 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Featurizing Koopman Mode Decomposition
Dec 20, 2023
This article introduces an advanced Koopman mode decomposition (KMD) technique -- coined Featurized Koopman Mode Decomposition (FKMD) -- that uses time embedding and Mahalanobis scaling to enhance analysis and prediction of high dimensional dynamical systems. The time embedding expands the observation space to better capture underlying manifold structure, while the Mahalanobis scaling, applied to kernel or random Fourier features, adjusts observations based on the system's dynamics. This aids in featurizing KMD in cases where good features are not a priori known. We show that our method improves KMD predictions for a high dimensional Lorenz attractor and for a cell signaling problem from cancer research.
Hotspot Prediction of Severe Traffic Accidents in the Federal District of Brazil
Dec 28, 2023Traffic accidents are one of the biggest challenges in a society where commuting is so important. What triggers an accident can be dependent on several subjective parameters and varies within each region, city, or country. In the same way, it is important to understand those parameters in order to provide a knowledge basis to support decisions regarding future cases prevention. The literature presents several works where machine learning algorithms are used for prediction of accidents or severity of accidents, in which city-level datasets were used as evaluation studies. This work attempts to add to the diversity of research, by focusing mainly on concentration of accidents and how machine learning can be used to predict hotspots. This approach demonstrated to be a useful technique for authorities to understand nuances of accident concentration behavior. For the first time, data from the Federal District of Brazil collected from forensic traffic accident analysts were used and combined with data from local weather conditions to predict hotspots of collisions. Out of the five algorithms we considered, two had good performance: Multi-layer Perceptron and Random Forest, with the latter being the best one at 98% accuracy. As a result, we identify that weather parameters are not as important as the accident location, demonstrating that local intervention is important to reduce the number of accidents.
* Published at The Twelfth International Conference on Smart Cities, Systems, Devices and Technologies SMART 2023 https://www.thinkmind.org/index.php?view=article&articleid=smart_2023_1_60_40032
Chaurah: A Smart Raspberry Pi based Parking System
Dec 28, 2023The widespread usage of cars and other large, heavy vehicles necessitates the development of an effective parking infrastructure. Additionally, algorithms for detection and recognition of number plates are often used to identify automobiles all around the world where standardized plate sizes and fonts are enforced, making recognition an effortless task. As a result, both kinds of data can be combined to develop an intelligent parking system focuses on the technology of Automatic Number Plate Recognition (ANPR). Retrieving characters from an inputted number plate image is the sole purpose of ANPR which is a costly procedure. In this article, we propose Chaurah, a minimal cost ANPR system that relies on a Raspberry Pi 3 that was specifically created for parking facilities. The system employs a dual-stage methodology, with the first stage being an ANPR system which makes use of two convolutional neural networks (CNNs). The primary locates and recognises license plates from a vehicle image, while the secondary performs Optical Character Recognition (OCR) to identify individualized numbers from the number plate. An application built with Flutter and Firebase for database administration and license plate record comparison makes up the second component of the overall solution. The application also acts as an user-interface for the billing mechanism based on parking time duration resulting in an all-encompassing software deployment of the study.
GUITAR: Gradient Pruning toward Fast Neural Ranking
Dec 28, 2023With the continuous popularity of deep learning and representation learning, fast vector search becomes a vital task in various ranking/retrieval based applications, say recommendation, ads ranking and question answering. Neural network based ranking is widely adopted due to its powerful capacity in modeling complex relationships, such as between users and items, questions and answers. However, it is usually exploited in offline or re-ranking manners for it is time-consuming in computations. Online neural network ranking--so called fast neural ranking--is considered challenging because neural network measures are usually non-convex and asymmetric. Traditional Approximate Nearest Neighbor (ANN) search which usually focuses on metric ranking measures, is not applicable to these advanced measures. In this paper, we introduce a novel graph searching framework to accelerate the searching in the fast neural ranking problem. The proposed graph searching algorithm is bi-level: we first construct a probable candidate set; then we only evaluate the neural network measure over the probable candidate set instead of evaluating the neural network over all neighbors. Specifically, we propose a gradient-based algorithm that approximates the rank of the neural network matching score to construct the probable candidate set; and we present an angle-based heuristic procedure to adaptively identify the proper size of the probable candidate set. Empirical results on public data confirm the effectiveness of our proposed algorithms.
