 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
iKUN: Speak to Trackers without Retraining
Dec 25, 2023
Referring multi-object tracking (RMOT) aims to track multiple objects based on input textual descriptions. Previous works realize it by simply integrating an extra textual module into the multi-object tracker. However, they typically need to retrain the entire framework and have difficulties in optimization. In this work, we propose an insertable Knowledge Unification Network, termed iKUN, to enable communication with off-the-shelf trackers in a plug-and-play manner. Concretely, a knowledge unification module (KUM) is designed to adaptively extract visual features based on textual guidance. Meanwhile, to improve the localization accuracy, we present a neural version of Kalman filter (NKF) to dynamically adjust process noise and observation noise based on the current motion status. Moreover, to address the problem of open-set long-tail distribution of textual descriptions, a test-time similarity calibration method is proposed to refine the confidence score with pseudo frequency. Extensive experiments on Refer-KITTI dataset verify the effectiveness of our framework. Finally, to speed up the development of RMOT, we also contribute a more challenging dataset, Refer-Dance, by extending public DanceTrack dataset with motion and dressing descriptions. The code and dataset will be released in https://github.com/dyhBUPT/iKUN.
Swap-based Deep Reinforcement Learning for Facility Location Problems in Networks
Dec 25, 2023Facility location problems on graphs are ubiquitous in real world and hold significant importance, yet their resolution is often impeded by NP-hardness. Recently, machine learning methods have been proposed to tackle such classical problems, but they are limited to the myopic constructive pattern and only consider the problems in Euclidean space. To overcome these limitations, we propose a general swap-based framework that addresses the p-median problem and the facility relocation problem on graphs and a novel reinforcement learning model demonstrating a keen awareness of complex graph structures. Striking a harmonious balance between solution quality and running time, our method surpasses handcrafted heuristics on intricate graph datasets. Additionally, we introduce a graph generation process to simulate real-world urban road networks with demand, facilitating the construction of large datasets for the classic problem. For the initialization of the locations of facilities, we introduce a physics-inspired strategy for the p-median problem, reaching more stable solutions than the random strategy. The proposed pipeline coupling the classic swap-based method with deep reinforcement learning marks a significant step forward in addressing the practical challenges associated with facility location on graphs.
Inherently Interpretable Time Series Classification via Multiple Instance Learning
Nov 16, 2023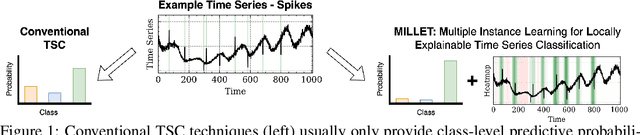

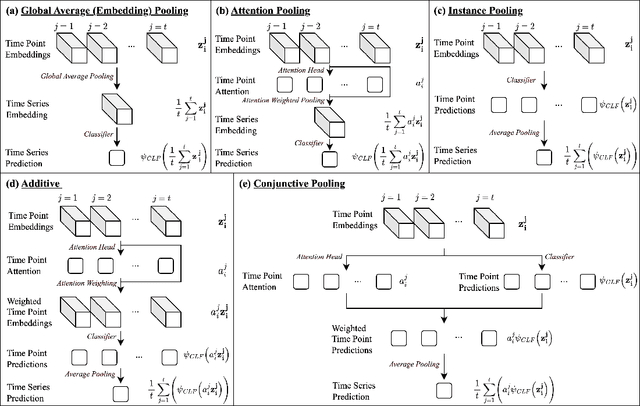
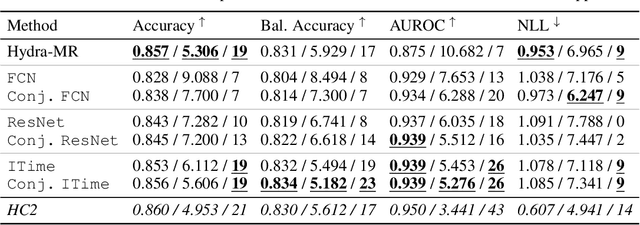
Conventional Time Series Classification (TSC) methods are often black boxes that obscure inherent interpretation of their decision-making processes. In this work, we leverage Multiple Instance Learning (MIL) to overcome this issue, and propose a new framework called MILLET: Multiple Instance Learning for Locally Explainable Time series classification. We apply MILLET to existing deep learning TSC models and show how they become inherently interpretable without compromising (and in some cases, even improving) predictive performance. We evaluate MILLET on 85 UCR TSC datasets and also present a novel synthetic dataset that is specially designed to facilitate interpretability evaluation. On these datasets, we show MILLET produces sparse explanations quickly that are of higher quality than other well-known interpretability methods. To the best of our knowledge, our work with MILLET, which is available on GitHub (https://github.com/JAEarly/MILTimeSeriesClassification), is the first to develop general MIL methods for TSC and apply them to an extensive variety of domains
Do Bayesian Neural Networks Weapon System Improve Predictive Maintenance?
