 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Novel ML-driven Test Case Selection Approach for Enhancing the Performance of Grammatical Evolution
Dec 21, 2023
Computational cost in metaheuristics such as Evolutionary Algorithms (EAs) is often a major concern, particularly with their ability to scale. In data-based training, traditional EAs typically use a significant portion, if not all, of the dataset for model training and fitness evaluation in each generation. This makes EAs suffer from high computational costs incurred during the fitness evaluation of the population, particularly when working with large datasets. To mitigate this issue, we propose a Machine Learning (ML)-driven Distance-based Selection (DBS) algorithm that reduces the fitness evaluation time by optimizing test cases. We test our algorithm by applying it to 24 benchmark problems from Symbolic Regression (SR) and digital circuit domains and then using Grammatical Evolution (GE) to train models using the reduced dataset. We use GE to test DBS on SR and produce a system flexible enough to test it on digital circuit problems further. The quality of the solutions is tested and compared against the conventional training method to measure the coverage of training data selected using DBS, i.e., how well the subset matches the statistical properties of the entire dataset. Moreover, the effect of optimized training data on run time and the effective size of the evolved solutions is analyzed. Experimental and statistical evaluations of the results show our method empowered GE to yield superior or comparable solutions to the baseline (using the full datasets) with smaller sizes and demonstrates computational efficiency in terms of speed.
Leveraging Visual Supervision for Array-based Active Speaker Detection and Localization
Dec 21, 2023Conventional audio-visual approaches for active speaker detection (ASD) typically rely on visually pre-extracted face tracks and the corresponding single-channel audio to find the speaker in a video. Therefore, they tend to fail every time the face of the speaker is not visible. We demonstrate that a simple audio convolutional recurrent neural network (CRNN) trained with spatial input features extracted from multichannel audio can perform simultaneous horizontal active speaker detection and localization (ASDL), independently of the visual modality. To address the time and cost of generating ground truth labels to train such a system, we propose a new self-supervised training pipeline that embraces a ``student-teacher'' learning approach. A conventional pre-trained active speaker detector is adopted as a ``teacher'' network to provide the position of the speakers as pseudo-labels. The multichannel audio ``student'' network is trained to generate the same results. At inference, the student network can generalize and locate also the occluded speakers that the teacher network is not able to detect visually, yielding considerable improvements in recall rate. Experiments on the TragicTalkers dataset show that an audio network trained with the proposed self-supervised learning approach can exceed the performance of the typical audio-visual methods and produce results competitive with the costly conventional supervised training. We demonstrate that improvements can be achieved when minimal manual supervision is introduced in the learning pipeline. Further gains may be sought with larger training sets and integrating vision with the multichannel audio system.
PUMA: Efficient Continual Graph Learning with Graph Condensation
Dec 22, 2023When handling streaming graphs, existing graph representation learning models encounter a catastrophic forgetting problem, where previously learned knowledge of these models is easily overwritten when learning with newly incoming graphs. In response, Continual Graph Learning emerges as a novel paradigm enabling graph representation learning from static to streaming graphs. Our prior work, CaT is a replay-based framework with a balanced continual learning procedure, which designs a small yet effective memory bank for replaying data by condensing incoming graphs. Although the CaT alleviates the catastrophic forgetting problem, there exist three issues: (1) The graph condensation algorithm derived in CaT only focuses on labelled nodes while neglecting abundant information carried by unlabelled nodes; (2) The continual training scheme of the CaT overemphasises on the previously learned knowledge, limiting the model capacity to learn from newly added memories; (3) Both the condensation process and replaying process of the CaT are time-consuming. In this paper, we propose a psudo-label guided memory bank (PUMA) CGL framework, extending from the CaT to enhance its efficiency and effectiveness by overcoming the above-mentioned weaknesses and limits. To fully exploit the information in a graph, PUMA expands the coverage of nodes during graph condensation with both labelled and unlabelled nodes. Furthermore, a training-from-scratch strategy is proposed to upgrade the previous continual learning scheme for a balanced training between the historical and the new graphs. Besides, PUMA uses a one-time prorogation and wide graph encoders to accelerate the graph condensation and the graph encoding process in the training stage to improve the efficiency of the whole framework. Extensive experiments on four datasets demonstrate the state-of-the-art performance and efficiency over existing methods.
