 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ElasticTrainer: Speeding Up On-Device Training with Runtime Elastic Tensor Selection
Dec 21, 2023
On-device training is essential for neural networks (NNs) to continuously adapt to new online data, but can be time-consuming due to the device's limited computing power. To speed up on-device training, existing schemes select trainable NN portion offline or conduct unrecoverable selection at runtime, but the evolution of trainable NN portion is constrained and cannot adapt to the current need for training. Instead, runtime adaptation of on-device training should be fully elastic, i.e., every NN substructure can be freely removed from or added to the trainable NN portion at any time in training. In this paper, we present ElasticTrainer, a new technique that enforces such elasticity to achieve the required training speedup with the minimum NN accuracy loss. Experiment results show that ElasticTrainer achieves up to 3.5x more training speedup in wall-clock time and reduces energy consumption by 2x-3x more compared to the existing schemes, without noticeable accuracy loss.
Periodic Vibration Gaussian: Dynamic Urban Scene Reconstruction and Real-time Rendering
Nov 30, 2023Modeling dynamic, large-scale urban scenes is challenging due to their highly intricate geometric structures and unconstrained dynamics in both space and time. Prior methods often employ high-level architectural priors, separating static and dynamic elements, resulting in suboptimal capture of their synergistic interactions. To address this challenge, we present a unified representation model, called Periodic Vibration Gaussian (PVG). PVG builds upon the efficient 3D Gaussian splatting technique, originally designed for static scene representation, by introducing periodic vibration-based temporal dynamics. This innovation enables PVG to elegantly and uniformly represent the characteristics of various objects and elements in dynamic urban scenes. To enhance temporally coherent representation learning with sparse training data, we introduce a novel flow-based temporal smoothing mechanism and a position-aware adaptive control strategy. Extensive experiments on Waymo Open Dataset and KITTI benchmarks demonstrate that PVG surpasses state-of-the-art alternatives in both reconstruction and novel view synthesis for both dynamic and static scenes. Notably, PVG achieves this without relying on manually labeled object bounding boxes or expensive optical flow estimation. Moreover, PVG exhibits 50/6000-fold acceleration in training/rendering over the best alternative.
Meta-Learning-Based Adaptive Stability Certificates for Dynamical Systems
Dec 23, 2023This paper addresses the problem of Neural Network (NN) based adaptive stability certification in a dynamical system. The state-of-the-art methods, such as Neural Lyapunov Functions (NLFs), use NN-based formulations to assess the stability of a non-linear dynamical system and compute a Region of Attraction (ROA) in the state space. However, under parametric uncertainty, if the values of system parameters vary over time, the NLF methods fail to adapt to such changes and may lead to conservative stability assessment performance. We circumvent this issue by integrating Model Agnostic Meta-learning (MAML) with NLFs and propose meta-NLFs. In this process, we train a meta-function that adapts to any parametric shifts and updates into an NLF for the system with new test-time parameter values. We demonstrate the stability assessment performance of meta-NLFs on some standard benchmark autonomous dynamical systems.
Quantifying Policy Administration Cost in an Active Learning Framework
Dec 29, 2023This paper proposes a computational model for policy administration. As an organization evolves, new users and resources are gradually placed under the mediation of the access control model. Each time such new entities are added, the policy administrator must deliberate on how the access control policy shall be revised to reflect the new reality. A well-designed access control model must anticipate such changes so that the administration cost does not become prohibitive when the organization scales up. Unfortunately, past Access Control research does not offer a formal way to quantify the cost of policy administration. In this work, we propose to model ongoing policy administration in an active learning framework. Administration cost can be quantified in terms of query complexity. We demonstrate the utility of this approach by applying it to the evolution of protection domains. We also modelled different policy administration strategies in our framework. This allowed us to formally demonstrate that domain-based policies have a cost advantage over access control matrices because of the use of heuristic reasoning when the policy evolves. To the best of our knowledge, this is the first work to employ an active learning framework to study the cost of policy deliberation and demonstrate the cost advantage of heuristic policy administration.
FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis
Dec 29, 2023Diffusion models have transformed the image-to-image (I2I) synthesis and are now permeating into videos. However, the advancement of video-to-video (V2V) synthesis has been hampered by the challenge of maintaining temporal consistency across video frames. This paper proposes a consistent V2V synthesis framework by jointly leveraging spatial conditions and temporal optical flow clues within the source video. Contrary to prior methods that strictly adhere to optical flow, our approach harnesses its benefits while handling the imperfection in flow estimation. We encode the optical flow via warping from the first frame and serve it as a supplementary reference in the diffusion model. This enables our model for video synthesis by editing the first frame with any prevalent I2I models and then propagating edits to successive frames. Our V2V model, FlowVid, demonstrates remarkable properties: (1) Flexibility: FlowVid works seamlessly with existing I2I models, facilitating various modifications, including stylization, object swaps, and local edits. (2) Efficiency: Generation of a 4-second video with 30 FPS and 512x512 resolution takes only 1.5 minutes, which is 3.1x, 7.2x, and 10.5x faster than CoDeF, Rerender, and TokenFlow, respectively. (3) High-quality: In user studies, our FlowVid is preferred 45.7% of the time, outperforming CoDeF (3.5%), Rerender (10.2%), and TokenFlow (40.4%).
