 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reward Shaping for Improved Learning in Real-time Strategy Game Play
Nov 27, 2023
We investigate the effect of reward shaping in improving the performance of reinforcement learning in the context of the real-time strategy, capture-the-flag game. The game is characterized by sparse rewards that are associated with infrequently occurring events such as grabbing or capturing the flag, or tagging the opposing player. We show that appropriately designed reward shaping functions applied to different game events can significantly improve the player's performance and training times of the player's learning algorithm. We have validated our reward shaping functions within a simulated environment for playing a marine capture-the-flag game between two players. Our experimental results demonstrate that reward shaping can be used as an effective means to understand the importance of different sub-tasks during game-play towards winning the game, to encode a secondary objective functions such as energy efficiency into a player's game-playing behavior, and, to improve learning generalizable policies that can perform well against different skill levels of the opponent.
A mathematical perspective on Transformers
Dec 22, 2023Transformers play a central role in the inner workings of large language models. We develop a mathematical framework for analyzing Transformers based on their interpretation as interacting particle systems, which reveals that clusters emerge in long time. Our study explores the underlying theory and offers new perspectives for mathematicians as well as computer scientists.
Splatter Image: Ultra-Fast Single-View 3D Reconstruction
Dec 20, 2023We introduce the Splatter Image, an ultra-fast approach for monocular 3D object reconstruction which operates at 38 FPS. Splatter Image is based on Gaussian Splatting, which has recently brought real-time rendering, fast training, and excellent scaling to multi-view reconstruction. For the first time, we apply Gaussian Splatting in a monocular reconstruction setting. Our approach is learning-based, and, at test time, reconstruction only requires the feed-forward evaluation of a neural network. The main innovation of Splatter Image is the surprisingly straightforward design: it uses a 2D image-to-image network to map the input image to one 3D Gaussian per pixel. The resulting Gaussians thus have the form of an image, the Splatter Image. We further extend the method to incorporate more than one image as input, which we do by adding cross-view attention. Owning to the speed of the renderer (588 FPS), we can use a single GPU for training while generating entire images at each iteration in order to optimize perceptual metrics like LPIPS. On standard benchmarks, we demonstrate not only fast reconstruction but also better results than recent and much more expensive baselines in terms of PSNR, LPIPS, and other metrics.
K-Space Beamforming for an Array of Quantum Sensors
Dec 27, 2023In this paper we present a novel beamforming technique that can be used with an array of quantum sensors. The transmit waveform is a short-duration frequency comb constructed using a finite number of sinusoidal tones separated by a fixed offset. Each element in the array is tuned to one of the tones. When the radiated signal is received by the aperture, each array element accumulates phase at a different rate since it is matched to only one frequency component of the comb waveform. The result is that over the duration of the received pulse, progressively higher spatial frequencies are generated across the aperture. By summing the outputs of all the array elements, a strong peak is created in k-space at the precise time instant when the phases of all the array elements align. The k-space coordinates of the output can then be transformed to angles as discussed in the paper. This paper also describes how to set waveform parameters and the separation between array elements. A desirable advantage of the proposed approach is that the received signal is amplified by the coherent integration gain of the entire spatial aperture.
Evolutionary Swarm Robotics: Dynamic Subgoal-Based Path Formation and Task Allocation for Exploration and Navigation in Unknown Environments
Dec 27, 2023This research paper addresses the challenges of exploration and navigation in unknown environments from an evolutionary swarm robotics perspective. Path formation plays a crucial role in enabling cooperative swarm robots to accomplish these tasks. The paper presents a method called the sub-goal-based path formation, which establishes a path between two different locations by exploiting visually connected sub-goals. Simulation experiments conducted in the Argos simulator demonstrate the successful formation of paths in the majority of trials. Furthermore, the paper tackles the problem of inter-collision (traffic) among a large number of robots engaged in path formation, which negatively impacts the performance of the sub-goal-based method. To mitigate this issue, a task allocation strategy is proposed, leveraging local communication protocols and light signal-based communication. The strategy evaluates the distance between points and determines the required number of robots for the path formation task, reducing unwanted exploration and traffic congestion. The performance of the sub-goal-based path formation and task allocation strategy is evaluated by comparing path length, time, and resource reduction against the A* algorithm. The simulation experiments demonstrate promising results, showcasing the scalability, robustness, and fault tolerance characteristics of the proposed approach.
