 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BioVL-QR: Egocentric Biochemical Video-and-Language Dataset Using Micro QR Codes
Apr 04, 2024
This paper introduces a biochemical vision-and-language dataset, which consists of 24 egocentric experiment videos, corresponding protocols, and video-and-language alignments. The key challenge in the wet-lab domain is detecting equipment, reagents, and containers is difficult because the lab environment is scattered by filling objects on the table and some objects are indistinguishable. Therefore, previous studies assume that objects are manually annotated and given for downstream tasks, but this is costly and time-consuming. To address this issue, this study focuses on Micro QR Codes to detect objects automatically. From our preliminary study, we found that detecting objects only using Micro QR Codes is still difficult because the researchers manipulate objects, causing blur and occlusion frequently. To address this, we also propose a novel object labeling method by combining a Micro QR Code detector and an off-the-shelf hand object detector. As one of the applications of our dataset, we conduct the task of generating protocols from experiment videos and find that our approach can generate accurate protocols.
Language Model Evolution: An Iterated Learning Perspective
Apr 04, 2024With the widespread adoption of Large Language Models (LLMs), the prevalence of iterative interactions among these models is anticipated to increase. Notably, recent advancements in multi-round self-improving methods allow LLMs to generate new examples for training subsequent models. At the same time, multi-agent LLM systems, involving automated interactions among agents, are also increasing in prominence. Thus, in both short and long terms, LLMs may actively engage in an evolutionary process. We draw parallels between the behavior of LLMs and the evolution of human culture, as the latter has been extensively studied by cognitive scientists for decades. Our approach involves leveraging Iterated Learning (IL), a Bayesian framework that elucidates how subtle biases are magnified during human cultural evolution, to explain some behaviors of LLMs. This paper outlines key characteristics of agents' behavior in the Bayesian-IL framework, including predictions that are supported by experimental verification with various LLMs. This theoretical framework could help to more effectively predict and guide the evolution of LLMs in desired directions.
Foundation Models for Structural Health Monitoring
Apr 03, 2024Structural Health Monitoring (SHM) is a critical task for ensuring the safety and reliability of civil infrastructures, typically realized on bridges and viaducts by means of vibration monitoring. In this paper, we propose for the first time the use of Transformer neural networks, with a Masked Auto-Encoder architecture, as Foundation Models for SHM. We demonstrate the ability of these models to learn generalizable representations from multiple large datasets through self-supervised pre-training, which, coupled with task-specific fine-tuning, allows them to outperform state-of-the-art traditional methods on diverse tasks, including Anomaly Detection (AD) and Traffic Load Estimation (TLE). We then extensively explore model size versus accuracy trade-offs and experiment with Knowledge Distillation (KD) to improve the performance of smaller Transformers, enabling their embedding directly into the SHM edge nodes. We showcase the effectiveness of our foundation models using data from three operational viaducts. For AD, we achieve a near-perfect 99.9% accuracy with a monitoring time span of just 15 windows. In contrast, a state-of-the-art method based on Principal Component Analysis (PCA) obtains its first good result (95.03% accuracy) only considering 120 windows. On two different TLE tasks, our models obtain state-of-the-art performance on multiple evaluation metrics (R$^2$ score, MAE% and MSE%). On the first benchmark, we achieve an R$^2$ score of 0.97 and 0.85 for light and heavy vehicle traffic, respectively, while the best previous approach stops at 0.91 and 0.84. On the second one, we achieve an R$^2$ score of 0.54 versus the 0.10 of the best existing method.
