 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Q-Segment: Segmenting Images In-Sensor for Vessel-Based Medical Diagnosis
Dec 22, 2023
This paper addresses the growing interest in deploying deep learning models directly in-sensor. We present "Q-Segment", a quantized real-time segmentation algorithm, and conduct a comprehensive evaluation on a low-power edge vision platform with an in-sensors processor, the Sony IMX500. One of the main goals of the model is to achieve end-to-end image segmentation for vessel-based medical diagnosis. Deployed on the IMX500 platform, Q-Segment achieves ultra-low inference time in-sensor only 0.23 ms and power consumption of only 72mW. We compare the proposed network with state-of-the-art models, both float and quantized, demonstrating that the proposed solution outperforms existing networks on various platforms in computing efficiency, e.g., by a factor of 75x compared to ERFNet. The network employs an encoder-decoder structure with skip connections, and results in a binary accuracy of 97.25% and an Area Under the Receiver Operating Characteristic Curve (AUC) of 96.97% on the CHASE dataset. We also present a comparison of the IMX500 processing core with the Sony Spresense, a low-power multi-core ARM Cortex-M microcontroller, and a single-core ARM Cortex-M4 showing that it can achieve in-sensor processing with end-to-end low latency (17 ms) and power concumption (254mW). This research contributes valuable insights into edge-based image segmentation, laying the foundation for efficient algorithms tailored to low-power environments.
Conditional Image Generation with Pretrained Generative Model
Dec 20, 2023In recent years, diffusion models have gained popularity for their ability to generate higher-quality images in comparison to GAN models. However, like any other large generative models, these models require a huge amount of data, computational resources, and meticulous tuning for successful training. This poses a significant challenge, rendering it infeasible for most individuals. As a result, the research community has devised methods to leverage pre-trained unconditional diffusion models with additional guidance for the purpose of conditional image generative. These methods enable conditional image generations on diverse inputs and, most importantly, circumvent the need for training the diffusion model. In this paper, our objective is to reduce the time-required and computational overhead introduced by the addition of guidance in diffusion models -- while maintaining comparable image quality. We propose a set of methods based on our empirical analysis, demonstrating a reduction in computation time by approximately threefold.
AUGCAL: Improving Sim2Real Adaptation by Uncertainty Calibration on Augmented Synthetic Images
Dec 19, 2023Synthetic data (SIM) drawn from simulators have emerged as a popular alternative for training models where acquiring annotated real-world images is difficult. However, transferring models trained on synthetic images to real-world applications can be challenging due to appearance disparities. A commonly employed solution to counter this SIM2REAL gap is unsupervised domain adaptation, where models are trained using labeled SIM data and unlabeled REAL data. Mispredictions made by such SIM2REAL adapted models are often associated with miscalibration - stemming from overconfident predictions on real data. In this paper, we introduce AUGCAL, a simple training-time patch for unsupervised adaptation that improves SIM2REAL adapted models by - (1) reducing overall miscalibration, (2) reducing overconfidence in incorrect predictions and (3) improving confidence score reliability by better guiding misclassification detection - all while retaining or improving SIM2REAL performance. Given a base SIM2REAL adaptation algorithm, at training time, AUGCAL involves replacing vanilla SIM images with strongly augmented views (AUG intervention) and additionally optimizing for a training time calibration loss on augmented SIM predictions (CAL intervention). We motivate AUGCAL using a brief analytical justification of how to reduce miscalibration on unlabeled REAL data. Through our experiments, we empirically show the efficacy of AUGCAL across multiple adaptation methods, backbones, tasks and shifts.