Dec 16, 2023We implement a Bayesian inference process for Neural Networks to model the time to failure of highly reliable weapon systems with interval-censored data and time-varying covariates. We analyze and benchmark our approach, LaplaceNN, on synthetic and real datasets with standard classification metrics such as Receiver Operating Characteristic (ROC) Area Under Curve (AUC) Precision-Recall (PR) AUC, and reliability curve visualizations.
AdaNAS: Adaptively Post-processing with Self-supervised Neural Architecture Search for Ensemble Rainfall Forecasts
Dec 26, 2023Previous post-processing studies on rainfall forecasts using numerical weather prediction (NWP) mainly focus on statistics-based aspects, while learning-based aspects are rarely investigated. Although some manually-designed models are proposed to raise accuracy, they are customized networks, which need to be repeatedly tried and verified, at a huge cost in time and labor. Therefore, a self-supervised neural architecture search (NAS) method without significant manual efforts called AdaNAS is proposed in this study to perform rainfall forecast post-processing and predict rainfall with high accuracy. In addition, we design a rainfall-aware search space to significantly improve forecasts for high-rainfall areas. Furthermore, we propose a rainfall-level regularization function to eliminate the effect of noise data during the training. Validation experiments have been performed under the cases of \emph{None}, \emph{Light}, \emph{Moderate}, \emph{Heavy} and \emph{Violent} on a large-scale precipitation benchmark named TIGGE. Finally, the average mean-absolute error (MAE) and average root-mean-square error (RMSE) of the proposed AdaNAS model are 0.98 and 2.04 mm/day, respectively. Additionally, the proposed AdaNAS model is compared with other neural architecture search methods and previous studies. Compared results reveal the satisfactory performance and superiority of the proposed AdaNAS model in terms of precipitation amount prediction and intensity classification. Concretely, the proposed AdaNAS model outperformed previous best-performing manual methods with MAE and RMSE improving by 80.5\% and 80.3\%, respectively.
Large Language Model (LLM) Bias Index -- LLMBI
Dec 26, 2023The Large Language Model Bias Index (LLMBI) is a pioneering approach designed to quantify and address biases inherent in large language models (LLMs), such as GPT-4. We recognise the increasing prevalence and impact of LLMs across diverse sectors. This research introduces a novel metric, LLMBI, to systematically measure and mitigate biases potentially skewing model responses. We formulated LLMBI using a composite scoring system incorporating multiple dimensions of bias, including but not limited to age, gender, and racial biases. To operationalise this metric, we engaged in a multi-step process involving collecting and annotating LLM responses, applying sophisticated Natural Language Processing (NLP) techniques for bias detection, and computing the LLMBI score through a specially crafted mathematical formula. The formula integrates weighted averages of various bias dimensions, a penalty for dataset diversity deficiencies, and a correction for sentiment biases. Our empirical analysis, conducted using responses from OpenAI's API, employs advanced sentiment analysis as a representative method for bias detection. The research reveals LLMs, whilst demonstrating impressive capabilities in text generation, exhibit varying degrees of bias across different dimensions. LLMBI provides a quantifiable measure to compare biases across models and over time, offering a vital tool for systems engineers, researchers and regulators in enhancing the fairness and reliability of LLMs. It highlights the potential of LLMs in mimicking unbiased human-like responses. Additionally, it underscores the necessity of continuously monitoring and recalibrating such models to align with evolving societal norms and ethical standards.