MM3DGS SLAM: Multi-modal 3D Gaussian Splatting for SLAM Using Vision, Depth, and Inertial Measurements
Apr 01, 2024Simultaneous localization and mapping is essential for position tracking and scene understanding. 3D Gaussian-based map representations enable photorealistic reconstruction and real-time rendering of scenes using multiple posed cameras. We show for the first time that using 3D Gaussians for map representation with unposed camera images and inertial measurements can enable accurate SLAM. Our method, MM3DGS, addresses the limitations of prior neural radiance field-based representations by enabling faster rendering, scale awareness, and improved trajectory tracking. Our framework enables keyframe-based mapping and tracking utilizing loss functions that incorporate relative pose transformations from pre-integrated inertial measurements, depth estimates, and measures of photometric rendering quality. We also release a multi-modal dataset, UT-MM, collected from a mobile robot equipped with a camera and an inertial measurement unit. Experimental evaluation on several scenes from the dataset shows that MM3DGS achieves 3x improvement in tracking and 5% improvement in photometric rendering quality compared to the current 3DGS SLAM state-of-the-art, while allowing real-time rendering of a high-resolution dense 3D map. Project Webpage: https://vita-group.github.io/MM3DGS-SLAM
TimeRewind: Rewinding Time with Image-and-Events Video Diffusion
Mar 20, 2024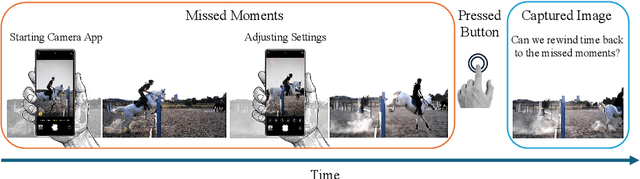

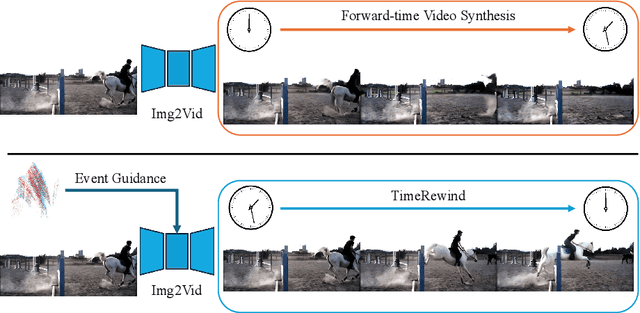
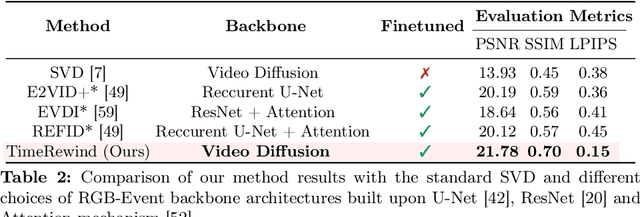
This paper addresses the novel challenge of ``rewinding'' time from a single captured image to recover the fleeting moments missed just before the shutter button is pressed. This problem poses a significant challenge in computer vision and computational photography, as it requires predicting plausible pre-capture motion from a single static frame, an inherently ill-posed task due to the high degree of freedom in potential pixel movements. We overcome this challenge by leveraging the emerging technology of neuromorphic event cameras, which capture motion information with high temporal resolution, and integrating this data with advanced image-to-video diffusion models. Our proposed framework introduces an event motion adaptor conditioned on event camera data, guiding the diffusion model to generate videos that are visually coherent and physically grounded in the captured events. Through extensive experimentation, we demonstrate the capability of our approach to synthesize high-quality videos that effectively ``rewind'' time, showcasing the potential of combining event camera technology with generative models. Our work opens new avenues for research at the intersection of computer vision, computational photography, and generative modeling, offering a forward-thinking solution to capturing missed moments and enhancing future consumer cameras and smartphones. Please see the project page at https://timerewind.github.io/ for video results and code release.
Optimal Pilot Design for OTFS in Linear Time-Varying Channels
Mar 28, 2024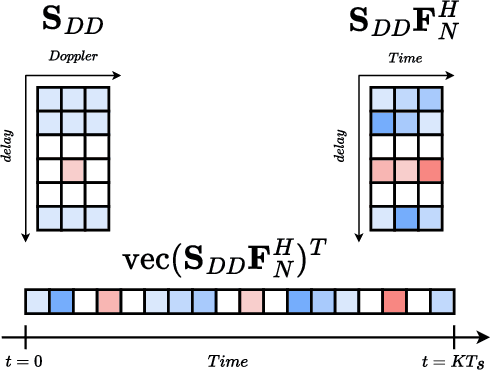
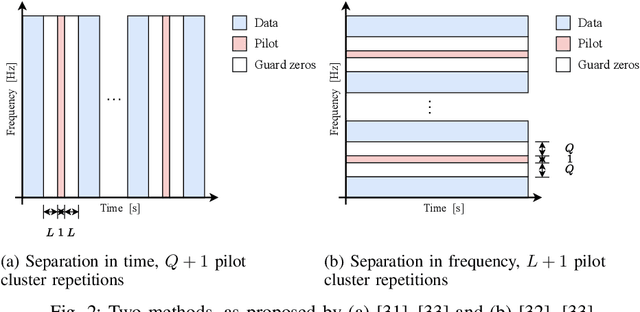
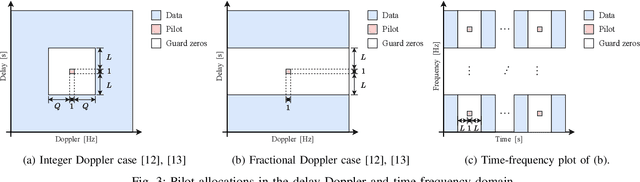
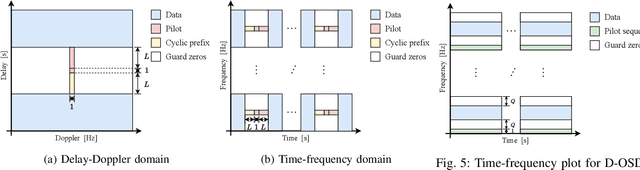
This paper investigates the positioning of the pilot symbols, as well as the power distribution between the pilot and the communication symbols in the OTFS modulation scheme. We analyze the pilot placements that minimize the mean squared error (MSE) in estimating the channel taps. In addition, we optimize the average channel capacity by adjusting the power balance. We show that this leads to a significant increase in average capacity. The results provide valuable guidance for designing the OTFS parameters to achieve maximum capacity. Numerical simulations are performed to validate the findings.
