 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AccidentGPT: Accident Analysis and Prevention from V2X Environmental Perception with Multi-modal Large Model
Dec 29, 2023
Traffic accidents, being a significant contributor to both human casualties and property damage, have long been a focal point of research for many scholars in the field of traffic safety. However, previous studies, whether focusing on static environmental assessments or dynamic driving analyses, as well as pre-accident predictions or post-accident rule analyses, have typically been conducted in isolation. There has been a lack of an effective framework for developing a comprehensive understanding and application of traffic safety. To address this gap, this paper introduces AccidentGPT, a comprehensive accident analysis and prevention multi-modal large model. AccidentGPT establishes a multi-modal information interaction framework grounded in multi-sensor perception, thereby enabling a holistic approach to accident analysis and prevention in the field of traffic safety. Specifically, our capabilities can be categorized as follows: for autonomous driving vehicles, we provide comprehensive environmental perception and understanding to control the vehicle and avoid collisions. For human-driven vehicles, we offer proactive long-range safety warnings and blind-spot alerts while also providing safety driving recommendations and behavioral norms through human-machine dialogue and interaction. Additionally, for traffic police and management agencies, our framework supports intelligent and real-time analysis of traffic safety, encompassing pedestrian, vehicles, roads, and the environment through collaborative perception from multiple vehicles and road testing devices. The system is also capable of providing a thorough analysis of accident causes and liability after vehicle collisions. Our framework stands as the first large model to integrate comprehensive scene understanding into traffic safety studies. Project page: https://accidentgpt.github.io
SRMAC -- Smoothed Recursive Moving Average Crossover for Real-Time Systolic Peak Detection in Photoplethysmography
Dec 15, 2023Purpose. Photoplethysmography (PPG) is a non-invasive technique that measures changes in blood flow volume through optical means. Previous research has established the feasibility of PPG peak detection based on the crossover of moving averages. This paper proposes the Smoothed Recuarsive Moving Average Crossover, which eliminates the need for post-processing and nonlinear pre-processing of previous crossover-based peak detectors. The proposed model is advantageous regarding memory and computational complexity, making it attractive for implementations on embedded devices. Methods. Along with this paper, we make available a novel dataset comprising 66 minutes of PPG recordings. The optimization and assessment of the proposed peak detection model use this dataset. Its optimization is accomplished with the simple random search heuristic, while the leave-subject-out cross-validation method provides the means to assess its performance. The source code for all experiments reported in this research is also available in an online repository. Results. The experimental study examines the performance of the proposed model considering different arrangements of the PPG data. The experiments show that the proposed model performs better than the previous crossover-based approach from the literature regarding the precision and recall metrics. More specifically, our model has an average precision of 0.9937 and an average recall of 0.9968. Conclusion. The contribution of this research to the scientific community and literature is twofold. The dataset we collected is open for any researcher, and we improve upon the leading edge on crossover-based PPG peak detection. This improvement comes in terms of performance metrics and computational cost.
Sliding Mode Control for 3-D Uncalibrated and Constrained Vision-based Shape Servoing within Input Saturation
Dec 26, 2023This paper designs a servo control system based on sliding mode control for the shape control of elastic objects. In order to solve the effect of non-smooth and asymmetric control saturation, a Gaussian-based continuous differentiable asymmetric saturation function is used for this goal. The proposed detection approach runs in a highly real-time manner. Meanwhile, this paper uses sliding mode control to prove that the estimation stability of the deformation Jacobian matrix and the system stability of the controller are combined, which verifies the control stability of the closed-loop system including estimation. Besides, an integral sliding mode function is designed to avoid the need for second-order derivatives of variables, which enhances the robustness of the system in actual situations. Finally, the Lyapunov theory is used to prove the consistent final boundedness of all variables of the system.
Achieving Fairness in DareFightingICE Agents Evaluation Through a Delay Mechanism
Dec 26, 2023This paper proposes a delay mechanism to mitigate the impact of latency differences in the gRPC framework--a high-performance, open-source universal remote procedure call (RPC) framework--between different programming languages on the performance of agents in DareFightingICE, a fighting game research platform. The study finds that gRPC latency differences between Java and Python can significantly impact real-time decision-making. Without a delay mechanism, Java-based agents outperform Python-based ones due to lower gRPC latency on the Java platform. However, with the proposed delay mechanism, both Java-based and Python-based agents exhibit similar performance, leading to a fair comparison between agents developed using different programming languages. Thus, this work underscores the crucial importance of considering gRPC latency when developing and evaluating agents in DareFightingICE, and the insights gained could potentially extend to other gRPC-based applications.
