi \propto e^{-\phi} \mathrm{dvol}_g $ on a compact Riemannian manifold. Two estimators of linear functionals of $\mu_\phi $ based on the discretized Markov process are considered: a time-averaging estimator based on a single trajectory and an ensemble-averaging estimator based on multiple independent trajectories. Imposing no restrictions beyond a nominal level of smoothness on $\phi$, first-order error bounds, in discretization step size, on the bias and variances of both estimators are derived. The order of error matches the optimal rate in Euclidean and flat spaces, and leads to a first-order bound on distance between the invariant measure $\mu_\phi$ and a stationary measure of the discretized Markov process. Generality of the proof techniques, which exploit links between two partial differential equations and the semigroup of operators corresponding to the Langevin diffusion, renders them amenable for the study of a more general class of sampling algorithms related to the Langevin diffusion. Conditions for extending analysis to the case of non-compact manifolds are discussed. Numerical illustrations with distributions, log-concave and otherwise, on the manifolds of positive and negative curvature elucidate on the derived bounds and demonstrate practical utility of the sampling algorithm.
Short-lived High-volume Multi-A(rmed)/B(andits) Testing
Dec 23, 2023Modern platforms leverage randomized experiments to make informed decisions from a given set of items (``treatments''). As a particularly challenging scenario, these items may (i) arrive in high volume, with thousands of new items being released per hour, and (ii) have short lifetime, say, due to the item's transient nature or underlying non-stationarity that impels the platform to perceive the same item as distinct copies over time. Thus motivated, we study a Bayesian multiple-play bandit problem that encapsulates the key features of the multivariate testing (or ``multi-A/B testing'') problem with a high volume of short-lived arms. In each round, a set of $k$ arms arrive, each available for $w$ rounds. Without knowing the mean reward for each arm, the learner selects a multiset of $n$ arms and immediately observes their realized rewards. We aim to minimize the loss due to not knowing the mean rewards, averaged over instances generated from a given prior distribution. We show that when $k = O(n^\rho)$ for some constant $\rho>0$, our proposed policy has $\tilde O(n^{-\min \{\rho, \frac 12 (1+\frac 1w)^{-1}\}})$ loss on a sufficiently large class of prior distributions. We complement this result by showing that every policy suffers $\Omega (n^{-\min \{\rho, \frac 12\}})$ loss on the same class of distributions. We further validate the effectiveness of our policy through a large-scale field experiment on {\em Glance}, a content-card-serving platform that faces exactly the above challenge. A simple variant of our policy outperforms the platform's current recommender by 4.32\% in total duration and 7.48\% in total number of click-throughs.
Decentralised and collaborative machine learning framework for IoT
Dec 19, 2023Decentralised machine learning has recently been proposed as a potential solution to the security issues of the canonical federated learning approach. In this paper, we propose a decentralised and collaborative machine learning framework specially oriented to resource-constrained devices, usual in IoT deployments. With this aim we propose the following construction blocks. First, an incremental learning algorithm based on prototypes that was specifically implemented to work in low-performance computing elements. Second, two random-based protocols to exchange the local models among the computing elements in the network. Finally, two algorithmics approaches for prediction and prototype creation. This proposal was compared to a typical centralized incremental learning approach in terms of accuracy, training time and robustness with very promising results.
An effective image copy-move forgery detection using entropy image
Dec 19, 2023Image forensics has become increasingly important in our daily lives. As a fundamental type of forgeries, Copy-Move Forgery Detection (CMFD) has received significant attention in the academic community. Keypoint-based algorithms, particularly those based on SIFT, have achieved good results in CMFD. However, the most of keypoint detection algorithms often fail to generate sufficient matches when tampered patches are present in smooth areas. To tackle this problem, we introduce entropy images to determine the coordinates and scales of keypoints, resulting significantly increasing the number of keypoints. Furthermore, we develop an entropy level clustering algorithm to avoid increased matching complexity caused by non-ideal distribution of grayscale values in keypoints. Experimental results demonstrate that our algorithm achieves a good balance between performance and time efficiency.
Turing's Test, a Beautiful Thought Experiment
Dec 18, 2023In the wake of large language models, there has been a resurgence of claims and questions about the Turing test and its value for AI, which are reminiscent of decades of practical "Turing" tests. If AI were quantum physics, by now several "Schr\"odinger's" cats could have been killed. Better late than never, it is time for a historical reconstruction of Turing's beautiful thought experiment. In this paper I present a wealth of evidence, including new archival sources, give original answers to several open questions about Turing's 1950 paper, and address the core question of the value of Turing's test.
