 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Comparison of Extended and Unscented Kalman Filters Performance in a Hybrid BLE-UWB Localization System
Apr 03, 2024
The paper presents a comparison of performance of two Kalman Filters: extended Kalman filter (EKF) and unscented Kalman filter (UKF) in a hybrid Bluetooth-Low-Energy-ultra-wideband (BLE-UWB) based localization system. In the system, the user is localized primarily based on Received Signal Strength (RSS) measurements of BLE signals. The UWB part of the system is periodically used to improve localization accuracy by supplying the algorithm with measured UWB packets time difference of arrival (TDOA). The proposed scheme was experimentally validated using two algorithms: the EKF and the UKF. The localization accuracy of both algorithms is compared.
Carbon Footprint Reduction for Sustainable Data Centers in Real-Time
Mar 21, 2024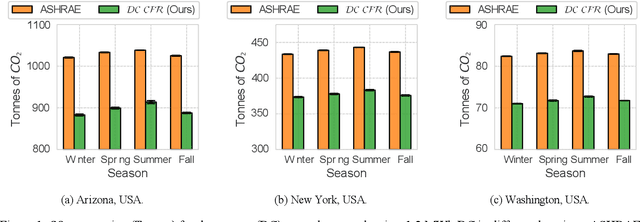

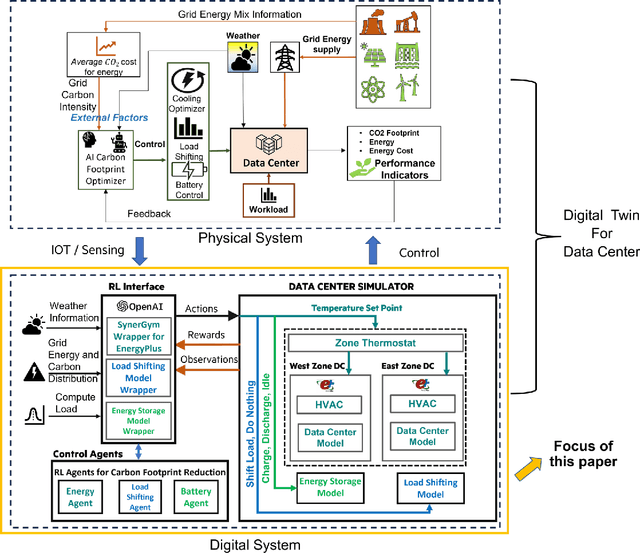
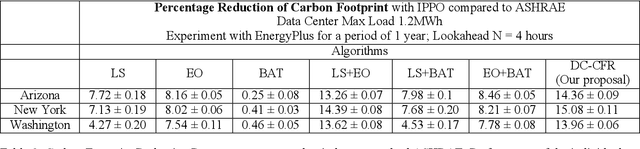
As machine learning workloads significantly increase energy consumption, sustainable data centers with low carbon emissions are becoming a top priority for governments and corporations worldwide. This requires a paradigm shift in optimizing power consumption in cooling and IT loads, shifting flexible loads based on the availability of renewable energy in the power grid, and leveraging battery storage from the uninterrupted power supply in data centers, using collaborative agents. The complex association between these optimization strategies and their dependencies on variable external factors like weather and the power grid carbon intensity makes this a hard problem. Currently, a real-time controller to optimize all these goals simultaneously in a dynamic real-world setting is lacking. We propose a Data Center Carbon Footprint Reduction (DC-CFR) multi-agent Reinforcement Learning (MARL) framework that optimizes data centers for the multiple objectives of carbon footprint reduction, energy consumption, and energy cost. The results show that the DC-CFR MARL agents effectively resolved the complex interdependencies in optimizing cooling, load shifting, and energy storage in real-time for various locations under real-world dynamic weather and grid carbon intensity conditions. DC-CFR significantly outperformed the industry standard ASHRAE controller with a considerable reduction in carbon emissions (14.5%), energy usage (14.4%), and energy cost (13.7%) when evaluated over one year across multiple geographical regions.