Exploiting the capacity of deep networks only at training stage for nonlinear black-box system identification
Dec 27, 2023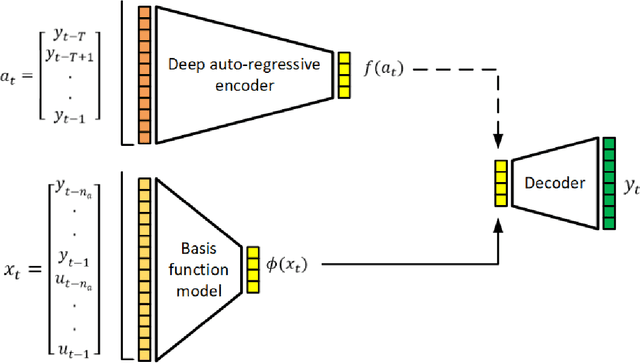
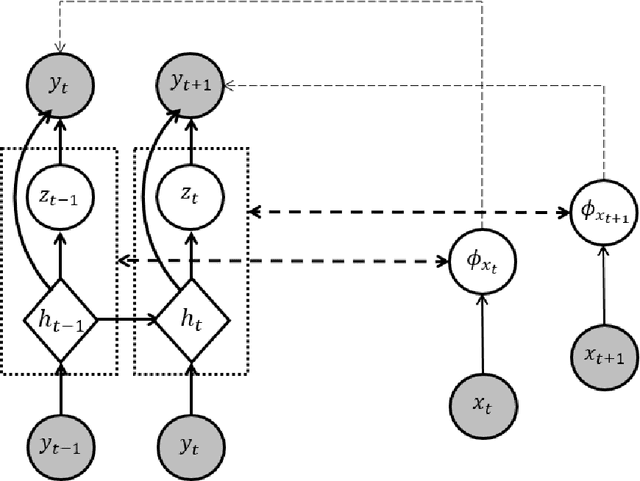
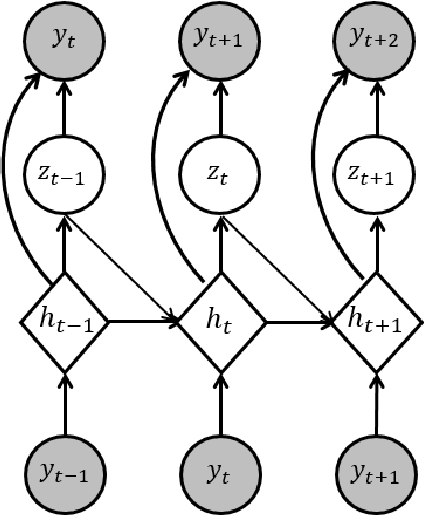
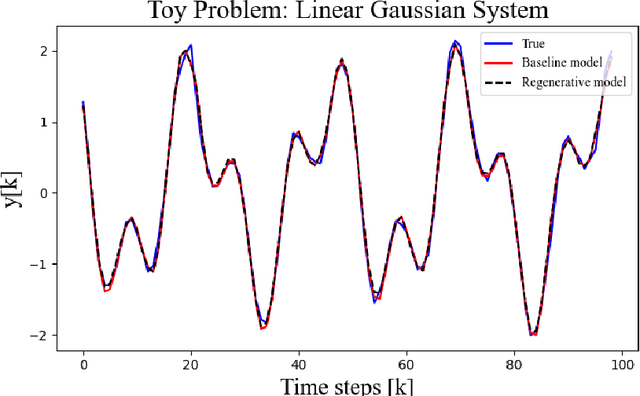
To benefit from the modeling capacity of deep models in system identification, without worrying about inference time, this study presents a novel training strategy that uses deep models only at the training stage. For this purpose two separate models with different structures and goals are employed. The first one is a deep generative model aiming at modeling the distribution of system output(s), called the teacher model, and the second one is a shallow basis function model, named the student model, fed by system input(s) to predict the system output(s). That means these isolated paths must reach the same ultimate target. As deep models show a great performance in modeling of highly nonlinear systems, aligning the representation space learned by these two models make the student model to inherit the approximation power of the teacher model. The proposed objective function consists of the objective of each student and teacher model adding up with a distance penalty between the learned latent representations. The simulation results on three nonlinear benchmarks show a comparative performance with examined deep architectures applied on the same benchmarks. Algorithmic transparency and structure efficiency are also achieved as byproducts.
