 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Recurrent Reinforcement Learning
Nov 08, 2023
Recent advances in reinforcement learning, for partially-observable Markov decision processes (POMDPs), rely on the biologically implausible backpropagation through time algorithm (BPTT) to perform gradient-descent optimisation. In this paper we propose a novel reinforcement learning algorithm that makes use of random feedback local online learning (RFLO), a biologically plausible approximation of realtime recurrent learning (RTRL) to compute the gradients of the parameters of a recurrent neural network in an online manner. By combining it with TD($\lambda$), a variant of temporaldifference reinforcement learning with eligibility traces, we create a biologically plausible, recurrent actor-critic algorithm, capable of solving discrete and continuous control tasks in POMDPs. We compare BPTT, RTRL and RFLO as well as different network architectures, and find that RFLO can perform just as well as RTRL while exceeding even BPTT in terms of complexity. The proposed method, called real-time recurrent reinforcement learning (RTRRL), serves as a model of learning in biological neural networks mimicking reward pathways in the mammalian brain.
Room Acoustic Rendering Networks with Control of Scattering and Early Reflections
Dec 22, 2023Room acoustic synthesis can be used in Virtual Reality (VR), Augmented Reality (AR) and gaming applications to enhance listeners' sense of immersion, realism and externalisation. A common approach is to use Geometrical Acoustics (GA) models to compute impulse responses at interactive speed, and fast convolution methods to apply said responses in real time. Alternatively, delay-network-based models are capable of modeling certain aspects of room acoustics, but with a significantly lower computational cost. In order to bridge the gap between these classes of models, recent work introduced delay network designs that approximate Acoustic Radiance Transfer (ART), a GA model that simulates the transfer of acoustic energy between discrete surface patches in an environment. This paper presents two key extensions of such designs. The first extension involves a new physically-based and stability-preserving design of the feedback matrices, enabling more accurate control of scattering and, more in general, of late reverberation properties. The second extension allows an arbitrary number of early reflections to be modeled with high accuracy, meaning the network can be scaled at will between computational cost and early reverb precision. The proposed extensions are compared to the baseline ART-approximating delay network as well as two reference GA models. The evaluation is based on objective measures of perceptually-relevant features, including frequency-dependent reverberation times, echo density build-up, and early decay time. Results show how the proposed extensions result in a significant improvement over the baseline model, especially for the case of non-convex geometries or the case of unevenly distributed wall absorption, both scenarios of broad practical interest.
The Economics of Human Oversight: How Norms and Incentives Affect Costs and Performance of AI Workers
Dec 22, 2023The global surge in AI applications is transforming industries, leading to displacement and complementation of existing jobs, while also giving rise to new employment opportunities. Human oversight of AI is an emerging task in which human workers interact with an AI model to improve its performance, safety, and compliance with normative principles. Data annotation, encompassing the labelling of images or annotating of texts, serves as a critical human oversight process, as the quality of a dataset directly influences the quality of AI models trained on it. Therefore, the efficiency of human oversight work stands as an important competitive advantage for AI developers. This paper delves into the foundational economics of human oversight, with a specific focus on the impact of norm design and monetary incentives on data quality and costs. An experimental study involving 307 data annotators examines six groups with varying task instructions (norms) and monetary incentives. Results reveal that annotators provided with clear rules exhibit higher accuracy rates, outperforming those with vague standards by 14%. Similarly, annotators receiving an additional monetary incentive perform significantly better, with the highest accuracy rate recorded in the group working with both clear rules and incentives (87.5% accuracy). However, both groups require more time to complete tasks, with a 31% increase in average task completion time compared to those working with standards and no incentives. These empirical findings underscore the trade-off between data quality and efficiency in data curation, shedding light on the nuanced impact of norm design and incentives on the economics of AI development. The paper contributes experimental insights to discussions on the economical, ethical, and legal considerations of AI technologies.
Real-Time Neural Rasterization for Large Scenes
Nov 09, 2023We propose a new method for realistic real-time novel-view synthesis (NVS) of large scenes. Existing neural rendering methods generate realistic results, but primarily work for small scale scenes (<50 square meters) and have difficulty at large scale (>10000 square meters). Traditional graphics-based rasterization rendering is fast for large scenes but lacks realism and requires expensive manually created assets. Our approach combines the best of both worlds by taking a moderate-quality scaffold mesh as input and learning a neural texture field and shader to model view-dependant effects to enhance realism, while still using the standard graphics pipeline for real-time rendering. Our method outperforms existing neural rendering methods, providing at least 30x faster rendering with comparable or better realism for large self-driving and drone scenes. Our work is the first to enable real-time rendering of large real-world scenes.
