 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Learn in Interactive Constraint Acquisition
Dec 17, 2023
Constraint Programming (CP) has been successfully used to model and solve complex combinatorial problems. However, modeling is often not trivial and requires expertise, which is a bottleneck to wider adoption. In Constraint Acquisition (CA), the goal is to assist the user by automatically learning the model. In (inter)active CA, this is done by interactively posting queries to the user, e.g., asking whether a partial solution satisfies their (unspecified) constraints or not. While interac tive CA methods learn the constraints, the learning is related to symbolic concept learning, as the goal is to learn an exact representation. However, a large number of queries is still required to learn the model, which is a major limitation. In this paper, we aim to alleviate this limitation by tightening the connection of CA and Machine Learning (ML), by, for the first time in interactive CA, exploiting statistical ML methods. We propose to use probabilistic classification models to guide interactive CA to generate more promising queries. We discuss how to train classifiers to predict whether a candidate expression from the bias is a constraint of the problem or not, using both relation-based and scope-based features. We then show how the predictions can be used in all layers of interactive CA: the query generation, the scope finding, and the lowest-level constraint finding. We experimentally evaluate our proposed methods using different classifiers and show that our methods greatly outperform the state of the art, decreasing the number of queries needed to converge by up to 72%.
Addressing Sample Inefficiency in Multi-View Representation Learning
Dec 17, 2023Non-contrastive self-supervised learning (NC-SSL) methods like BarlowTwins and VICReg have shown great promise for label-free representation learning in computer vision. Despite the apparent simplicity of these techniques, researchers must rely on several empirical heuristics to achieve competitive performance, most notably using high-dimensional projector heads and two augmentations of the same image. In this work, we provide theoretical insights on the implicit bias of the BarlowTwins and VICReg loss that can explain these heuristics and guide the development of more principled recommendations. Our first insight is that the orthogonality of the features is more critical than projector dimensionality for learning good representations. Based on this, we empirically demonstrate that low-dimensional projector heads are sufficient with appropriate regularization, contrary to the existing heuristic. Our second theoretical insight suggests that using multiple data augmentations better represents the desiderata of the SSL objective. Based on this, we demonstrate that leveraging more augmentations per sample improves representation quality and trainability. In particular, it improves optimization convergence, leading to better features emerging earlier in the training. Remarkably, we demonstrate that we can reduce the pretraining dataset size by up to 4x while maintaining accuracy and improving convergence simply by using more data augmentations. Combining these insights, we present practical pretraining recommendations that improve wall-clock time by 2x and improve performance on CIFAR-10/STL-10 datasets using a ResNet-50 backbone. Thus, this work provides a theoretical insight into NC-SSL and produces practical recommendations for enhancing its sample and compute efficiency.
Dynamic Neural Fields for Learning Atlases of 4D Fetal MRI Time-series
Nov 06, 2023We present a method for fast biomedical image atlas construction using neural fields. Atlases are key to biomedical image analysis tasks, yet conventional and deep network estimation methods remain time-intensive. In this preliminary work, we frame subject-specific atlas building as learning a neural field of deformable spatiotemporal observations. We apply our method to learning subject-specific atlases and motion stabilization of dynamic BOLD MRI time-series of fetuses in utero. Our method yields high-quality atlases of fetal BOLD time-series with $\sim$5-7$\times$ faster convergence compared to existing work. While our method slightly underperforms well-tuned baselines in terms of anatomical overlap, it estimates templates significantly faster, thus enabling rapid processing and stabilization of large databases of 4D dynamic MRI acquisitions. Code is available at https://github.com/Kidrauh/neural-atlasing
Long-term Time Series Forecasting based on Decomposition and Neural Ordinary Differential Equations
Nov 10, 2023Long-term time series forecasting (LTSF) is a challenging task that has been investigated in various domains such as finance investment, health care, traffic, and weather forecasting. In recent years, Linear-based LTSF models showed better performance, pointing out the problem of Transformer-based approaches causing temporal information loss. However, Linear-based approach has also limitations that the model is too simple to comprehensively exploit the characteristics of the dataset. To solve these limitations, we propose LTSF-DNODE, which applies a model based on linear ordinary differential equations (ODEs) and a time series decomposition method according to data statistical characteristics. We show that LTSF-DNODE outperforms the baselines on various real-world datasets. In addition, for each dataset, we explore the impacts of regularization in the neural ordinary differential equation (NODE) framework.
