 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analyzing Public Reactions, Perceptions, and Attitudes during the MPox Outbreak: Findings from Topic Modeling of Tweets
Dec 19, 2023
The recent outbreak of the MPox virus has resulted in a tremendous increase in the usage of Twitter. Prior works in this area of research have primarily focused on the sentiment analysis and content analysis of these Tweets, and the few works that have focused on topic modeling have multiple limitations. This paper aims to address this research gap and makes two scientific contributions to this field. First, it presents the results of performing Topic Modeling on 601,432 Tweets about the 2022 Mpox outbreak that were posted on Twitter between 7 May 2022 and 3 March 2023. The results indicate that the conversations on Twitter related to Mpox during this time range may be broadly categorized into four distinct themes - Views and Perspectives about Mpox, Updates on Cases and Investigations about Mpox, Mpox and the LGBTQIA+ Community, and Mpox and COVID-19. Second, the paper presents the findings from the analysis of these Tweets. The results show that the theme that was most popular on Twitter (in terms of the number of Tweets posted) during this time range was Views and Perspectives about Mpox. This was followed by the theme of Mpox and the LGBTQIA+ Community, which was followed by the themes of Mpox and COVID-19 and Updates on Cases and Investigations about Mpox, respectively. Finally, a comparison with related studies in this area of research is also presented to highlight the novelty and significance of this research work.
Perspectives on the State and Future of Deep Learning - 2023
Dec 19, 2023The goal of this series is to chronicle opinions and issues in the field of machine learning as they stand today and as they change over time. The plan is to host this survey periodically until the AI singularity paperclip-frenzy-driven doomsday, keeping an updated list of topical questions and interviewing new community members for each edition. In this issue, we probed people's opinions on interpretable AI, the value of benchmarking in modern NLP, the state of progress towards understanding deep learning, and the future of academia.
LETA: Learning Transferable Attribution for Generic Vision Explainer
Dec 23, 2023Explainable machine learning significantly improves the transparency of deep neural networks~(DNN). However, existing work is constrained to explaining the behavior of individual model predictions, and lacks the ability to transfer the explanation across various models and tasks. This limitation results in explaining various tasks being time- and resource-consuming. To address this problem, we develop a pre-trained, DNN-based, generic explainer on large-scale image datasets, and leverage its transferability to explain various vision models for downstream tasks. In particular, the pre-training of generic explainer focuses on LEarning Transferable Attribution (LETA). The transferable attribution takes advantage of the versatile output of the target backbone encoders to comprehensively encode the essential attribution for explaining various downstream tasks. LETA guides the pre-training of the generic explainer towards the transferable attribution, and introduces a rule-based adaptation of the transferable attribution for explaining downstream tasks, without the need for additional training on downstream data. Theoretical analysis demonstrates that the pre-training of LETA enables minimizing the explanation error bound aligned with the conditional $\mathcal{V}$-information on downstream tasks. Empirical studies involve explaining three different architectures of vision models across three diverse downstream datasets. The experiment results indicate LETA is effective in explaining these tasks without the need for additional training on the data of downstream tasks.
Benefit from public unlabeled data: A Frangi filtering-based pretraining network for 3D cerebrovascular segmentation
Dec 23, 2023The precise cerebrovascular segmentation in time-of-flight magnetic resonance angiography (TOF-MRA) data is crucial for clinically computer-aided diagnosis. However, the sparse distribution of cerebrovascular structures in TOF-MRA results in an exceedingly high cost for manual data labeling. The use of unlabeled TOF-MRA data holds the potential to enhance model performance significantly. In this study, we construct the largest preprocessed unlabeled TOF-MRA datasets (1510 subjects) to date. We also provide three additional labeled datasets totaling 113 subjects. Furthermore, we propose a simple yet effective pertraining strategy based on Frangi filtering, known for enhancing vessel-like structures, to fully leverage the unlabeled data for 3D cerebrovascular segmentation. Specifically, we develop a Frangi filtering-based preprocessing workflow to handle the large-scale unlabeled dataset, and a multi-task pretraining strategy is proposed to effectively utilize the preprocessed data. By employing this approach, we maximize the knowledge gained from the unlabeled data. The pretrained model is evaluated on four cerebrovascular segmentation datasets. The results have demonstrated the superior performance of our model, with an improvement of approximately 3\% compared to state-of-the-art semi- and self-supervised methods. Furthermore, the ablation studies also demonstrate the generalizability and effectiveness of the pretraining method regarding the backbone structures. The code and data have been open source at: \url{https://github.com/shigen-StoneRoot/FFPN}.