TimeSQL: Improving Multivariate Time Series Forecasting with Multi-Scale Patching and Smooth Quadratic Loss
Nov 19, 2023Time series is a special type of sequence data, a sequence of real-valued random variables collected at even intervals of time. The real-world multivariate time series comes with noises and contains complicated local and global temporal dynamics, making it difficult to forecast the future time series given the historical observations. This work proposes a simple and effective framework, coined as TimeSQL, which leverages multi-scale patching and smooth quadratic loss (SQL) to tackle the above challenges. The multi-scale patching transforms the time series into two-dimensional patches with different length scales, facilitating the perception of both locality and long-term correlations in time series. SQL is derived from the rational quadratic kernel and can dynamically adjust the gradients to avoid overfitting to the noises and outliers. Theoretical analysis demonstrates that, under mild conditions, the effect of the noises on the model with SQL is always smaller than that with MSE. Based on the two modules, TimeSQL achieves new state-of-the-art performance on the eight real-world benchmark datasets. Further ablation studies indicate that the key modules in TimeSQL could also enhance the results of other models for multivariate time series forecasting, standing as plug-and-play techniques.
2D-Guided 3D Gaussian Segmentation
Dec 26, 2023Recently, 3D Gaussian, as an explicit 3D representation method, has demonstrated strong competitiveness over NeRF (Neural Radiance Fields) in terms of expressing complex scenes and training duration. These advantages signal a wide range of applications for 3D Gaussians in 3D understanding and editing. Meanwhile, the segmentation of 3D Gaussians is still in its infancy. The existing segmentation methods are not only cumbersome but also incapable of segmenting multiple objects simultaneously in a short amount of time. In response, this paper introduces a 3D Gaussian segmentation method implemented with 2D segmentation as supervision. This approach uses input 2D segmentation maps to guide the learning of the added 3D Gaussian semantic information, while nearest neighbor clustering and statistical filtering refine the segmentation results. Experiments show that our concise method can achieve comparable performances on mIOU and mAcc for multi-object segmentation as previous single-object segmentation methods.
SSFlowNet: Semi-supervised Scene Flow Estimation On Point Clouds With Pseudo Label
Dec 23, 2023In the domain of supervised scene flow estimation, the process of manual labeling is both time-intensive and financially demanding. This paper introduces SSFlowNet, a semi-supervised approach for scene flow estimation, that utilizes a blend of labeled and unlabeled data, optimizing the balance between the cost of labeling and the precision of model training. SSFlowNet stands out through its innovative use of pseudo-labels, mainly reducing the dependency on extensively labeled datasets while maintaining high model accuracy. The core of our model is its emphasis on the intricate geometric structures of point clouds, both locally and globally, coupled with a novel spatial memory feature. This feature is adept at learning the geometric relationships between points over sequential time frames. By identifying similarities between labeled and unlabeled points, SSFlowNet dynamically constructs a correlation matrix to evaluate scene flow dependencies at individual point level. Furthermore, the integration of a flow consistency module within SSFlowNet enhances its capability to consistently estimate flow, an essential aspect for analyzing dynamic scenes. Empirical results demonstrate that SSFlowNet surpasses existing methods in pseudo-label generation and shows adaptability across varying data volumes. Moreover, our semi-supervised training technique yields promising outcomes even with different smaller ratio labeled data, marking a substantial advancement in the field of scene flow estimation.
Hardware-Aware DNN Compression via Diverse Pruning and Mixed-Precision Quantization
Dec 23, 2023Deep Neural Networks (DNNs) have shown significant advantages in a wide variety of domains. However, DNNs are becoming computationally intensive and energy hungry at an exponential pace, while at the same time, there is a vast demand for running sophisticated DNN-based services on resource constrained embedded devices. In this paper, we target energy-efficient inference on embedded DNN accelerators. To that end, we propose an automated framework to compress DNNs in a hardware-aware manner by jointly employing pruning and quantization. We explore, for the first time, per-layer fine- and coarse-grained pruning, in the same DNN architecture, in addition to low bit-width mixed-precision quantization for weights and activations. Reinforcement Learning (RL) is used to explore the associated design space and identify the pruning-quantization configuration so that the energy consumption is minimized whilst the prediction accuracy loss is retained at acceptable levels. Using our novel composite RL agent we are able to extract energy-efficient solutions without requiring retraining and/or fine tuning. Our extensive experimental evaluation over widely used DNNs and the CIFAR-10/100 and ImageNet datasets demonstrates that our framework achieves $39\%$ average energy reduction for $1.7\%$ average accuracy loss and outperforms significantly the state-of-the-art approaches.