Once Upon a $\textit{Time}$ in $\textit{Graph}$: Relative-Time Pretraining for Complex Temporal Reasoning
Oct 23, 2023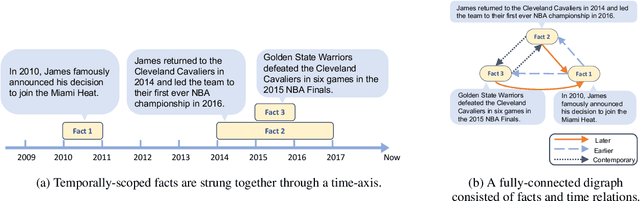
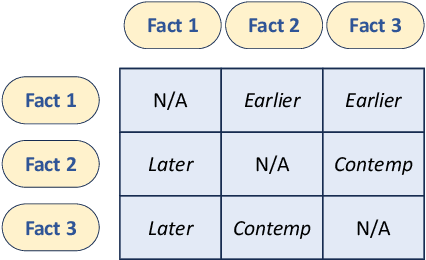
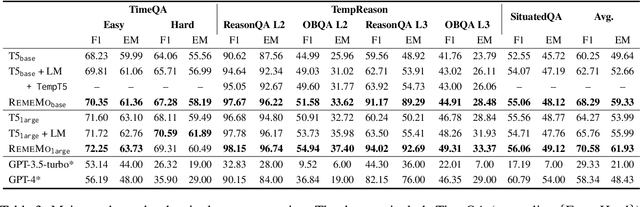
Our physical world is constantly evolving over time, rendering challenges for pre-trained language models to understand and reason over the temporal contexts of texts. Existing work focuses on strengthening the direct association between a piece of text and its time-stamp. However, the knowledge-time association is usually insufficient for the downstream tasks that require reasoning over temporal dependencies between knowledge. In this work, we make use of the underlying nature of time, all temporally-scoped sentences are strung together through a one-dimensional time axis, and suggest creating a graph structure based on the relative placements of events along the time axis. Inspired by the graph view, we propose RemeMo ($\underline{Re}$lative Ti$\underline{me}$ $\underline{Mo}$deling), which explicitly connects all temporally-scoped facts by modeling the time relations between any two sentences. Experimental results show that RemeMo outperforms the baseline T5 on multiple temporal question answering datasets under various settings. Further analysis suggests that RemeMo is especially good at modeling long-range complex temporal dependencies. We release our code and pre-trained checkpoints at $\href{https://github.com/DAMO-NLP-SG/RemeMo}{\text{this url}}$.
Towards small and accurate convolutional neural networks for acoustic biodiversity monitoring
Dec 06, 2023Automated classification of animal sounds is a prerequisite for large-scale monitoring of biodiversity. Convolutional Neural Networks (CNNs) are among the most promising algorithms but they are slow, often achieve poor classification in the field and typically require large training data sets. Our objective was to design CNNs that are fast at inference time and achieve good classification performance while learning from moderate-sized data. Recordings from a rainforest ecosystem were used. Start and end-point of sounds from 20 bird species were manually annotated. Spectrograms from 10 second segments were used as CNN input. We designed simple CNNs with a frequency unwrapping layer (SIMP-FU models) such that any output unit was connected to all spectrogram frequencies but only to a sub-region of time, the Receptive Field (RF). Our models allowed experimentation with different RF durations. Models either used the time-indexed labels that encode start and end-point of sounds or simpler segment-level labels. Models learning from time-indexed labels performed considerably better than their segment-level counterparts. Best classification performances was achieved for models with intermediate RF duration of 1.5 seconds. The best SIMP-FU models achieved AUCs over 0.95 in 18 of 20 classes on the test set. On compact low-cost hardware the best SIMP-FU models evaluated up to seven times faster than real-time data acquisition. RF duration was a major driver of classification performance. The optimum of 1.5 s was in the same range as the duration of the sounds. Our models achieved good classification performance while learning from moderate-sized training data. This is explained by the usage of time-indexed labels during training and adequately sized RF. Results confirm the feasibility of deploying small CNNs with good classification performance on compact low-cost devices.