Structured Estimation of Heterogeneous Time Series
Nov 15, 2023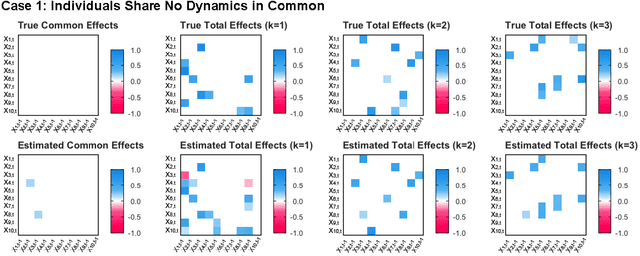
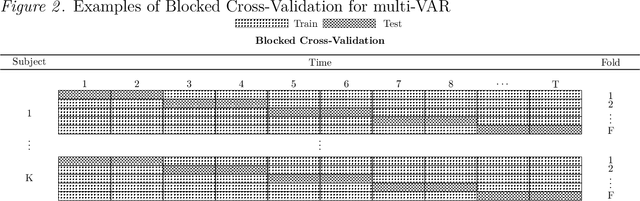
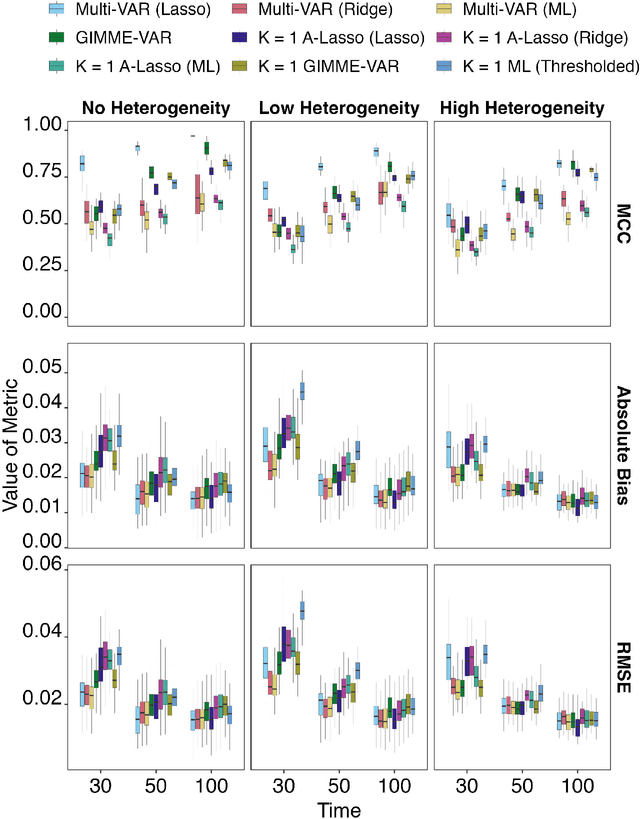
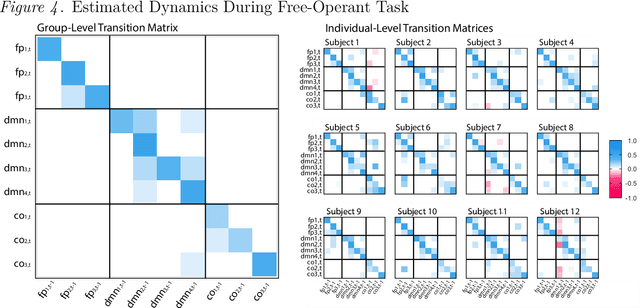
How best to model structurally heterogeneous processes is a foundational question in the social, health and behavioral sciences. Recently, Fisher et al., (2022) introduced the multi-VAR approach for simultaneously estimating multiple-subject multivariate time series characterized by common and individualizing features using penalized estimation. This approach differs from many popular modeling approaches for multiple-subject time series in that qualitative and quantitative differences in a large number of individual dynamics are well-accommodated. The current work extends the multi-VAR framework to include new adaptive weighting schemes that greatly improve estimation performance. In a small set of simulation studies we compare adaptive multi-VAR with these new penalty weights to common alternative estimators in terms of path recovery and bias. Furthermore, we provide toy examples and code demonstrating the utility of multi-VAR under different heterogeneity regimes using the multivar package for R (Fisher, 2022).