Efficient Asynchronous Federated Learning with Sparsification and Quantization
Dec 23, 2023While data is distributed in multiple edge devices, Federated Learning (FL) is attracting more and more attention to collaboratively train a machine learning model without transferring raw data. FL generally exploits a parameter server and a large number of edge devices during the whole process of the model training, while several devices are selected in each round. However, straggler devices may slow down the training process or even make the system crash during training. Meanwhile, other idle edge devices remain unused. As the bandwidth between the devices and the server is relatively low, the communication of intermediate data becomes a bottleneck. In this paper, we propose Time-Efficient Asynchronous federated learning with Sparsification and Quantization, i.e., TEASQ-Fed. TEASQ-Fed can fully exploit edge devices to asynchronously participate in the training process by actively applying for tasks. We utilize control parameters to choose an appropriate number of parallel edge devices, which simultaneously execute the training tasks. In addition, we introduce a caching mechanism and weighted averaging with respect to model staleness to further improve the accuracy. Furthermore, we propose a sparsification and quantitation approach to compress the intermediate data to accelerate the training. The experimental results reveal that TEASQ-Fed improves the accuracy (up to 16.67% higher) while accelerating the convergence of model training (up to twice faster).
Multiscale Neural Operators for Solving Time-Independent PDEs
Nov 10, 2023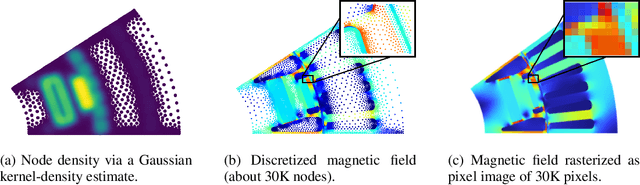
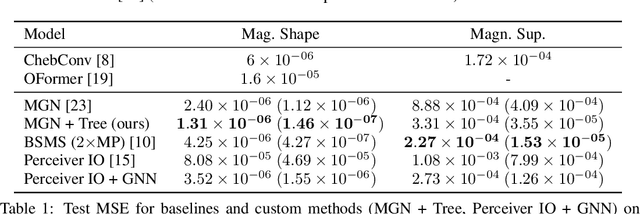
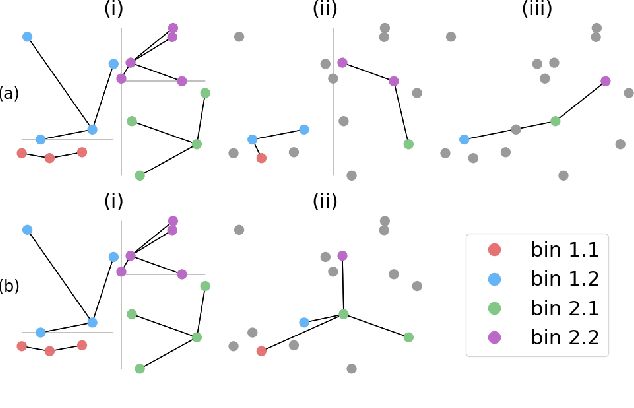

Time-independent Partial Differential Equations (PDEs) on large meshes pose significant challenges for data-driven neural PDE solvers. We introduce a novel graph rewiring technique to tackle some of these challenges, such as aggregating information across scales and on irregular meshes. Our proposed approach bridges distant nodes, enhancing the global interaction capabilities of GNNs. Our experiments on three datasets reveal that GNN-based methods set new performance standards for time-independent PDEs on irregular meshes. Finally, we show that our graph rewiring strategy boosts the performance of baseline methods, achieving state-of-the-art results in one of the tasks.