A DRL solution to help reduce the cost in waiting time of securing a traffic light for cyclists
Nov 23, 2023Cyclists prefer to use infrastructure that separates them from motorized traffic. Using a traffic light to segregate car and bike flows, with the addition of bike-specific green phases, is a lightweight and cheap solution that can be deployed dynamically to assess the opportunity of a heavier infrastructure such as a separate bike lane. To compensate for the increased waiting time induced by these new phases, we introduce in this paper a deep reinforcement learning solution that adapts the green phase cycle of a traffic light to the traffic. Vehicle counter data are used to compare the DRL approach with the actuated traffic light control algorithm over whole days. Results show that DRL achieves better minimization of vehicle waiting time at almost all hours. Our DRL approach is also robust to moderate changes in bike traffic. The code of this paper is available at https://github.com/LucasMagnana/A-DRL-solution-to-help-reduce-the-cost-in-waiting-time-of-securing-a-traffic-light-for-cyclists.
Indoor and Outdoor 3D Scene Graph Generation via Language-Enabled Spatial Ontologies
Dec 18, 2023This paper proposes an approach to build 3D scene graphs in arbitrary (indoor and outdoor) environments. Such extension is challenging; the hierarchy of concepts that describe an outdoor environment is more complex than for indoors, and manually defining such hierarchy is time-consuming and does not scale. Furthermore, the lack of training data prevents the straightforward application of learning-based tools used in indoor settings. To address these challenges, we propose two novel extensions. First, we develop methods to build a spatial ontology defining concepts and relations relevant for indoor and outdoor robot operation. In particular, we use a Large Language Model (LLM) to build such an ontology, thus largely reducing the amount of manual effort required. Second, we leverage the spatial ontology for 3D scene graph construction using Logic Tensor Networks (LTN) to add logical rules, or axioms (e.g., "a beach contains sand"), which provide additional supervisory signals at training time thus reducing the need for labelled data, providing better predictions, and even allowing predicting concepts unseen at training time. We test our approach in a variety of datasets, including indoor, rural, and coastal environments, and show that it leads to a significant increase in the quality of the 3D scene graph generation with sparsely annotated data.
Towards Fairness in Online Service with k Servers and its Application on Fair Food Delivery
Dec 18, 2023The k-SERVER problem is one of the most prominent problems in online algorithms with several variants and extensions. However, simplifying assumptions like instantaneous server movements and zero service time has hitherto limited its applicability to real-world problems. In this paper, we introduce a realistic generalization of k-SERVER without such assumptions - the k-FOOD problem, where requests with source-destination locations and an associated pickup time window arrive in an online fashion, and each has to be served by exactly one of the available k servers. The k-FOOD problem offers the versatility to model a variety of real-world use cases such as food delivery, ride sharing, and quick commerce. Moreover, motivated by the need for fairness in online platforms, we introduce the FAIR k-FOOD problem with the max-min objective. We establish that both k-FOOD and FAIR k-FOOD problems are strongly NP-hard and develop an optimal offline algorithm that arises naturally from a time-expanded flow network. Subsequently, we propose an online algorithm DOC4FOOD involving virtual movements of servers to the nearest request location. Experiments on a real-world food-delivery dataset, alongside synthetic datasets, establish the efficacy of the proposed algorithm against state-of-the-art fair food delivery algorithms.
SAIC: Integration of Speech Anonymization and Identity Classification
Dec 23, 2023Speech anonymization and de-identification have garnered significant attention recently, especially in the healthcare area including telehealth consultations, patient voiceprint matching, and patient real-time monitoring. Speaker identity classification tasks, which involve recognizing specific speakers from audio to learn identity features, are crucial for de-identification. Since rare studies have effectively combined speech anonymization with identity classification, we propose SAIC - an innovative pipeline for integrating Speech Anonymization and Identity Classification. SAIC demonstrates remarkable performance and reaches state-of-the-art in the speaker identity classification task on the Voxceleb1 dataset, with a top-1 accuracy of 96.1%. Although SAIC is not trained or evaluated specifically on clinical data, the result strongly proves the model's effectiveness and the possibility to generalize into the healthcare area, providing insightful guidance for future work.