Enabling Smart Retrofitting and Performance Anomaly Detection for a Sensorized Vessel: A Maritime Industry Experience
Dec 30, 2023The integration of sensorized vessels, enabling real-time data collection and machine learning-driven data analysis marks a pivotal advancement in the maritime industry. This transformative technology not only can enhance safety, efficiency, and sustainability but also usher in a new era of cost-effective and smart maritime transportation in our increasingly interconnected world. This study presents a deep learning-driven anomaly detection system augmented with interpretable machine learning models for identifying performance anomalies in an industrial sensorized vessel, called TUCANA. We Leverage a human-in-the-loop unsupervised process that involves utilizing standard and Long Short-Term Memory (LSTM) autoencoders augmented with interpretable surrogate models, i.e., random forest and decision tree, to add transparency and interpretability to the results provided by the deep learning models. The interpretable models also enable automated rule generation for translating the inference into human-readable rules. Additionally, the process also includes providing a projection of the results using t-distributed stochastic neighbor embedding (t-SNE), which helps with a better understanding of the structure and relationships within the data and assessment of the identified anomalies. We empirically evaluate the system using real data acquired from the vessel TUCANA and the results involve achieving over 80% precision and 90% recall with the LSTM model used in the process. The interpretable models also provide logical rules aligned with expert thinking, and the t-SNE-based projection enhances interpretability. Our system demonstrates that the proposed approach can be used effectively in real-world scenarios, offering transparency and precision in performance anomaly detection.
FIKIT: Priority-Based Real-time GPU Multi-tasking Scheduling with Kernel Identification
Nov 24, 2023Highly parallelized workloads like machine learning training, inferences and general HPC tasks are greatly accelerated using GPU devices. In a cloud computing cluster, serving a GPU's computation power through multi-tasks sharing is highly demanded since there are always more task requests than the number of GPU available. Existing GPU sharing solutions focus on reducing task-level waiting time or task-level switching costs when multiple jobs competing for a single GPU. Non-stopped computation requests come with different priorities, having non-symmetric impact on QoS for sharing a GPU device. Existing work missed the kernel-level optimization opportunity brought by this setting. To address this problem, we present a novel kernel-level scheduling strategy called FIKIT: Filling Inter-kernel Idle Time. FIKIT incorporates task-level priority information, fine-grained kernel identification, and kernel measurement, allowing low priorities task's execution during high priority task's inter-kernel idle time. Thereby, filling the GPU's device runtime fully, and reduce overall GPU sharing impact to cloud services. Across a set of ML models, the FIKIT based inference system accelerated high priority tasks by 1.33 to 14.87 times compared to the JCT in GPU sharing mode, and more than half of the cases are accelerated by more than 3.5 times. Alternatively, under preemptive sharing, the low-priority tasks have a comparable to default GPU sharing mode JCT, with a 0.84 to 1 times ratio. We further limit the kernel measurement and runtime fine-grained kernel scheduling overhead to less than 10%.
CARSS: Cooperative Attention-guided Reinforcement Subpath Synthesis for Solving Traveling Salesman Problem
Dec 24, 2023This paper introduces CARSS (Cooperative Attention-guided Reinforcement Subpath Synthesis), a novel approach to address the Traveling Salesman Problem (TSP) by leveraging cooperative Multi-Agent Reinforcement Learning (MARL). CARSS decomposes the TSP solving process into two distinct yet synergistic steps: "subpath generation" and "subpath merging." In the former, a cooperative MARL framework is employed to iteratively generate subpaths using multiple agents. In the latter, these subpaths are progressively merged to form a complete cycle. The algorithm's primary objective is to enhance efficiency in terms of training memory consumption, testing time, and scalability, through the adoption of a multi-agent divide and conquer paradigm. Notably, attention mechanisms play a pivotal role in feature embedding and parameterization strategies within CARSS. The training of the model is facilitated by the independent REINFORCE algorithm. Empirical experiments reveal CARSS's superiority compared to single-agent alternatives: it demonstrates reduced GPU memory utilization, accommodates training graphs nearly 2.5 times larger, and exhibits the potential for scaling to even more extensive problem sizes. Furthermore, CARSS substantially reduces testing time and optimization gaps by approximately 50% for TSP instances of up to 1000 vertices, when compared to standard decoding methods.
Timeliness: A New Design Metric and a New Attack Surface
Dec 28, 2023As the landscape of time-sensitive applications gains prominence in 5G/6G communications, timeliness of information updates at network nodes has become crucial, which is popularly quantified in the literature by the age of information metric. However, as we devise policies to improve age of information of our systems, we inadvertently introduce a new vulnerability for adversaries to exploit. In this article, we comprehensively discuss the diverse threats that age-based systems are vulnerable to. We begin with discussion on densely interconnected networks that employ gossiping between nodes to expedite dissemination of dynamic information in the network, and show how the age-based nature of gossiping renders these networks uniquely susceptible to threats such as timestomping attacks, jamming attacks, and the propagation of misinformation. Later, we survey adversarial works within simpler network settings, specifically in one-hop and two-hop configurations, and delve into adversarial robustness concerning challenges posed by jamming, timestomping, and issues related to privacy leakage. We conclude this article with future directions that aim to address challenges posed by more intelligent adversaries and robustness of networks to them.