Sketching Multidimensional Time Series for Fast Discord Mining
Nov 05, 2023
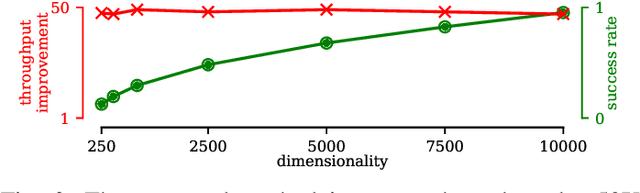
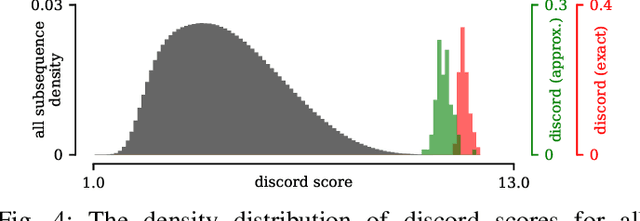
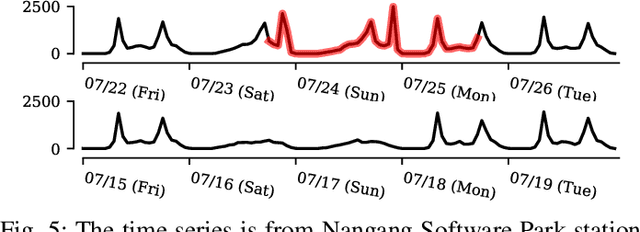
Time series discords are a useful primitive for time series anomaly detection, and the matrix profile is capable of capturing discord effectively. There exist many research efforts to improve the scalability of discord discovery with respect to the length of time series. However, there is surprisingly little work focused on reducing the time complexity of matrix profile computation associated with dimensionality of a multidimensional time series. In this work, we propose a sketch for discord mining among multi-dimensional time series. After an initial pre-processing of the sketch as fast as reading the data, the discord mining has runtime independent of the dimensionality of the original data. On several real world examples from water treatment and transportation, the proposed algorithm improves the throughput by at least an order of magnitude (50X) and only has minimal impact on the quality of the approximated solution. Additionally, the proposed method can handle the dynamic addition or deletion of dimensions inconsequential overhead. This allows a data analyst to consider "what-if" scenarios in real time while exploring the data.
StyleRetoucher: Generalized Portrait Image Retouching with GAN Priors
Dec 22, 2023Creating fine-retouched portrait images is tedious and time-consuming even for professional artists. There exist automatic retouching methods, but they either suffer from over-smoothing artifacts or lack generalization ability. To address such issues, we present StyleRetoucher, a novel automatic portrait image retouching framework, leveraging StyleGAN's generation and generalization ability to improve an input portrait image's skin condition while preserving its facial details. Harnessing the priors of pretrained StyleGAN, our method shows superior robustness: a). performing stably with fewer training samples and b). generalizing well on the out-domain data. Moreover, by blending the spatial features of the input image and intermediate features of the StyleGAN layers, our method preserves the input characteristics to the largest extent. We further propose a novel blemish-aware feature selection mechanism to effectively identify and remove the skin blemishes, improving the image skin condition. Qualitative and quantitative evaluations validate the great generalization capability of our method. Further experiments show StyleRetoucher's superior performance to the alternative solutions in the image retouching task. We also conduct a user perceptive study to confirm the superior retouching performance of our method over the existing state-of-the-art alternatives.
Adapt & Align: Continual Learning with Generative Models Latent Space Alignment
Dec 21, 2023In this work, we introduce Adapt & Align, a method for continual learning of neural networks by aligning latent representations in generative models. Neural Networks suffer from abrupt loss in performance when retrained with additional training data from different distributions. At the same time, training with additional data without access to the previous examples rarely improves the model's performance. In this work, we propose a new method that mitigates those problems by employing generative models and splitting the process of their update into two parts. In the first one, we train a local generative model using only data from a new task. In the second phase, we consolidate latent representations from the local model with a global one that encodes knowledge of all past experiences. We introduce our approach with Variational Auteoncoders and Generative Adversarial Networks. Moreover, we show how we can use those generative models as a general method for continual knowledge consolidation that can be used in downstream tasks such as classification.
Optimized classification with neural ODEs via separability
Dec 21, 2023Classification of $N$ points becomes a simultaneous control problem when viewed through the lens of neural ordinary differential equations (neural ODEs), which represent the time-continuous limit of residual networks. For the narrow model, with one neuron per hidden layer, it has been shown that the task can be achieved using $O(N)$ neurons. In this study, we focus on estimating the number of neurons required for efficient cluster-based classification, particularly in the worst-case scenario where points are independently and uniformly distributed in $[0,1]^d$. Our analysis provides a novel method for quantifying the probability of requiring fewer than $O(N)$ neurons, emphasizing the asymptotic behavior as both $d$ and $N$ increase. Additionally, under the sole assumption that the data are in general position, we propose a new constructive algorithm that simultaneously classifies clusters of $d$ points from any initial configuration, effectively reducing the maximal complexity to $O(N/d)$ neurons.