Improving Event Time Prediction by Learning to Partition the Event Time Space
Oct 24, 2023Recently developed survival analysis methods improve upon existing approaches by predicting the probability of event occurrence in each of a number pre-specified (discrete) time intervals. By avoiding placing strong parametric assumptions on the event density, this approach tends to improve prediction performance, particularly when data are plentiful. However, in clinical settings with limited available data, it is often preferable to judiciously partition the event time space into a limited number of intervals well suited to the prediction task at hand. In this work, we develop a method to learn from data a set of cut points defining such a partition. We show that in two simulated datasets, we are able to recover intervals that match the underlying generative model. We then demonstrate improved prediction performance on three real-world observational datasets, including a large, newly harmonized stroke risk prediction dataset. Finally, we argue that our approach facilitates clinical decision-making by suggesting time intervals that are most appropriate for each task, in the sense that they facilitate more accurate risk prediction.
TIA: A Teaching Intonation Assessment Dataset in Real Teaching Situations
Dec 14, 2023Intonation is one of the important factors affecting the teaching language arts, so it is an urgent problem to be addressed by evaluating the teachers' intonation through artificial intelligence technology. However, the lack of an intonation assessment dataset has hindered the development of the field. To this end, this paper constructs a Teaching Intonation Assessment (TIA) dataset for the first time in real teaching situations. This dataset covers 9 disciplines, 396 teachers, total of 11,444 utterance samples with a length of 15 seconds. In order to test the validity of the dataset, this paper proposes a teaching intonation assessment model (TIAM) based on low-level and deep-level features of speech. The experimental results show that TIAM based on the dataset constructed in this paper is basically consistent with the results of manual evaluation, and the results are better than the baseline models, which proves the effectiveness of the evaluation model.
Bayes3D: fast learning and inference in structured generative models of 3D objects and scenes
Dec 14, 2023Robots cannot yet match humans' ability to rapidly learn the shapes of novel 3D objects and recognize them robustly despite clutter and occlusion. We present Bayes3D, an uncertainty-aware perception system for structured 3D scenes, that reports accurate posterior uncertainty over 3D object shape, pose, and scene composition in the presence of clutter and occlusion. Bayes3D delivers these capabilities via a novel hierarchical Bayesian model for 3D scenes and a GPU-accelerated coarse-to-fine sequential Monte Carlo algorithm. Quantitative experiments show that Bayes3D can learn 3D models of novel objects from just a handful of views, recognizing them more robustly and with orders of magnitude less training data than neural baselines, and tracking 3D objects faster than real time on a single GPU. We also demonstrate that Bayes3D learns complex 3D object models and accurately infers 3D scene composition when used on a Panda robot in a tabletop scenario.
Towards Automatic Data Augmentation for Disordered Speech Recognition
Dec 14, 2023Automatic recognition of disordered speech remains a highly challenging task to date due to data scarcity. This paper presents a reinforcement learning (RL) based on-the-fly data augmentation approach for training state-of-the-art PyChain TDNN and end-to-end Conformer ASR systems on such data. The handcrafted temporal and spectral mask operations in the standard SpecAugment method that are task and system dependent, together with additionally introduced minimum and maximum cut-offs of these time-frequency masks, are now automatically learned using an RNN-based policy controller and tightly integrated with ASR system training. Experiments on the UASpeech corpus suggest the proposed RL-based data augmentation approach consistently produced performance superior or comparable that obtained using expert or handcrafted SpecAugment policies. Our RL auto-augmented PyChain TDNN system produced an overall WER of 28.79% on the UASpeech test set of 16 dysarthric speakers.