 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Convex Landscape of Neural Networks: Characterizing Global Optima and Stationary Points via Lasso Models
Dec 19, 2023
Due to the non-convex nature of training Deep Neural Network (DNN) models, their effectiveness relies on the use of non-convex optimization heuristics. Traditional methods for training DNNs often require costly empirical methods to produce successful models and do not have a clear theoretical foundation. In this study, we examine the use of convex optimization theory and sparse recovery models to refine the training process of neural networks and provide a better interpretation of their optimal weights. We focus on training two-layer neural networks with piecewise linear activations and demonstrate that they can be formulated as a finite-dimensional convex program. These programs include a regularization term that promotes sparsity, which constitutes a variant of group Lasso. We first utilize semi-infinite programming theory to prove strong duality for finite width neural networks and then we express these architectures equivalently as high dimensional convex sparse recovery models. Remarkably, the worst-case complexity to solve the convex program is polynomial in the number of samples and number of neurons when the rank of the data matrix is bounded, which is the case in convolutional networks. To extend our method to training data of arbitrary rank, we develop a novel polynomial-time approximation scheme based on zonotope subsampling that comes with a guaranteed approximation ratio. We also show that all the stationary of the nonconvex training objective can be characterized as the global optimum of a subsampled convex program. Our convex models can be trained using standard convex solvers without resorting to heuristics or extensive hyper-parameter tuning unlike non-convex methods. Through extensive numerical experiments, we show that convex models can outperform traditional non-convex methods and are not sensitive to optimizer hyperparameters.
Detecting Technical Debt Using Natural Language Processing Approaches -- A Systematic Literature Review
Dec 19, 2023Context: Technical debt (TD) is a well-known metaphor for the long-term effects of architectural decisions in software development and the trade-off between producing high-quality, effective, and efficient code and meeting a release schedule. Thus, the code degrades and needs refactoring. A lack of resources, time, knowledge, or experience on the development team might cause TD in any software development project. Objective: In the context of TD detection, NLP has been utilized to identify the presence of TD automatically and even recognize specific types of TD. However, the enormous variety of feature extraction approaches and ML/DL algorithms employed in the literature often hinders researchers from trying to improve their performance. Method: In light of this, this SLR proposes a taxonomy of feature extraction techniques and algorithms used in technical debt detection: its objective is to compare and benchmark their performance in the examined studies. Results: We selected 55 articles that passed the quality evaluation of this SLR. We then investigated which feature extractions and algorithms were employed to identify TD in each SDLC phase. All approaches proposed in the analyzed studies were grouped into NLP, NLP+ML, and NLP+DL. This allows us to discuss the performance in three different ways. Conclusion: Overall, the NLP+DL group consistently outperforms in precision and F1-score for all projects, and in all but one project for the recall metric. Regarding the feature extraction techniques, the PTWE consistently achieves higher precision, recall, and F1-score for each project analyzed. Furthermore, TD types have been mapped, when possible, to SDLC phases: this served to determine the best-performing feature extractions and algorithms for each SDLC phase. Finally, based on the SLR results, we also identify implications that could be of concern to researchers and practitioners.