Amortized Reparametrization: Efficient and Scalable Variational Inference for Latent SDEs
Dec 16, 2023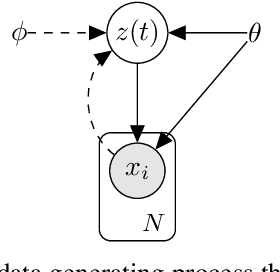
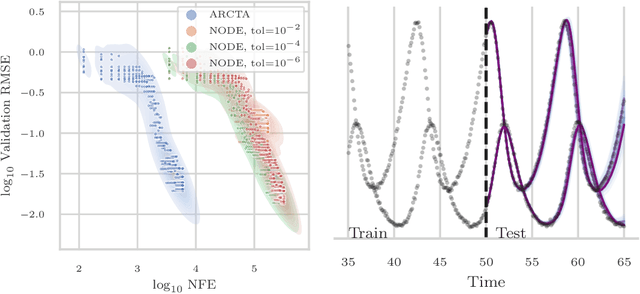
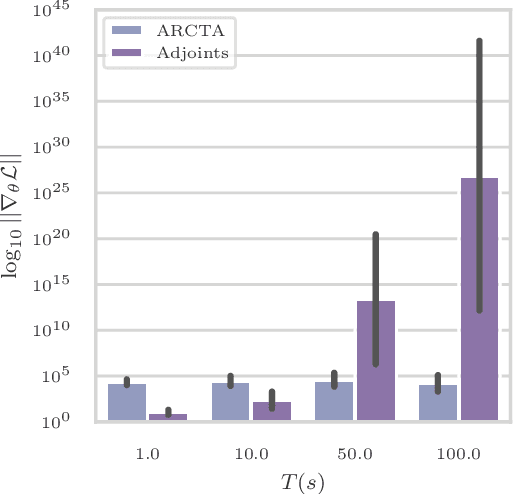
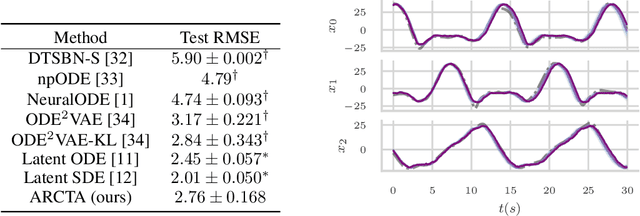
We consider the problem of inferring latent stochastic differential equations (SDEs) with a time and memory cost that scales independently with the amount of data, the total length of the time series, and the stiffness of the approximate differential equations. This is in stark contrast to typical methods for inferring latent differential equations which, despite their constant memory cost, have a time complexity that is heavily dependent on the stiffness of the approximate differential equation. We achieve this computational advancement by removing the need to solve differential equations when approximating gradients using a novel amortization strategy coupled with a recently derived reparametrization of expectations under linear SDEs. We show that, in practice, this allows us to achieve similar performance to methods based on adjoint sensitivities with more than an order of magnitude fewer evaluations of the model in training.
Target detection using underwater acoustic communication links
Dec 18, 2023Underwater monitoring and surveillance systems are essential for underwater target detection, localization and classification. The aim of this work is to investigate the possibility of target detection by using data transmission between communication nodes in an underwater acoustic (UWA) network, i.e, re-using acoustic communication signals for target detection. A new target detection method based on estimation of the time-varying channel impulse response between the communication transmitter(s) and receiver(s) is proposed and investigated. This is based on a lake experiment and numerical experiments using a simulator developed for modeling the time-varying UWA channel in the presence of a moving target. The proposed detection method provides a clear indication of a target crossing the communication link. A good similarity between results obtained in the numerical and lake experiments is observed.
