 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Faster Diffusion: Rethinking the Role of UNet Encoder in Diffusion Models
Dec 15, 2023
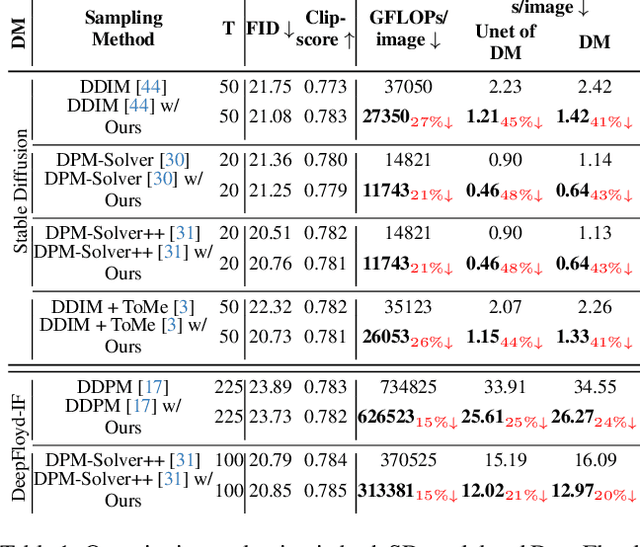
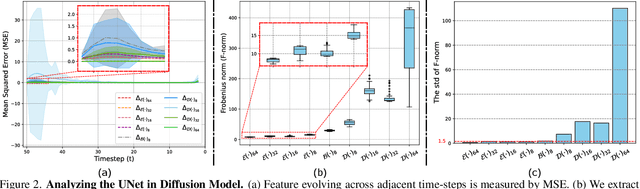
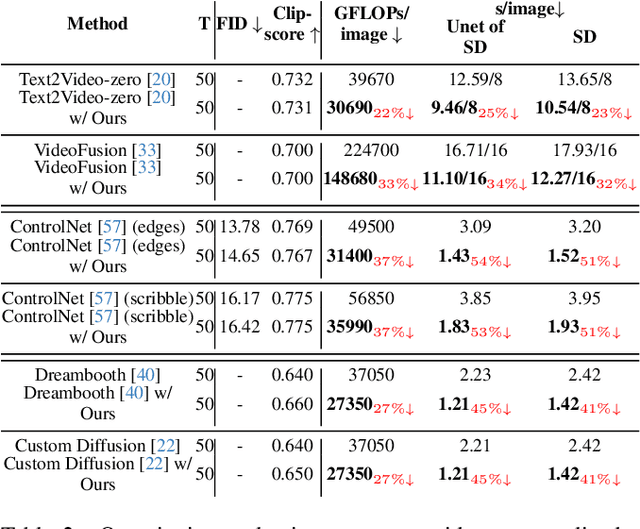
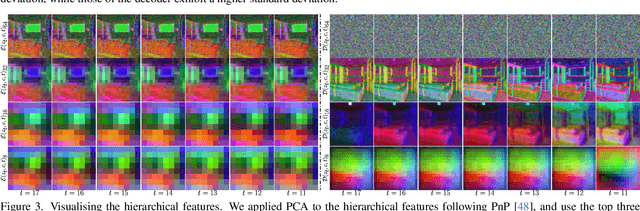
One of the key components within diffusion models is the UNet for noise prediction. While several works have explored basic properties of the UNet decoder, its encoder largely remains unexplored. In this work, we conduct the first comprehensive study of the UNet encoder. We empirically analyze the encoder features and provide insights to important questions regarding their changes at the inference process. In particular, we find that encoder features change gently, whereas the decoder features exhibit substantial variations across different time-steps. This finding inspired us to omit the encoder at certain adjacent time-steps and reuse cyclically the encoder features in the previous time-steps for the decoder. Further based on this observation, we introduce a simple yet effective encoder propagation scheme to accelerate the diffusion sampling for a diverse set of tasks. By benefiting from our propagation scheme, we are able to perform in parallel the decoder at certain adjacent time-steps. Additionally, we introduce a prior noise injection method to improve the texture details in the generated image. Besides the standard text-to-image task, we also validate our approach on other tasks: text-to-video, personalized generation and reference-guided generation. Without utilizing any knowledge distillation technique, our approach accelerates both the Stable Diffusion (SD) and the DeepFloyd-IF models sampling by 41$\%$ and 24$\%$ respectively, while maintaining high-quality generation performance. Our code is available in \href{https://github.com/hutaiHang/Faster-Diffusion}{FasterDiffusion}.