Dynamic Topic Language Model on Heterogeneous Children's Mental Health Clinical Notes
Dec 19, 2023Mental health diseases affect children's lives and well-beings which have received increased attention since the COVID-19 pandemic. Analyzing psychiatric clinical notes with topic models is critical to evaluate children's mental status over time. However, few topic models are built for longitudinal settings, and they fail to keep consistent topics and capture temporal trajectories for each document. To address these challenges, we develop a longitudinal topic model with time-invariant topics and individualized temporal dependencies on the evolving document metadata. Our model preserves the semantic meaning of discovered topics over time and incorporates heterogeneity among documents. In particular, when documents can be categorized, we propose an unsupervised topics learning approach to maximize topic heterogeneity across different document groups. We also present an efficient variational optimization procedure adapted for the multistage longitudinal setting. In this case study, we apply our method to the psychiatric clinical notes from a large tertiary pediatric hospital in Southern California and achieve a 38% increase in the overall coherence of extracted topics. Our real data analysis reveals that children tend to express more negative emotions during state shutdowns and more positive when schools reopen. Furthermore, it suggests that sexual and gender minority (SGM) children display more pronounced reactions to major COVID-19 events and a greater sensitivity to vaccine-related news than non-SGM children. This study examines the progression of children's mental health during the pandemic and offers clinicians valuable insights to recognize the disparities in children's mental health related to their sexual and gender identities.
Satellite-based feature extraction and multivariate time-series prediction of biotoxin contamination in shellfish
Nov 25, 2023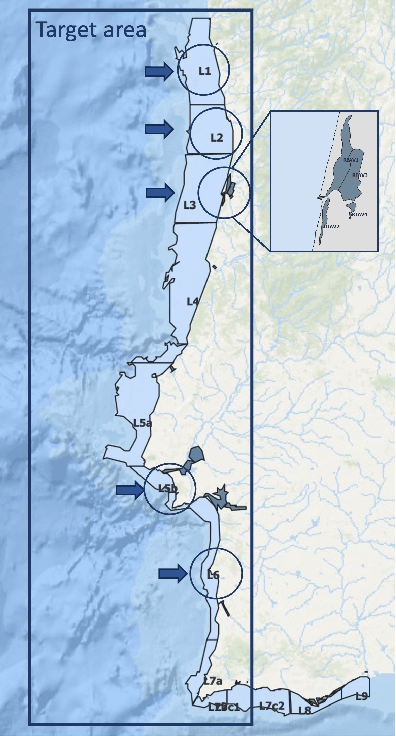
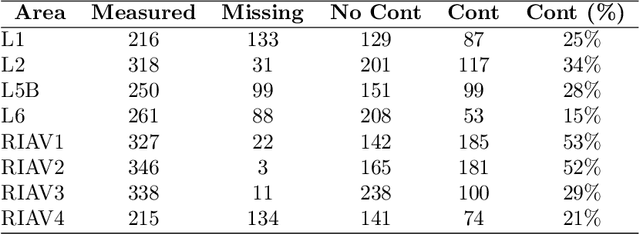
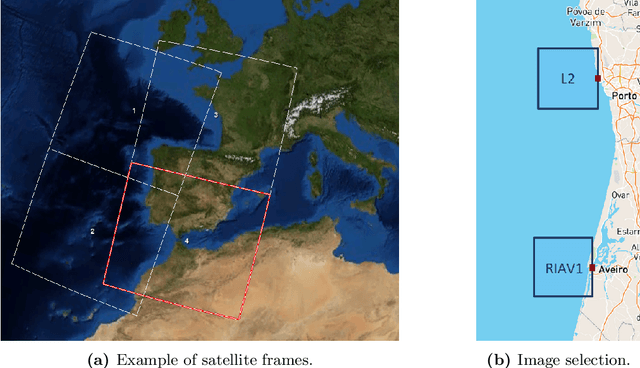

Shellfish production constitutes an important sector for the economy of many Portuguese coastal regions, yet the challenge of shellfish biotoxin contamination poses both public health concerns and significant economic risks. Thus, predicting shellfish contamination levels holds great potential for enhancing production management and safeguarding public health. In our study, we utilize a dataset with years of Sentinel-3 satellite imagery for marine surveillance, along with shellfish biotoxin contamination data from various production areas along Portugal's western coastline, collected by Portuguese official control. Our goal is to evaluate the integration of satellite data in forecasting models for predicting toxin concentrations in shellfish given forecasting horizons up to four weeks, which implies extracting a small set of useful features and assessing their impact on the predictive models. We framed this challenge as a time-series forecasting problem, leveraging historical contamination levels and satellite images for designated areas. While contamination measurements occurred weekly, satellite images were accessible multiple times per week. Unsupervised feature extraction was performed using autoencoders able to handle non-valid pixels caused by factors like cloud cover, land, or anomalies. Finally, several Artificial Neural Networks models were applied to compare univariate (contamination only) and multivariate (contamination and satellite data) time-series forecasting. Our findings show that incorporating these features enhances predictions, especially beyond one week in lagoon production areas (RIAV) and for the 1-week and 2-week horizons in the L5B area (oceanic). The methodology shows the feasibility of integrating information from a high-dimensional data source like remote sensing without compromising the model's predictive ability.