Few-shot Learning using Data Augmentation and Time-Frequency Transformation for Time Series Classification
Nov 06, 2023
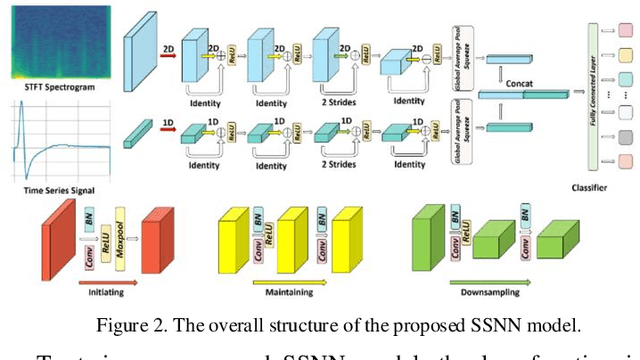
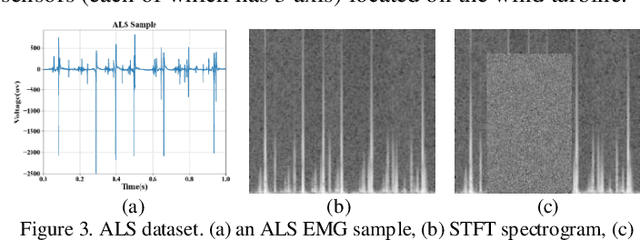
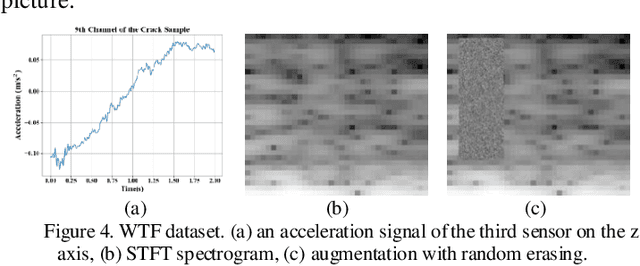
Deep neural networks (DNNs) that tackle the time series classification (TSC) task have provided a promising framework in signal processing. In real-world applications, as a data-driven model, DNNs are suffered from insufficient data. Few-shot learning has been studied to deal with this limitation. In this paper, we propose a novel few-shot learning framework through data augmentation, which involves transformation through the time-frequency domain and the generation of synthetic images through random erasing. Additionally, we develop a sequence-spectrogram neural network (SSNN). This neural network model composes of two sub-networks: one utilizing 1D residual blocks to extract features from the input sequence while the other one employing 2D residual blocks to extract features from the spectrogram representation. In the experiments, comparison studies of different existing DNN models with/without data augmentation are conducted on an amyotrophic lateral sclerosis (ALS) dataset and a wind turbine fault (WTF) dataset. The experimental results manifest that our proposed method achieves 93.75% F1 score and 93.33% accuracy on the ALS datasets while 95.48% F1 score and 95.59% accuracy on the WTF datasets. Our methodology demonstrates its applicability of addressing the few-shot problems for time series classification.