Navigating the Structured What-If Spaces: Counterfactual Generation via Structured Diffusion
Dec 21, 2023Generating counterfactual explanations is one of the most effective approaches for uncovering the inner workings of black-box neural network models and building user trust. While remarkable strides have been made in generative modeling using diffusion models in domains like vision, their utility in generating counterfactual explanations in structured modalities remains unexplored. In this paper, we introduce Structured Counterfactual Diffuser or SCD, the first plug-and-play framework leveraging diffusion for generating counterfactual explanations in structured data. SCD learns the underlying data distribution via a diffusion model which is then guided at test time to generate counterfactuals for any arbitrary black-box model, input, and desired prediction. Our experiments show that our counterfactuals not only exhibit high plausibility compared to the existing state-of-the-art but also show significantly better proximity and diversity.
Lookahead: An Inference Acceleration Framework for Large Language Model with Lossless Generation Accuracy
Dec 20, 2023As Large Language Models (LLMs) have made significant advancements across various tasks, such as question answering, translation, text summarization, and dialogue systems, the need for accuracy in information becomes crucial, especially for serious financial products serving billions of users like Alipay. To address this, Alipay has developed a Retrieval-Augmented Generation (RAG) system that grounds LLMs on the most accurate and up-to-date information. However, for a real-world product serving millions of users, the inference speed of LLMs becomes a critical factor compared to a mere experimental model. Hence, this paper presents a generic framework for accelerating the inference process, resulting in a substantial increase in speed and cost reduction for our RAG system, with lossless generation accuracy. In the traditional inference process, each token is generated sequentially by the LLM, leading to a time consumption proportional to the number of generated tokens. To enhance this process, our framework, named \textit{lookahead}, introduces a \textit{multi-branch} strategy. Instead of generating a single token at a time, we propose a \textit{Trie-based Retrieval} (TR) process that enables the generation of multiple branches simultaneously, each of which is a sequence of tokens. Subsequently, for each branch, a \textit{Verification and Accept} (VA) process is performed to identify the longest correct sub-sequence as the final output. Our strategy offers two distinct advantages: (1) it guarantees absolute correctness of the output, avoiding any approximation algorithms, and (2) the worst-case performance of our approach is equivalent to the conventional process. We conduct extensive experiments to demonstrate the significant improvements achieved by applying our inference acceleration framework.
Task Planning for Multiple Item Insertion using ADMM
Dec 20, 2023Mixed-integer nonlinear programmings (MINLPs) are powerful formulation tools for task planning. However, it suffers from long solving time especially for large scale problems. In this work, we first formulate the task planning problem for item stowing into a mixed-integer nonlinear programming problem, then solve it using Alternative Direction Method of Multipliers (ADMM). ADMM separates the complete formulation into a nonlinear programming problem and mixed-integer programming problem, then iterate between them to solve the original problem. We show that our ADMM converges better than non-warm-started nonlinear complementary formulation. Our proposed methods are demonstrated on hardware as a high level planner to insert books into the bookshelf.
Unconstrained Dysfluency Modeling for Dysfluent Speech Transcription and Detection
Dec 20, 2023Dysfluent speech modeling requires time-accurate and silence-aware transcription at both the word-level and phonetic-level. However, current research in dysfluency modeling primarily focuses on either transcription or detection, and the performance of each aspect remains limited. In this work, we present an unconstrained dysfluency modeling (UDM) approach that addresses both transcription and detection in an automatic and hierarchical manner. UDM eliminates the need for extensive manual annotation by providing a comprehensive solution. Furthermore, we introduce a simulated dysfluent dataset called VCTK++ to enhance the capabilities of UDM in phonetic transcription. Our experimental results demonstrate the effectiveness and robustness of our proposed methods in both transcription and detection tasks.
Dynamic Local Attention with Hierarchical Patching for Irregular Clinical Time Series
Nov 13, 2023Irregular multivariate time series data is prevalent in the clinical and healthcare domains. It is characterized by time-wise and feature-wise irregularities, making it challenging for machine learning methods to work with. To solve this, we introduce a new model architecture composed of two modules: (1) DLA, a Dynamic Local Attention mechanism that uses learnable queries and feature-specific local windows when computing the self-attention operation. This results in aggregating irregular time steps raw input within each window to a harmonized regular latent space representation while taking into account the different features' sampling rates. (2) A hierarchical MLP mixer that processes the output of DLA through multi-scale patching to leverage information at various scales for the downstream tasks. Our approach outperforms state-of-the-art methods on three real-world datasets, including the latest clinical MIMIC IV dataset.