Browsing behavior exposes identities on the Web
Dec 24, 2023How easy is it to uniquely identify a person based on their web browsing behavior? Here we show that when people navigate the Web, their online traces produce fingerprints that identify them. By merely knowing their most visited web domains, four data points are enough to identify 95% of the individuals. These digital fingerprints are stable and render high re-identifiability. We demonstrate that we can re-identify 90% of the individuals in separate time slices of data. Such a privacy threat persists even with limited information about individuals' browsing behavior, reinforcing existing concerns around online privacy.
Enhanced Breast Cancer Tumor Classification using MobileNetV2: A Detailed Exploration on Image Intensity, Error Mitigation, and Streamlit-driven Real-time Deployment
Dec 05, 2023This research introduces a sophisticated transfer learning model based on Google's MobileNetV2 for breast cancer tumor classification into normal, benign, and malignant categories, utilizing a dataset of 1576 ultrasound images (265 normal, 891 benign, 420 malignant). The model achieves an accuracy of 0.82, precision of 0.83, recall of 0.81, ROC-AUC of 0.94, PR-AUC of 0.88, and MCC of 0.74. It examines image intensity distributions and misclassification errors, offering improvements for future applications. Addressing dataset imbalances, the study ensures a generalizable model. This work, using a dataset from Baheya Hospital, Cairo, Egypt, compiled by Walid Al-Dhabyani et al., emphasizes MobileNetV2's potential in medical imaging, aiming to improve diagnostic precision in oncology. Additionally, the paper explores Streamlit-based deployment for real-time tumor classification, demonstrating MobileNetV2's applicability in medical imaging and setting a benchmark for future research in oncology diagnostics.
pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction
Dec 21, 2023We introduce pixelSplat, a feed-forward model that learns to reconstruct 3D radiance fields parameterized by 3D Gaussian primitives from pairs of images. Our model features real-time and memory-efficient rendering for scalable training as well as fast 3D reconstruction at inference time. To overcome local minima inherent to sparse and locally supported representations, we predict a dense probability distribution over 3D and sample Gaussian means from that probability distribution. We make this sampling operation differentiable via a reparameterization trick, allowing us to back-propagate gradients through the Gaussian splatting representation. We benchmark our method on wide-baseline novel view synthesis on the real-world RealEstate10k and ACID datasets, where we outperform state-of-the-art light field transformers and accelerate rendering by 2.5 orders of magnitude while reconstructing an interpretable and editable 3D radiance field.
SSR-Encoder: Encoding Selective Subject Representation for Subject-Driven Generation
Dec 26, 2023Recent advancements in subject-driven image generation have led to zero-shot generation, yet precise selection and focus on crucial subject representations remain challenging. Addressing this, we introduce the SSR-Encoder, a novel architecture designed for selectively capturing any subject from single or multiple reference images. It responds to various query modalities including text and masks, without necessitating test-time fine-tuning. The SSR-Encoder combines a Token-to-Patch Aligner that aligns query inputs with image patches and a Detail-Preserving Subject Encoder for extracting and preserving fine features of the subjects, thereby generating subject embeddings. These embeddings, used in conjunction with original text embeddings, condition the generation process. Characterized by its model generalizability and efficiency, the SSR-Encoder adapts to a range of custom models and control modules. Enhanced by the Embedding Consistency Regularization Loss for improved training, our extensive experiments demonstrate its effectiveness in versatile and high-quality image generation, indicating its broad applicability. Project page: https://ssr-encoder.github.io