Efficient Diffusion-Driven Corruption Editor for Test-Time Adaptation
Mar 19, 2024

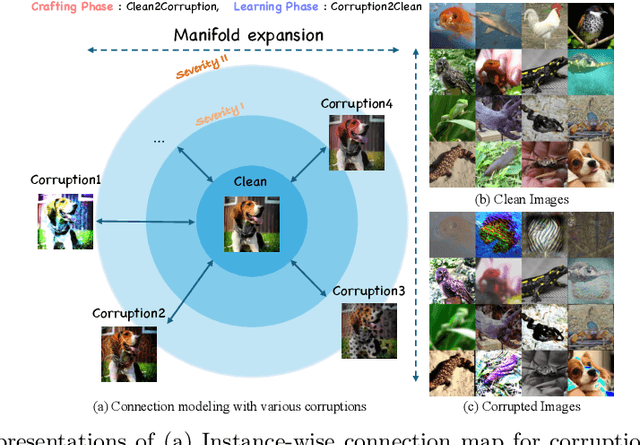

Test-time adaptation (TTA) addresses the unforeseen distribution shifts occurring during test time. In TTA, both performance and, memory and time consumption serve as crucial considerations. A recent diffusion-based TTA approach for restoring corrupted images involves image-level updates. However, using pixel space diffusion significantly increases resource requirements compared to conventional model updating TTA approaches, revealing limitations as a TTA method. To address this, we propose a novel TTA method by leveraging a latent diffusion model (LDM) based image editing model and fine-tuning it with our newly introduced corruption modeling scheme. This scheme enhances the robustness of the diffusion model against distribution shifts by creating (clean, corrupted) image pairs and fine-tuning the model to edit corrupted images into clean ones. Moreover, we introduce a distilled variant to accelerate the model for corruption editing using only 4 network function evaluations (NFEs). We extensively validated our method across various architectures and datasets including image and video domains. Our model achieves the best performance with a 100 times faster runtime than that of a diffusion-based baseline. Furthermore, it outpaces the speed of the model updating TTA method based on data augmentation threefold, rendering an image-level updating approach more practical.
CMAT: A Multi-Agent Collaboration Tuning Framework for Enhancing Small Language Models
Apr 04, 2024Open large language models (LLMs) have significantly advanced the field of natural language processing, showcasing impressive performance across various tasks.Despite the significant advancements in LLMs, their effective operation still relies heavily on human input to accurately guide the dialogue flow, with agent tuning being a crucial optimization technique that involves human adjustments to the model for better response to such guidance.Addressing this dependency, our work introduces the TinyAgent model, trained on a meticulously curated high-quality dataset. We also present the Collaborative Multi-Agent Tuning (CMAT) framework, an innovative system designed to augment language agent capabilities through adaptive weight updates based on environmental feedback. This framework fosters collaborative learning and real-time adaptation among multiple intelligent agents, enhancing their context-awareness and long-term memory. In this research, we propose a new communication agent framework that integrates multi-agent systems with environmental feedback mechanisms, offering a scalable method to explore cooperative behaviors. Notably, our TinyAgent-7B model exhibits performance on par with GPT-3.5, despite having fewer parameters, signifying a substantial improvement in the efficiency and effectiveness of LLMs.
Transforming LLMs into Cross-modal and Cross-lingual Retrieval Systems
Apr 04, 2024Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
Legible and Proactive Robot Planning for Prosocial Human-Robot Interactions
Apr 04, 2024Humans have a remarkable ability to fluently engage in joint collision avoidance in crowded navigation tasks despite the complexities and uncertainties inherent in human behavior. Underlying these interactions is a mutual understanding that (i) individuals are prosocial, that is, there is equitable responsibility in avoiding collisions, and (ii) individuals should behave legibly, that is, move in a way that clearly conveys their intent to reduce ambiguity in how they intend to avoid others. Toward building robots that can safely and seamlessly interact with humans, we propose a general robot trajectory planning framework for synthesizing legible and proactive behaviors and demonstrate that our robot planner naturally leads to prosocial interactions. Specifically, we introduce the notion of a markup factor to incentivize legible and proactive behaviors and an inconvenience budget constraint to ensure equitable collision avoidance responsibility. We evaluate our approach against well-established multi-agent planning algorithms and show that using our approach produces safe, fluent, and prosocial interactions. We demonstrate the real-time feasibility of our approach with human-in-the-loop simulations. Project page can be found at https://uw-ctrl.github.io/phri/.