Optimizing traffic signs and lights visibility for the teleoperation of autonomous vehicles through ROI compression
Apr 03, 2024Autonomous vehicles are a promising solution to traffic congestion, air pollution, accidents, and wasted time and resources. However, remote driver intervention may be necessary for extreme situations to ensure safe roadside parking or complete remote takeover. In such cases, high-quality real-time video streaming is crucial for practical remote driving. In a preliminary study, we already presented a region of interest (ROI) HEVC data compression where the image was segmented into two categories of ROI and background, allocating more bandwidth to the ROI, yielding an improvement in the visibility of the classes that essential for driving while transmitting the background with lesser quality. However, migrating bandwidth to the large ROI portion of the image doesn't substantially improve the quality of traffic signs and lights. This work categorized the ROIs into either background, weak ROI, or strong ROI. The simulation-based approach uses a photo-realistic driving scenario database created with the Cognata self-driving car simulation platform. We use semantic segmentation to categorize the compression quality of a Coding Tree Unit (CTU) according to each pixel class. A background CTU can contain only sky, trees, vegetation, or building classes. Essentials for remote driving include significant classes such as roads, road marks, cars, and pedestrians. And most importantly, traffic signs and traffic lights. We apply thresholds to decide if the number of pixels in a CTU of a particular category is enough to declare it as belonging to the strong or weak ROI. Then, we allocate the bandwidth according to the CTU categories. Our results show that the perceptual quality of traffic signs, especially textual signs and traffic lights, improves significantly by up to 5.5 dB compared to the only background and foreground partition, while the weak ROI classes at least retain their original quality.
A Bimanual Teleoperation Framework for Light Duty Underwater Vehicle-Manipulator Systems
Apr 04, 2024In an effort to lower the barrier to entry in underwater manipulation, this paper presents an open-source, user-friendly framework for bimanual teleoperation of a light-duty underwater vehicle-manipulator system (UVMS). This framework allows for the control of the vehicle along with two manipulators and their end-effectors using two low-cost haptic devices. The UVMS kinematics are derived in order to create an independent resolved motion rate controller for each manipulator, which optimally controls the joint positions to achieve a desired end-effector pose. This desired pose is computed in real-time using a teleoperation controller developed to process the dual haptic device input from the user. A physics-based simulation environment is used to implement this framework for two example tasks as well as provide data for error analysis of user commands. The first task illustrates the functionality of the framework through motion control of the vehicle and manipulators using only the haptic devices. The second task is to grasp an object using both manipulators simultaneously, demonstrating precision and coordination using the framework. The framework code is available at https://github.com/stevens-armlab/uvms_bimanual_sim.
On Extending the Automatic Test Markup Language (ATML) for Machine Learning
Apr 04, 2024This paper addresses the urgent need for messaging standards in the operational test and evaluation (T&E) of machine learning (ML) applications, particularly in edge ML applications embedded in systems like robots, satellites, and unmanned vehicles. It examines the suitability of the IEEE Standard 1671 (IEEE Std 1671), known as the Automatic Test Markup Language (ATML), an XML-based standard originally developed for electronic systems, for ML application testing. The paper explores extending IEEE Std 1671 to encompass the unique challenges of ML applications, including the use of datasets and dependencies on software. Through modeling various tests such as adversarial robustness and drift detection, this paper offers a framework adaptable to specific applications, suggesting that minor modifications to ATML might suffice to address the novelties of ML. This paper differentiates ATML's focus on testing from other ML standards like Predictive Model Markup Language (PMML) or Open Neural Network Exchange (ONNX), which concentrate on ML model specification. We conclude that ATML is a promising tool for effective, near real-time operational T&E of ML applications, an essential aspect of AI lifecycle management, safety, and governance.
Robot Safety Monitoring using Programmable Light Curtains
Apr 04, 2024As factories continue to evolve into collaborative spaces with multiple robots working together with human supervisors in the loop, ensuring safety for all actors involved becomes critical. Currently, laser-based light curtain sensors are widely used in factories for safety monitoring. While these conventional safety sensors meet high accuracy standards, they are difficult to reconfigure and can only monitor a fixed user-defined region of space. Furthermore, they are typically expensive. Instead, we leverage a controllable depth sensor, programmable light curtains (PLC), to develop an inexpensive and flexible real-time safety monitoring system for collaborative robot workspaces. Our system projects virtual dynamic safety envelopes that tightly envelop the moving robot at all times and detect any objects that intrude the envelope. Furthermore, we develop an instrumentation algorithm that optimally places (multiple) PLCs in a workspace to maximize the visibility coverage of robots. Our work enables fence-less human-robot collaboration, while scaling to monitor multiple robots with few sensors. We analyze our system in a real manufacturing testbed with four robot arms and demonstrate its capabilities as a fast, accurate, and inexpensive safety monitoring solution.