Task-Parameterized Imitation Learning with Time-Sensitive Constraints
Dec 06, 2023Programming a robot manipulator should be as intuitive as possible. To achieve that, the paradigm of teaching motion skills by providing few demonstrations has become widely popular in recent years. Probabilistic versions thereof take into account the uncertainty given by the distribution of the training data. However, precise execution of start-, via-, and end-poses at given times can not always be guaranteed. This limits the technology transfer to industrial application. To address this problem, we propose a novel constrained formulation of the Expectation Maximization algorithm for learning Gaussian Mixture Models (GMM) on Riemannian Manifolds. Our approach applies to probabilistic imitation learning and extends also to the well-established TP-GMM framework with Task-Parameterization. It allows to prescribe end-effector poses at defined execution times, for instance for precise pick & place scenarios. The probabilistic approach is compared with state-of-the-art learning-from-demonstration methods using the KUKA LBR iiwa robot. The reader is encouraged to watch the accompanying video available at https://youtu.be/JMI1YxtN9C0
Cross-Layer Optimization for Fault-Tolerant Deep Learning
Dec 21, 2023Fault-tolerant deep learning accelerator is the basis for highly reliable deep learning processing and critical to deploy deep learning in safety-critical applications such as avionics and robotics. Since deep learning is known to be computing- and memory-intensive, traditional fault-tolerant approaches based on redundant computing will incur substantial overhead including power consumption and chip area. To this end, we propose to characterize deep learning vulnerability difference across both neurons and bits of each neuron, and leverage the vulnerability difference to enable selective protection of the deep learning processing components from the perspective of architecture layer and circuit layer respectively. At the same time, we observe the correlation between model quantization and bit protection overhead of the underlying processing elements of deep learning accelerators, and propose to reduce the bit protection overhead by adding additional quantization constrain without compromising the model accuracy. Finally, we employ Bayesian optimization strategy to co-optimize the correlated cross-layer design parameters at algorithm layer, architecture layer, and circuit layer to minimize the hardware resource consumption while fulfilling multiple user constraints including reliability, accuracy, and performance of the deep learning processing at the same time.
Self-supervised Complex Network for Machine Sound Anomaly Detection
Dec 21, 2023In this paper, we propose an anomaly detection algorithm for machine sounds with a deep complex network trained by self-supervision. Using the fact that phase continuity information is crucial for detecting abnormalities in time-series signals, our proposed algorithm utilizes the complex spectrum as an input and performs complex number arithmetic throughout the entire process. Since the usefulness of phase information can vary depending on the type of machine sound, we also apply an attention mechanism to control the weights of the complex and magnitude spectrum bottleneck features depending on the machine type. We train our network to perform a self-supervised task that classifies the machine identifier (id) of normal input sounds among multiple classes. At test time, an input signal is detected as anomalous if the trained model is unable to correctly classify the id. In other words, we determine the presence of an anomality when the output cross-entropy score of the multiclass identification task is lower than a pre-defined threshold. Experiments with the MIMII dataset show that the proposed algorithm has a much higher area under the curve (AUC) score than conventional magnitude spectrum-based algorithms.
MR-STGN: Multi-Residual Spatio Temporal Graph Network Using Attention Fusion for Patient Action Assessment
Dec 21, 2023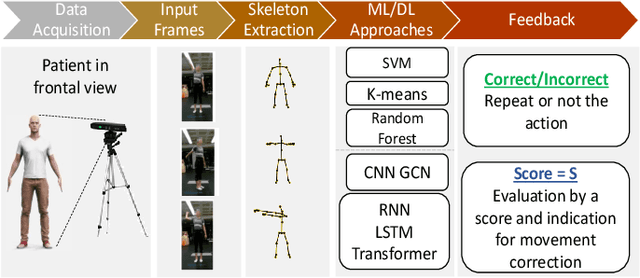
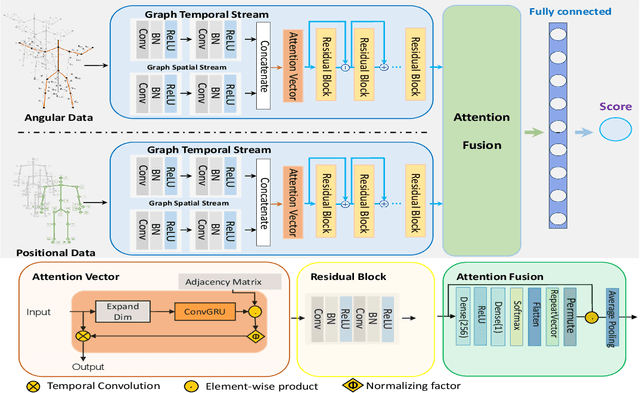
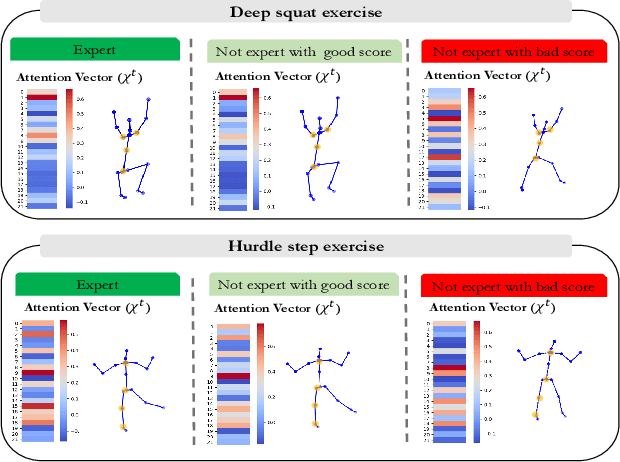
Accurate assessment of patient actions plays a crucial role in healthcare as it contributes significantly to disease progression monitoring and treatment effectiveness. However, traditional approaches to assess patient actions often rely on manual observation and scoring, which are subjective and time-consuming. In this paper, we propose an automated approach for patient action assessment using a Multi-Residual Spatio Temporal Graph Network (MR-STGN) that incorporates both angular and positional 3D skeletons. The MR-STGN is specifically designed to capture the spatio-temporal dynamics of patient actions. It achieves this by integrating information from multiple residual layers, with each layer extracting features at distinct levels of abstraction. Furthermore, we integrate an attention fusion mechanism into the network, which facilitates the adaptive weighting of various features. This empowers the model to concentrate on the most pertinent aspects of the patient's movements, offering precise instructions regarding specific body parts or movements that require attention. Ablation studies are conducted to analyze the impact of individual components within the proposed model. We evaluate our model on the UI-PRMD dataset demonstrating its performance in accurately predicting real-time patient action scores, surpassing state-of-the-art methods.