Cascade Speculative Drafting for Even Faster LLM Inference
Dec 21, 2023Speculative decoding enhances the efficiency of large language models (LLMs) by leveraging a draft model to draft for a larger target model to review. However, drafting in speculative decoding involves slow autoregressive generation and generating tokens of different importance with the same time allocation. These two inefficiencies lead to its suboptimal performance. To address this issue, we introduce Cascade Speculative Drafting (CS. Drafting), a novel approach that employs two types of cascades. The Vertical Cascade eliminates autoregressive generation from neural models. The Horizontal Cascade constitutes efficient time allocation in drafting with its optimality supported by our theoretical analysis. Combining both cascades, our CS. Drafting algorithm has achieved up to 72 percent additional speedup over speculative decoding in our experiments while keeping the same output distribution.
S2M: Converting Single-Turn to Multi-Turn Datasets for Conversational Question Answering
Dec 27, 2023Supplying data augmentation to conversational question answering (CQA) can effectively improve model performance. However, there is less improvement from single-turn datasets in CQA due to the distribution gap between single-turn and multi-turn datasets. On the other hand, while numerous single-turn datasets are available, we have not utilized them effectively. To solve this problem, we propose a novel method to convert single-turn datasets to multi-turn datasets. The proposed method consists of three parts, namely, a QA pair Generator, a QA pair Reassembler, and a question Rewriter. Given a sample consisting of context and single-turn QA pairs, the Generator obtains candidate QA pairs and a knowledge graph based on the context. The Reassembler utilizes the knowledge graph to get sequential QA pairs, and the Rewriter rewrites questions from a conversational perspective to obtain a multi-turn dataset S2M. Our experiments show that our method can synthesize effective training resources for CQA. Notably, S2M ranks 1st place on the QuAC leaderboard at the time of submission (Aug 24th, 2022).
Advancing VAD Systems Based on Multi-Task Learning with Improved Model Structures
Dec 19, 2023In a speech recognition system, voice activity detection (VAD) is a crucial frontend module. Addressing the issues of poor noise robustness in traditional binary VAD systems based on DFSMN, the paper further proposes semantic VAD based on multi-task learning with improved models for real-time and offline systems, to meet specific application requirements. Evaluations on internal datasets show that, compared to the real-time VAD system based on DFSMN, the real-time semantic VAD system based on RWKV achieves relative decreases in CER of 7.0\%, DCF of 26.1\% and relative improvement in NRR of 19.2\%. Similarly, when compared to the offline VAD system based on DFSMN, the offline VAD system based on SAN-M demonstrates relative decreases in CER of 4.4\%, DCF of 18.6\% and relative improvement in NRR of 3.5\%.
Finding Foundation Models for Time Series Classification with a PreText Task
Nov 24, 2023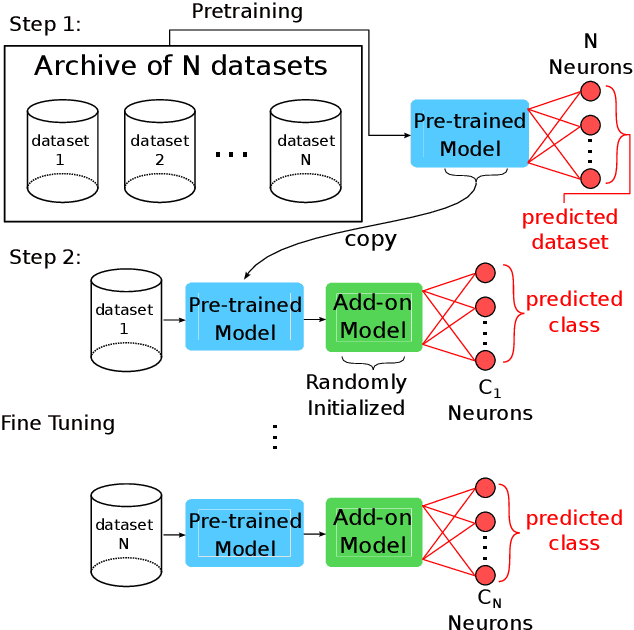
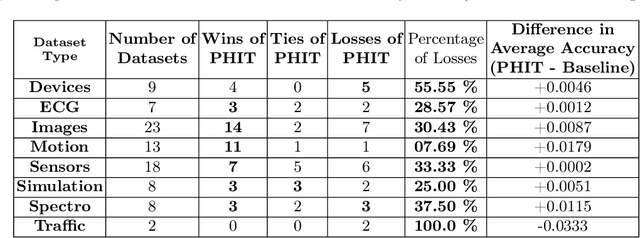
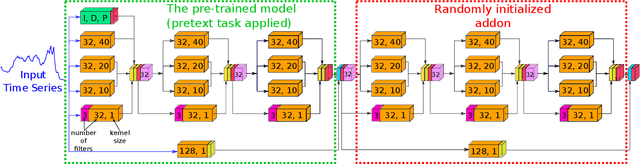
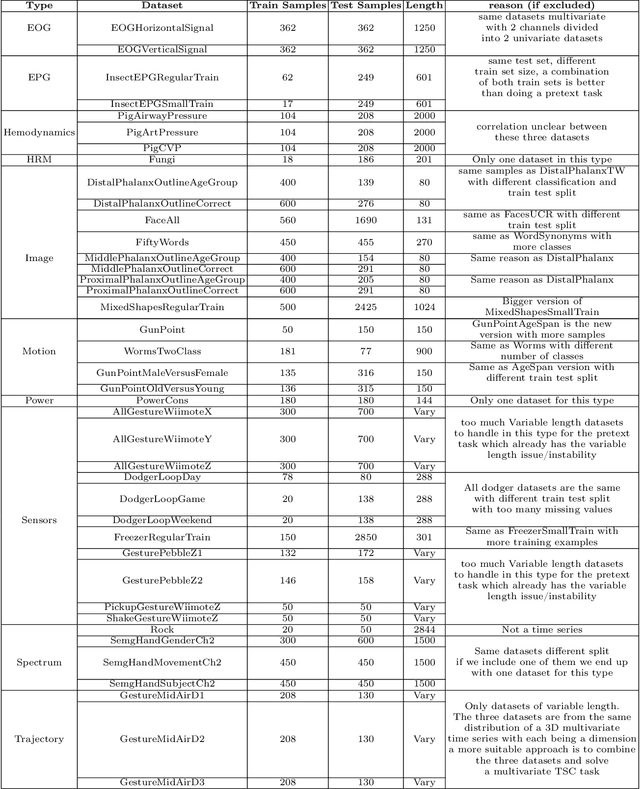