Combinatorial Gaussian Process Bandits in Bayesian Settings: Theory and Application for Energy-Efficient Navigation
Dec 20, 2023We consider a combinatorial Gaussian process semi-bandit problem with time-varying arm availability. Each round, an agent is provided a set of available base arms and must select a subset of them to maximize the long-term cumulative reward. Assuming the expected rewards are sampled from a Gaussian process (GP) over the arm space, the agent can efficiently learn. We study the Bayesian setting and provide novel Bayesian regret bounds for three GP-based algorithms: GP-UCB, Bayes-GP-UCB and GP-TS. Our bounds extend previous results for GP-UCB and GP-TS to a combinatorial setting with varying arm availability and to the best of our knowledge, we provide the first Bayesian regret bound for Bayes-GP-UCB. Time-varying arm availability encompasses other widely considered bandit problems such as contextual bandits. We formulate the online energy-efficient navigation problem as a combinatorial and contextual bandit and provide a comprehensive experimental study on synthetic and real-world road networks with detailed simulations. The contextual GP model obtains lower regret and is less dependent on the informativeness of the prior compared to the non-contextual Bayesian inference model. In addition, Thompson sampling obtains lower regret than Bayes-UCB for both the contextual and non-contextual model.
AnimatableDreamer: Text-Guided Non-rigid 3D Model Generation and Reconstruction with Canonical Score Distillation
Dec 20, 2023Text-to-3D model adaptations have advanced static 3D model quality, but sequential 3D model generation, particularly for animatable objects with large motions, is still scarce. Our work proposes AnimatableDreamer, a text-to-4D generation framework capable of generating diverse categories of non-rigid objects while adhering to the object motions extracted from a monocular video. At its core, AnimatableDreamer is equipped with our novel optimization design dubbed Canonical Score Distillation (CSD), which simplifies the generation dimension from 4D to 3D by denoising over different frames in the time-varying camera spaces while conducting the distillation process in a unique canonical space shared per video. Concretely, CSD ensures that score gradients back-propagate to the canonical space through differentiable warping, hence guaranteeing the time-consistent generation and maintaining morphological plausibility across different poses. By lifting the 3D generator to 4D with warping functions, AnimatableDreamer offers a novel perspective on non-rigid 3D model generation and reconstruction. Besides, with inductive knowledge from a multi-view consistent diffusion model, CSD regularizes reconstruction from novel views, thus cyclically enhancing the generation process. Extensive experiments demonstrate the capability of our method in generating high-flexibility text-guided 3D models from the monocular video, while also showing improved reconstruction performance over typical non-rigid reconstruction methods. Project page https://AnimatableDreamer.github.io.
INFAMOUS-NeRF: ImproviNg FAce MOdeling Using Semantically-Aligned Hypernetworks with Neural Radiance Fields
Dec 23, 2023We propose INFAMOUS-NeRF, an implicit morphable face model that introduces hypernetworks to NeRF to improve the representation power in the presence of many training subjects. At the same time, INFAMOUS-NeRF resolves the classic hypernetwork tradeoff of representation power and editability by learning semantically-aligned latent spaces despite the subject-specific models, all without requiring a large pretrained model. INFAMOUS-NeRF further introduces a novel constraint to improve NeRF rendering along the face boundary. Our constraint can leverage photometric surface rendering and multi-view supervision to guide surface color prediction and improve rendering near the surface. Finally, we introduce a novel, loss-guided adaptive sampling method for more effective NeRF training by reducing the sampling redundancy. We show quantitatively and qualitatively that our method achieves higher representation power than prior face modeling methods in both controlled and in-the-wild settings. Code and models will be released upon publication.
Monitoring the Evolution of Behavioural Embeddings in Social Media Recommendation
Dec 23, 2023Short video applications pose unique challenges for recommender systems due to the constant influx of new content and the absence of historical user interactions for quality assessment of uploaded content. This research characterizes the evolution of embeddings in short video recommendation systems, comparing batch and real-time updates to content embeddings. The analysis investigates embedding maturity, the learning peak during view accumulation, popularity bias, l2-norm distribution of learned embeddings, and their impact on user engagement metrics. The study unveils the contrast in the number of interactions needed to achieve mature embeddings in both learning modes, identifies the ideal learning point, and explores the distribution of l2-norm across various update methods. Utilizing a production system deployed on a large-scale short video app with over 180 million users, the findings offer insights into designing effective recommendation systems and enhancing user satisfaction and engagement in short video applications.