FourierGNN: Rethinking Multivariate Time Series Forecasting from a Pure Graph Perspective
Nov 10, 2023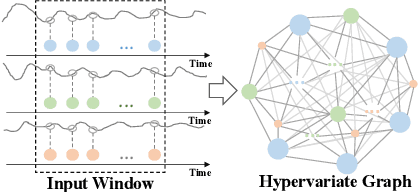
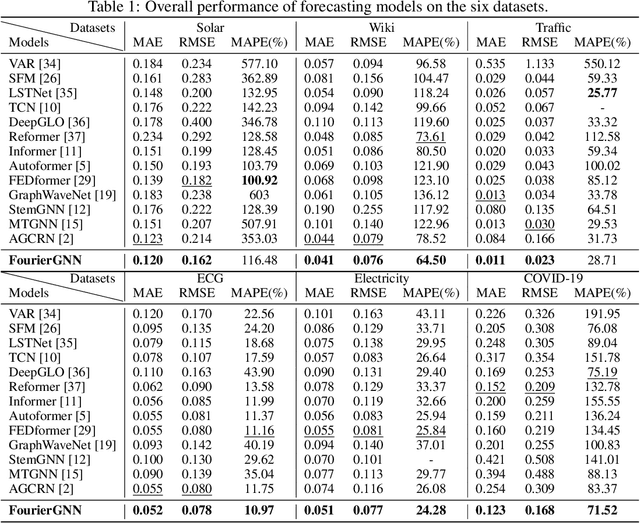

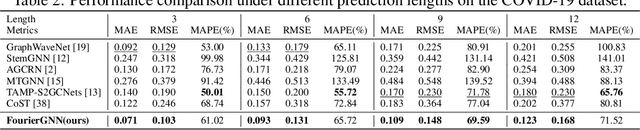
Multivariate time series (MTS) forecasting has shown great importance in numerous industries. Current state-of-the-art graph neural network (GNN)-based forecasting methods usually require both graph networks (e.g., GCN) and temporal networks (e.g., LSTM) to capture inter-series (spatial) dynamics and intra-series (temporal) dependencies, respectively. However, the uncertain compatibility of the two networks puts an extra burden on handcrafted model designs. Moreover, the separate spatial and temporal modeling naturally violates the unified spatiotemporal inter-dependencies in real world, which largely hinders the forecasting performance. To overcome these problems, we explore an interesting direction of directly applying graph networks and rethink MTS forecasting from a pure graph perspective. We first define a novel data structure, hypervariate graph, which regards each series value (regardless of variates or timestamps) as a graph node, and represents sliding windows as space-time fully-connected graphs. This perspective considers spatiotemporal dynamics unitedly and reformulates classic MTS forecasting into the predictions on hypervariate graphs. Then, we propose a novel architecture Fourier Graph Neural Network (FourierGNN) by stacking our proposed Fourier Graph Operator (FGO) to perform matrix multiplications in Fourier space. FourierGNN accommodates adequate expressiveness and achieves much lower complexity, which can effectively and efficiently accomplish the forecasting. Besides, our theoretical analysis reveals FGO's equivalence to graph convolutions in the time domain, which further verifies the validity of FourierGNN. Extensive experiments on seven datasets have demonstrated our superior performance with higher efficiency and fewer parameters compared with state-of-the-art methods.
Multi Time Scale World Models
Oct 27, 2023Intelligent agents use internal world models to reason and make predictions about different courses of their actions at many scales. Devising learning paradigms and architectures that allow machines to learn world models that operate at multiple levels of temporal abstractions while dealing with complex uncertainty predictions is a major technical hurdle. In this work, we propose a probabilistic formalism to learn multi-time scale world models which we call the Multi Time Scale State Space (MTS3) model. Our model uses a computationally efficient inference scheme on multiple time scales for highly accurate long-horizon predictions and uncertainty estimates over several seconds into the future. Our experiments, which focus on action conditional long horizon future predictions, show that MTS3 outperforms recent methods on several system identification benchmarks including complex simulated and real-world dynamical systems.
Collaborative Learning for Annotation-Efficient Volumetric MR Image Segmentation
Dec 18, 2023Background: Deep learning has presented great potential in accurate MR image segmentation when enough labeled data are provided for network optimization. However, manually annotating 3D MR images is tedious and time-consuming, requiring experts with rich domain knowledge and experience. Purpose: To build a deep learning method exploring sparse annotations, namely only a single 2D slice label for each 3D training MR image. Population: 3D MR images of 150 subjects from two publicly available datasets were included. Among them, 50 (1,377 image slices) are for prostate segmentation. The other 100 (8,800 image slices) are for left atrium segmentation. Five-fold cross-validation experiments were carried out utilizing the first dataset. For the second dataset, 80 subjects were used for training and 20 were used for testing. Assessment: A collaborative learning method by integrating the strengths of semi-supervised and self-supervised learning schemes was developed. The method was trained using labeled central slices and unlabeled non-central slices. Segmentation performance on testing set was reported quantitatively and qualitatively. Results: Compared to FS-LCS, MT, UA-MT, DCT-Seg, ICT, and AC-MT, the proposed method achieved a substantial improvement in segmentation accuracy, increasing the mean B-IoU significantly by more than 10.0% for prostate segmentation (proposed method B-IoU: 70.3% vs. ICT B-IoU: 60.3%) and by more than 6.0% for left atrium segmentation (proposed method B-IoU: 66.1% vs. ICT B-IoU: 60.1%).