Analysis of Synchrosqueezed Transforms and Application Perspectives
Dec 11, 2023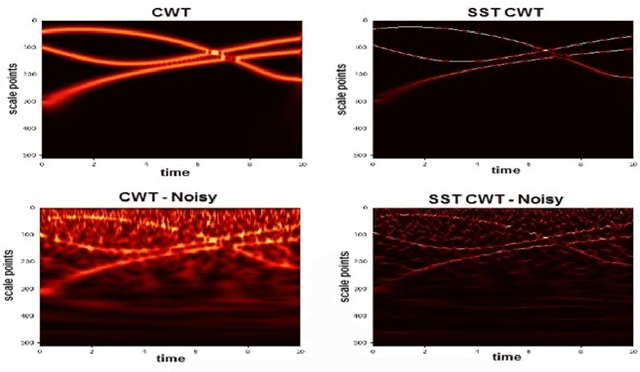
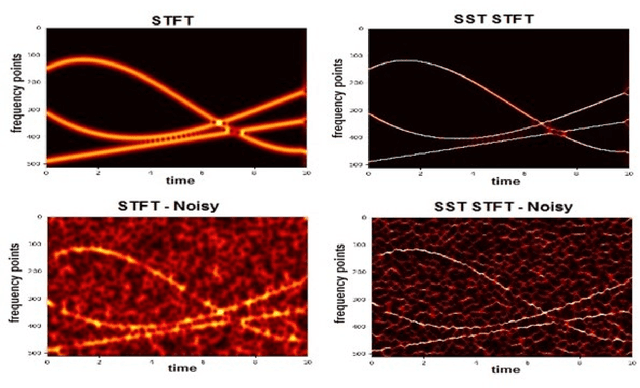
High-resolution time-frequency (TF) analysis plays crucial role in characterizing multicomponent signal (MCSs) and estimating oscillatory properties. Linear time-frequency representations (TFRs) such as classical short-time Fourier transform (STFT) and continuous wavelet transform (CWT) incur constrained TF resolution and energy diffusion in both time and frequency direction. The synchrosqueezing transform (SST) represents a powerful sparse reassignment method that allows component reconstruction. This work introduces SST as extension to STFT and CWT and illustrates corresponding advantages of sharpening TFRs and recovery of instantaneous components. The SST effectiveness is assessed in practical situations that involve comparing STFT-based and CWT-based versions of synthetic data and also applying SST to optimize deep learning (DL) prediction model. It is demonstrated how SST achieves promising results in terms of improving TFR readability and increasing accuracy of DL-based prediction models.
HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs
Dec 21, 2023Current advances in human head modeling allow to generate plausible-looking 3D head models via neural representations. Nevertheless, constructing complete high-fidelity head models with explicitly controlled animation remains an issue. Furthermore, completing the head geometry based on a partial observation, e.g. coming from a depth sensor, while preserving details is often problematic for the existing methods. We introduce a generative model for detailed 3D head meshes on top of an articulated 3DMM which allows explicit animation and high-detail preservation at the same time. Our method is trained in two stages. First, we register a parametric head model with vertex displacements to each mesh of the recently introduced NPHM dataset of accurate 3D head scans. The estimated displacements are baked into a hand-crafted UV layout. Second, we train a StyleGAN model in order to generalize over the UV maps of displacements. The decomposition of the parametric model and high-quality vertex displacements allows us to animate the model and modify it semantically. We demonstrate the results of unconditional generation and fitting to the full or partial observation. The project page is available at https://seva100.github.io/headcraft.
Neural Spline Fields for Burst Image Fusion and Layer Separation
Dec 21, 2023Each photo in an image burst can be considered a sample of a complex 3D scene: the product of parallax, diffuse and specular materials, scene motion, and illuminant variation. While decomposing all of these effects from a stack of misaligned images is a highly ill-conditioned task, the conventional align-and-merge burst pipeline takes the other extreme: blending them into a single image. In this work, we propose a versatile intermediate representation: a two-layer alpha-composited image plus flow model constructed with neural spline fields -- networks trained to map input coordinates to spline control points. Our method is able to, during test-time optimization, jointly fuse a burst image capture into one high-resolution reconstruction and decompose it into transmission and obstruction layers. Then, by discarding the obstruction layer, we can perform a range of tasks including seeing through occlusions, reflection suppression, and shadow removal. Validated on complex synthetic and in-the-wild captures we find that, with no post-processing steps or learned priors, our generalizable model is able to outperform existing dedicated single-image and multi-view obstruction removal approaches.
PlatoNeRF: 3D Reconstruction in Plato's Cave via Single-View Two-Bounce Lidar
Dec 21, 20233D reconstruction from a single-view is challenging because of the ambiguity from monocular cues and lack of information about occluded regions. Neural radiance fields (NeRF), while popular for view synthesis and 3D reconstruction, are typically reliant on multi-view images. Existing methods for single-view 3D reconstruction with NeRF rely on either data priors to hallucinate views of occluded regions, which may not be physically accurate, or shadows observed by RGB cameras, which are difficult to detect in ambient light and low albedo backgrounds. We propose using time-of-flight data captured by a single-photon avalanche diode to overcome these limitations. Our method models two-bounce optical paths with NeRF, using lidar transient data for supervision. By leveraging the advantages of both NeRF and two-bounce light measured by lidar, we demonstrate that we can reconstruct visible and occluded geometry without data priors or reliance on controlled ambient lighting or scene albedo. In addition, we demonstrate improved generalization under practical constraints on sensor spatial- and temporal-resolution. We believe our method is a promising direction as single-photon lidars become ubiquitous on consumer devices, such as phones, tablets, and headsets.