Over the past decade, Time Series Classification (TSC) has gained an increasing attention. While various methods were explored, deep learning - particularly through Convolutional Neural Networks (CNNs)-stands out as an effective approach. However, due to the limited availability of training data, defining a foundation model for TSC that overcomes the overfitting problem is still a challenging task. The UCR archive, encompassing a wide spectrum of datasets ranging from motion recognition to ECG-based heart disease detection, serves as a prime example for exploring this issue in diverse TSC scenarios. In this paper, we address the overfitting challenge by introducing pre-trained domain foundation models. A key aspect of our methodology is a novel pretext task that spans multiple datasets. This task is designed to identify the originating dataset of each time series sample, with the goal of creating flexible convolution filters that can be applied across different datasets. The research process consists of two phases: a pre-training phase where the model acquires general features through the pretext task, and a subsequent fine-tuning phase for specific dataset classifications. Our extensive experiments on the UCR archive demonstrate that this pre-training strategy significantly outperforms the conventional training approach without pre-training. This strategy effectively reduces overfitting in small datasets and provides an efficient route for adapting these models to new datasets, thus advancing the capabilities of deep learning in TSC.
TimeSQL: Improving Multivariate Time Series Forecasting with Multi-Scale Patching and Smooth Quadratic Loss
Nov 19, 2023Time series is a special type of sequence data, a sequence of real-valued random variables collected at even intervals of time. The real-world multivariate time series comes with noises and contains complicated local and global temporal dynamics, making it difficult to forecast the future time series given the historical observations. This work proposes a simple and effective framework, coined as TimeSQL, which leverages multi-scale patching and smooth quadratic loss (SQL) to tackle the above challenges. The multi-scale patching transforms the time series into two-dimensional patches with different length scales, facilitating the perception of both locality and long-term correlations in time series. SQL is derived from the rational quadratic kernel and can dynamically adjust the gradients to avoid overfitting to the noises and outliers. Theoretical analysis demonstrates that, under mild conditions, the effect of the noises on the model with SQL is always smaller than that with MSE. Based on the two modules, TimeSQL achieves new state-of-the-art performance on the eight real-world benchmark datasets. Further ablation studies indicate that the key modules in TimeSQL could also enhance the results of other models for multivariate time series forecasting, standing as plug-and-play techniques.
Neural Born Series Operator for Biomedical Ultrasound Computed Tomography
Dec 25, 2023Ultrasound Computed Tomography (USCT) provides a radiation-free option for high-resolution clinical imaging. Despite its potential, the computationally intensive Full Waveform Inversion (FWI) required for tissue property reconstruction limits its clinical utility. This paper introduces the Neural Born Series Operator (NBSO), a novel technique designed to speed up wave simulations, thereby facilitating a more efficient USCT image reconstruction process through an NBSO-based FWI pipeline. Thoroughly validated on comprehensive brain and breast datasets, simulated under experimental USCT conditions, the NBSO proves to be accurate and efficient in both forward simulation and image reconstruction. This advancement demonstrates the potential of neural operators in facilitating near real-time USCT reconstruction, making the clinical application of USCT increasingly viable and promising.