DiffDet4SAR: Diffusion-based Aircraft Target Detection Network for SAR Images
Apr 04, 2024Aircraft target detection in SAR images is a challenging task due to the discrete scattering points and severe background clutter interference. Currently, methods with convolution-based or transformer-based paradigms cannot adequately address these issues. In this letter, we explore diffusion models for SAR image aircraft target detection for the first time and propose a novel \underline{Diff}usion-based aircraft target \underline{Det}ection network \underline{for} \underline{SAR} images (DiffDet4SAR). Specifically, the proposed DiffDet4SAR yields two main advantages for SAR aircraft target detection: 1) DiffDet4SAR maps the SAR aircraft target detection task to a denoising diffusion process of bounding boxes without heuristic anchor size selection, effectively enabling large variations in aircraft sizes to be accommodated; and 2) the dedicatedly designed Scattering Feature Enhancement (SFE) module further reduces the clutter intensity and enhances the target saliency during inference. Extensive experimental results on the SAR-AIRcraft-1.0 dataset show that the proposed DiffDet4SAR achieves 88.4\% mAP$_{50}$, outperforming the state-of-the-art methods by 6\%. Code is availabel at \href{https://github.com/JoyeZLearning/DiffDet4SAR}.
Embodied AI with Two Arms: Zero-shot Learning, Safety and Modularity
Apr 04, 2024We present an embodied AI system which receives open-ended natural language instructions from a human, and controls two arms to collaboratively accomplish potentially long-horizon tasks over a large workspace. Our system is modular: it deploys state of the art Large Language Models for task planning,Vision-Language models for semantic perception, and Point Cloud transformers for grasping. With semantic and physical safety in mind, these modules are interfaced with a real-time trajectory optimizer and a compliant tracking controller to enable human-robot proximity. We demonstrate performance for the following tasks: bi-arm sorting, bottle opening, and trash disposal tasks. These are done zero-shot where the models used have not been trained with any real world data from this bi-arm robot, scenes or workspace.Composing both learning- and non-learning-based components in a modular fashion with interpretable inputs and outputs allows the user to easily debug points of failures and fragilities. One may also in-place swap modules to improve the robustness of the overall platform, for instance with imitation-learned policies.
LancBiO: dynamic Lanczos-aided bilevel optimization via Krylov subspace
Apr 04, 2024Bilevel optimization, with broad applications in machine learning, has an intricate hierarchical structure. Gradient-based methods have emerged as a common approach to large-scale bilevel problems. However, the computation of the hyper-gradient, which involves a Hessian inverse vector product, confines the efficiency and is regarded as a bottleneck. To circumvent the inverse, we construct a sequence of low-dimensional approximate Krylov subspaces with the aid of the Lanczos process. As a result, the constructed subspace is able to dynamically and incrementally approximate the Hessian inverse vector product with less effort and thus leads to a favorable estimate of the hyper-gradient. Moreover, we propose a~provable subspace-based framework for bilevel problems where one central step is to solve a small-size tridiagonal linear system. To the best of our knowledge, this is the first time that subspace techniques are incorporated into bilevel optimization. This successful trial not only enjoys $\mathcal{O}(\epsilon^{-1})$ convergence rate but also demonstrates efficiency in a synthetic problem and two deep learning tasks.
BioVL-QR: Egocentric Biochemical Video-and-Language Dataset Using Micro QR Codes
Apr 04, 2024This paper introduces a biochemical vision-and-language dataset, which consists of 24 egocentric experiment videos, corresponding protocols, and video-and-language alignments. The key challenge in the wet-lab domain is detecting equipment, reagents, and containers is difficult because the lab environment is scattered by filling objects on the table and some objects are indistinguishable. Therefore, previous studies assume that objects are manually annotated and given for downstream tasks, but this is costly and time-consuming. To address this issue, this study focuses on Micro QR Codes to detect objects automatically. From our preliminary study, we found that detecting objects only using Micro QR Codes is still difficult because the researchers manipulate objects, causing blur and occlusion frequently. To address this, we also propose a novel object labeling method by combining a Micro QR Code detector and an off-the-shelf hand object detector. As one of the applications of our dataset, we conduct the task of generating protocols from experiment videos and find that our approach can generate accurate protocols.