LLMs with User-defined Prompts as Generic Data Operators for Reliable Data Processing
Dec 26, 2023Data processing is one of the fundamental steps in machine learning pipelines to ensure data quality. Majority of the applications consider the user-defined function (UDF) design pattern for data processing in databases. Although the UDF design pattern introduces flexibility, reusability and scalability, the increasing demand on machine learning pipelines brings three new challenges to this design pattern -- not low-code, not dependency-free and not knowledge-aware. To address these challenges, we propose a new design pattern that large language models (LLMs) could work as a generic data operator (LLM-GDO) for reliable data cleansing, transformation and modeling with their human-compatible performance. In the LLM-GDO design pattern, user-defined prompts (UDPs) are used to represent the data processing logic rather than implementations with a specific programming language. LLMs can be centrally maintained so users don't have to manage the dependencies at the run-time. Fine-tuning LLMs with domain-specific data could enhance the performance on the domain-specific tasks which makes data processing knowledge-aware. We illustrate these advantages with examples in different data processing tasks. Furthermore, we summarize the challenges and opportunities introduced by LLMs to provide a complete view of this design pattern for more discussions.
Anomaly component analysis
Dec 26, 2023At the crossway of machine learning and data analysis, anomaly detection aims at identifying observations that exhibit abnormal behaviour. Be it measurement errors, disease development, severe weather, production quality default(s) (items) or failed equipment, financial frauds or crisis events, their on-time identification and isolation constitute an important task in almost any area of industry and science. While a substantial body of literature is devoted to detection of anomalies, little attention is payed to their explanation. This is the case mostly due to intrinsically non-supervised nature of the task and non-robustness of the exploratory methods like principal component analysis (PCA). We introduce a new statistical tool dedicated for exploratory analysis of abnormal observations using data depth as a score. Anomaly component analysis (shortly ACA) is a method that searches a low-dimensional data representation that best visualises and explains anomalies. This low-dimensional representation not only allows to distinguish groups of anomalies better than the methods of the state of the art, but as well provides a -- linear in variables and thus easily interpretable -- explanation for anomalies. In a comparative simulation and real-data study, ACA also proves advantageous for anomaly analysis with respect to methods present in the literature.
LaneSegNet: Map Learning with Lane Segment Perception for Autonomous Driving
Dec 26, 2023A map, as crucial information for downstream applications of an autonomous driving system, is usually represented in lanelines or centerlines. However, existing literature on map learning primarily focuses on either detecting geometry-based lanelines or perceiving topology relationships of centerlines. Both of these methods ignore the intrinsic relationship of lanelines and centerlines, that lanelines bind centerlines. While simply predicting both types of lane in one model is mutually excluded in learning objective, we advocate lane segment as a new representation that seamlessly incorporates both geometry and topology information. Thus, we introduce LaneSegNet, the first end-to-end mapping network generating lane segments to obtain a complete representation of the road structure. Our algorithm features two key modifications. One is a lane attention module to capture pivotal region details within the long-range feature space. Another is an identical initialization strategy for reference points, which enhances the learning of positional priors for lane attention. On the OpenLane-V2 dataset, LaneSegNet outperforms previous counterparts by a substantial gain across three tasks, \textit{i.e.}, map element detection (+4.8 mAP), centerline perception (+6.9 DET$_l$), and the newly defined one, lane segment perception (+5.6 mAP). Furthermore, it obtains a real-time inference speed of 14.7 FPS. Code is accessible at https://github.com/OpenDriveLab/LaneSegNet.