Satellite Captioning: Large Language Models to Augment Labeling
Dec 18, 2023With the growing capabilities of modern object detection networks and datasets to train them, it has gotten more straightforward and, importantly, less laborious to get up and running with a model that is quite adept at detecting any number of various objects. However, while image datasets for object detection have grown and continue to proliferate (the current most extensive public set, ImageNet, contains over 14m images with over 14m instances), the same cannot be said for textual caption datasets. While they have certainly been growing in recent years, caption datasets present a much more difficult challenge due to language differences, grammar, and the time it takes for humans to generate them. Current datasets have certainly provided many instances to work with, but it becomes problematic when a captioner may have a more limited vocabulary, one may not be adequately fluent in the language, or there are simple grammatical mistakes. These difficulties are increased when the images get more specific, such as remote sensing images. This paper aims to address this issue of potential information and communication shortcomings in caption datasets. To provide a more precise analysis, we specify our domain of images to be remote sensing images in the RSICD dataset and experiment with the captions provided here. Our findings indicate that ChatGPT grammar correction is a simple and effective way to increase the performance accuracy of caption models by making data captions more diverse and grammatically correct.
M3T: Multi-Scale Memory Matching for Video Object Segmentation and Tracking
Dec 13, 2023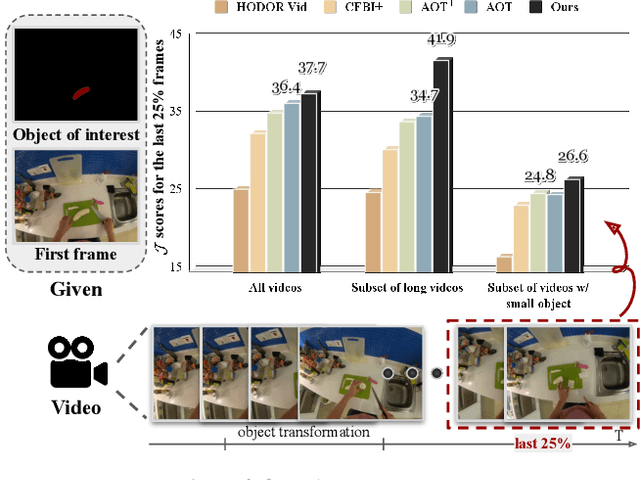

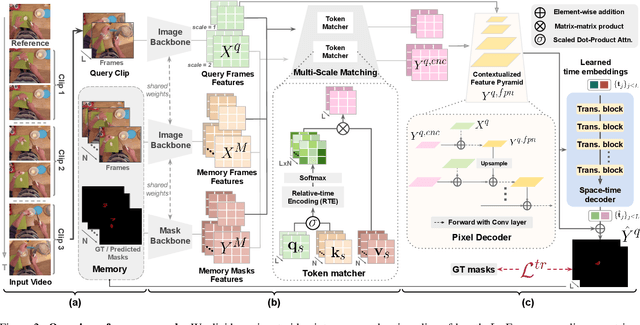
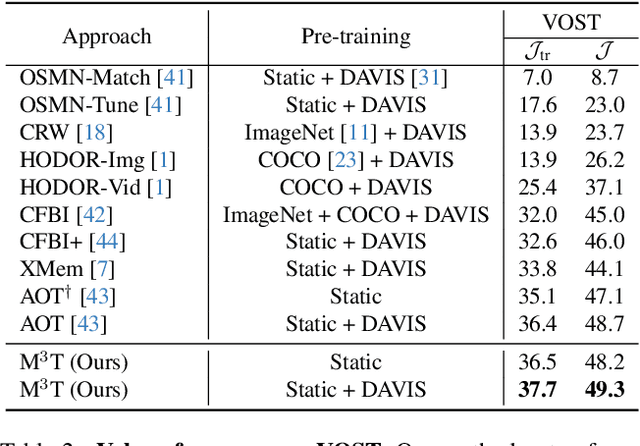
Video Object Segmentation (VOS) has became increasingly important with availability of larger datasets and more complex and realistic settings, which involve long videos with global motion (e.g, in egocentric settings), depicting small objects undergoing both rigid and non-rigid (including state) deformations. While a number of recent approaches have been explored for this task, these data characteristics still present challenges. In this work we propose a novel, DETR-style encoder-decoder architecture, which focuses on systematically analyzing and addressing aforementioned challenges. Specifically, our model enables on-line inference with long videos in a windowed fashion, by breaking the video into clips and propagating context among them using time-coded memory. We illustrate that short clip length and longer memory with learned time-coding are important design choices for achieving state-of-the-art (SoTA) performance. Further, we propose multi-scale matching and decoding to ensure sensitivity and accuracy for small objects. Finally, we propose a novel training strategy that focuses learning on portions of the video where an object undergoes significant deformations -- a form of "soft" hard-negative mining, implemented as loss-reweighting. Collectively, these technical contributions allow our model to achieve SoTA performance on two complex datasets -- VISOR and VOST. A series of detailed ablations validate our design choices as well as provide insights into the importance of parameter choices and their impact on performance.