DMC4ML: Data Movement Complexity for Machine Learning
Dec 22, 2023The greatest demand for today's computing is machine learning. This paper analyzes three machine learning algorithms: transformers, spatial convolution, and FFT. The analysis is novel in three aspects. First, it measures the cost of memory access on an abstract memory hierarchy, instead of traditional time or space complexity. Second, the analysis is asymptotic and identifies the primary sources of the memory cost. Finally, the result is symbolic, which can be used to select algorithmic parameters such as the group size in grouped query attention for any dimension size and number of heads and the batch size for batched convolution for any image size and kernel size.
Turn Down the Noise: Leveraging Diffusion Models for Test-time Adaptation via Pseudo-label Ensembling
Nov 29, 2023The goal of test-time adaptation is to adapt a source-pretrained model to a continuously changing target domain without relying on any source data. Typically, this is either done by updating the parameters of the model (model adaptation) using inputs from the target domain or by modifying the inputs themselves (input adaptation). However, methods that modify the model suffer from the issue of compounding noisy updates whereas methods that modify the input need to adapt to every new data point from scratch while also struggling with certain domain shifts. We introduce an approach that leverages a pre-trained diffusion model to project the target domain images closer to the source domain and iteratively updates the model via pseudo-label ensembling. Our method combines the advantages of model and input adaptations while mitigating their shortcomings. Our experiments on CIFAR-10C demonstrate the superiority of our approach, outperforming the strongest baseline by an average of 1.7% across 15 diverse corruptions and surpassing the strongest input adaptation baseline by an average of 18%.
DSPy Assertions: Computational Constraints for Self-Refining Language Model Pipelines
Dec 20, 2023Chaining language model (LM) calls as composable modules is fueling a new powerful way of programming. However, ensuring that LMs adhere to important constraints remains a key challenge, one often addressed with heuristic "prompt engineering". We introduce LM Assertions, a new programming construct for expressing computational constraints that LMs should satisfy. We integrate our constructs into the recent DSPy programming model for LMs, and present new strategies that allow DSPy to compile programs with arbitrary LM Assertions into systems that are more reliable and more accurate. In DSPy, LM Assertions can be integrated at compile time, via automatic prompt optimization, and/or at inference time, via automatic selfrefinement and backtracking. We report on two early case studies for complex question answering (QA), in which the LM program must iteratively retrieve information in multiple hops and synthesize a long-form answer with citations. We find that LM Assertions improve not only compliance with imposed rules and guidelines but also enhance downstream task performance, delivering intrinsic and extrinsic gains up to 35.7% and 13.3%, respectively. Our reference implementation of LM Assertions is integrated into DSPy at https://github.com/stanfordnlp/dspy
ORBSLAM3-Enhanced Autonomous Toy Drones: Pioneering Indoor Exploration
Dec 20, 2023Navigating toy drones through uncharted GPS-denied indoor spaces poses significant difficulties due to their reliance on GPS for location determination. In such circumstances, the necessity for achieving proper navigation is a primary concern. In response to this formidable challenge, we introduce a real-time autonomous indoor exploration system tailored for drones equipped with a monocular \emph{RGB} camera. Our system utilizes \emph{ORB-SLAM3}, a state-of-the-art vision feature-based SLAM, to handle both the localization of toy drones and the mapping of unmapped indoor terrains. Aside from the practicability of \emph{ORB-SLAM3}, the generated maps are represented as sparse point clouds, making them prone to the presence of outlier data. To address this challenge, we propose an outlier removal algorithm with provable guarantees. Furthermore, our system incorporates a novel exit detection algorithm, ensuring continuous exploration by the toy drone throughout the unfamiliar indoor environment. We also transform the sparse point to ensure proper path planning using existing path planners. To validate the efficacy and efficiency of our proposed system, we conducted offline and real-time experiments on the autonomous exploration of indoor spaces. The results from these endeavors demonstrate the effectiveness of our methods.