Data Classification With Multiprocessing
Dec 23, 2023Classification is one of the most important tasks in Machine Learning (ML) and with recent advancements in artificial intelligence (AI) it is important to find efficient ways to implement it. Generally, the choice of classification algorithm depends on the data it is dealing with, and accuracy of the algorithm depends on the hyperparameters it is tuned with. One way is to check the accuracy of the algorithms by executing it with different hyperparameters serially and then selecting the parameters that give the highest accuracy to predict the final output. This paper proposes another way where the algorithm is parallelly trained with different hyperparameters to reduce the execution time. In the end, results from all the trained variations of the algorithms are ensembled to exploit the parallelism and improve the accuracy of prediction. Python multiprocessing is used to test this hypothesis with different classification algorithms such as K-Nearest Neighbors (KNN), Support Vector Machines (SVM), random forest and decision tree and reviews factors affecting parallelism. Ensembled output considers the predictions from all processes and final class is the one predicted by maximum number of processes. Doing this increases the reliability of predictions. We conclude that ensembling improves accuracy and multiprocessing reduces execution time for selected algorithms.
Linear-time online visibility graph transformation algorithm: for both natural and horizontal visibility criteria
Nov 21, 2023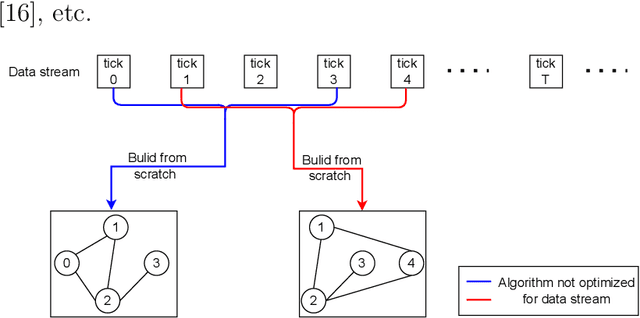
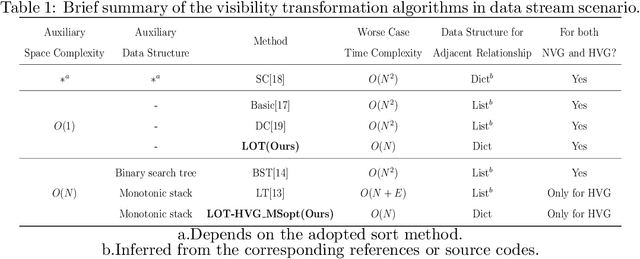
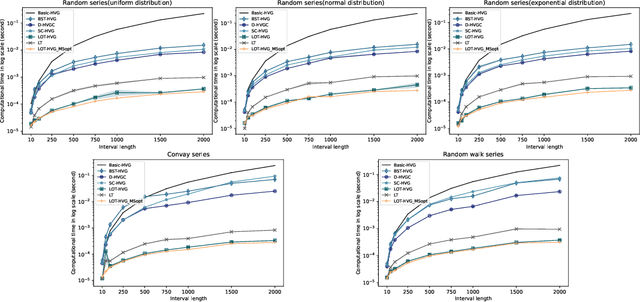
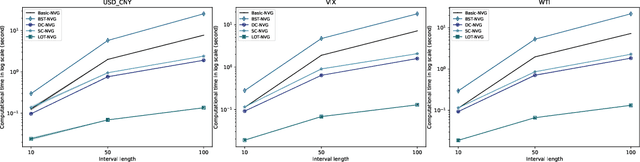
Visibility graph (VG) transformation is a technique used to convert a time series into a graph based on specific visibility criteria. It has attracted increasing interest in the fields of time series analysis, forecasting, and classification. Optimizing the VG transformation algorithm to accelerate the process is a critical aspect of VG-related research, as it enhances the applicability of VG transformation in latency-sensitive areas and conserves computational resources. In the real world, many time series are presented in the form of data streams. Despite the proposal of the concept of VG's online functionality, previous studies have not thoroughly explored the acceleration of VG transformation by leveraging the characteristics of data streams. In this paper, we propose that an efficient online VG algorithm should adhere to two criteria and develop a linear-time method, termed the LOT framework, for both natural and horizontal visibility graph transformations in data stream scenarios. Experiments are conducted on two datasets, comparing our approach with five existing methods as baselines. The results demonstrate the validity and promising computational efficiency of our framework.