An Incentive Mechanism for Federated Learning Based on Multiple Resource Exchange
Dec 13, 2023Federated Learning (FL) is a distributed machine learning paradigm that addresses privacy concerns in machine learning and still guarantees high test accuracy. However, achieving the necessary accuracy by having all clients participate in FL is impractical, given the constraints of client local computing resource. In this paper, we introduce a multi-user collaborative computing framework, categorizing users into two roles: model owners (MOs) and data owner (DOs). Without resorting to monetary incentives, an MO can encourage more DOs to join in FL by allowing the DOs to offload extra local computing tasks to the MO for execution. This exchange of "data" for "computing resources" streamlines the incentives for clients to engage more effectively in FL. We formulate the interaction between MO and DOs as an optimization problem, and the objective is to effectively utilize the communication and computing resource of the MO and DOs to minimize the time to complete an FL task. The proposed problem is a mixed integer nonlinear programming (MINLP) with high computational complexity. We first decompose it into two distinct subproblems, namely the client selection problem and the resource allocation problem to segregate the integer variables from the continuous variables. Then, an effective iterative algorithm is proposed to solve problem. Simulation results demonstrate that the proposed collaborative computing framework can achieve an accuracy of more than 95\% while minimizing the overall time to complete an FL task.
NeuroFlow: Development of lightweight and efficient model integration scheduling strategy for autonomous driving system
Dec 15, 2023This paper proposes a specialized autonomous driving system that takes into account the unique constraints and characteristics of automotive systems, aiming for innovative advancements in autonomous driving technology. The proposed system systematically analyzes the intricate data flow in autonomous driving and provides functionality to dynamically adjust various factors that influence deep learning models. Additionally, for algorithms that do not rely on deep learning models, the system analyzes the flow to determine resource allocation priorities. In essence, the system optimizes data flow and schedules efficiently to ensure real-time performance and safety. The proposed system was implemented in actual autonomous vehicles and experimentally validated across various driving scenarios. The experimental results provide evidence of the system's stable inference and effective control of autonomous vehicles, marking a significant turning point in the development of autonomous driving systems.
Online Saddle Point Problem and Online Convex-Concave Optimization
Dec 15, 2023Centered around solving the Online Saddle Point problem, this paper introduces the Online Convex-Concave Optimization (OCCO) framework, which involves a sequence of two-player time-varying convex-concave games. We propose the generalized duality gap (Dual-Gap) as the performance metric and establish the parallel relationship between OCCO with Dual-Gap and Online Convex Optimization (OCO) with regret. To demonstrate the natural extension of OCCO from OCO, we develop two algorithms, the implicit online mirror descent-ascent and its optimistic variant. Analysis reveals that their duality gaps share similar expression forms with the corresponding dynamic regrets arising from implicit updates in OCO. Empirical results further substantiate the effectiveness of our algorithms. Simultaneously, we unveil that the dynamic Nash equilibrium regret, which was initially introduced in a recent paper, has inherent defects.