FIKIT: Priority-Based Real-time GPU Multi-tasking Scheduling with Kernel Identification
Nov 17, 2023Highly parallelized workloads like machine learning training, inferences and general HPC tasks are greatly accelerated using GPU devices. In a cloud computing cluster, serving a GPU's computation power through multi-tasks sharing is highly demanded since there are always more task requests than the number of GPU available. Existing GPU sharing solutions focus on reducing task-level waiting time or task-level switching costs when multiple jobs competing for a single GPU. Non-stopped computation requests come with different priorities, having non-symmetric impact on QoS for sharing a GPU device. Existing work missed the kernel-level optimization opportunity brought by this setting. To address this problem, we present a novel kernel-level scheduling strategy called FIKIT: Filling Inter-kernel Idle Time. FIKIT incorporates task-level priority information, fine-grained kernel identification, and kernel measurement, allowing low priorities task's execution during high priority task's inter-kernel idle time. Thereby, filling the GPU's device runtime fully, and reduce overall GPU sharing impact to cloud services. Across a set of ML models, the FIKIT based inference system accelerated high priority tasks by 1.33 to 14.87 times compared to the JCT in GPU sharing mode, and more than half of the cases are accelerated by more than 3.5 times. Alternatively, under preemptive sharing, the low-priority tasks have a comparable to default GPU sharing mode JCT, with a 0.84 to 1 times ratio. We further limit the kernel measurement and runtime fine-grained kernel scheduling overhead to less than 10%.
On Safety and Liveness Filtering Using Hamilton-Jacobi Reachability Analysis
Dec 23, 2023Hamilton-Jacobi (HJ) reachability-based filtering provides a powerful framework to co-optimize performance and safety (or liveness) for autonomous systems. Under this filtering scheme, a nominal controller is minimally modified to ensure system safety or liveness. However, the resulting controllers can exhibit abrupt switching and bang-bang behavior, which is not suitable for applications of autonomous systems in the real world. This work presents a novel, unifying framework to design safety and liveness filters through reachability analysis. We explicitly characterize the maximal set of control inputs that ensures safety (or liveness) at a given state. Different safety filters can then be constructed using different subsets of this maximal set along with a projection operator to modify the nominal controller. We use the proposed framework to design three safety filters, each balancing performance, computation time, and smoothness differently. The proposed filters can easily handle dynamics uncertainties, disturbances, and bounded control inputs. We highlight their relative strengths and limitations by applying these filters to autonomous navigation and rocket landing scenarios and on a physical robot testbed. We also discuss practical aspects associated with implementing these filters on real-world autonomous systems. Our research advances the understanding and potential application of reachability-based controllers on real-world autonomous systems.
DTIAM: A unified framework for predicting drug-target interactions, binding affinities and activation/inhibition mechanisms
Dec 23, 2023Accurate and robust prediction of drug-target interactions (DTIs) plays a vital role in drug discovery. Despite extensive efforts have been invested in predicting novel DTIs, existing approaches still suffer from insufficient labeled data and cold start problems. More importantly, there is currently a lack of studies focusing on elucidating the mechanism of action (MoA) between drugs and targets. Distinguishing the activation and inhibition mechanisms is critical and challenging in drug development. Here, we introduce a unified framework called DTIAM, which aims to predict interactions, binding affinities, and activation/inhibition mechanisms between drugs and targets. DTIAM learns drug and target representations from large amounts of label-free data through self-supervised pre-training, which accurately extracts the substructure and contextual information of drugs and targets, and thus benefits the downstream prediction based on these representations. DTIAM achieves substantial performance improvement over other state-of-the-art methods in all tasks, particularly in the cold start scenario. Moreover, independent validation demonstrates the strong generalization ability of DTIAM. All these results suggested that DTIAM can provide a practically useful tool for predicting novel DTIs and further distinguishing the MoA of candidate drugs. DTIAM, for the first time, provides a unified framework for accurate and robust prediction of drug-target interactions, binding affinities, and activation/inhibition mechanisms.
Learning Continuous Implicit Field with Local Distance Indicator for Arbitrary-Scale Point Cloud Upsampling
Dec 23, 2023Point cloud upsampling aims to generate dense and uniformly distributed point sets from a sparse point cloud, which plays a critical role in 3D computer vision. Previous methods typically split a sparse point cloud into several local patches, upsample patch points, and merge all upsampled patches. However, these methods often produce holes, outliers or nonuniformity due to the splitting and merging process which does not maintain consistency among local patches. To address these issues, we propose a novel approach that learns an unsigned distance field guided by local priors for point cloud upsampling. Specifically, we train a local distance indicator (LDI) that predicts the unsigned distance from a query point to a local implicit surface. Utilizing the learned LDI, we learn an unsigned distance field to represent the sparse point cloud with patch consistency. At inference time, we randomly sample queries around the sparse point cloud, and project these query points onto the zero-level set of the learned implicit field to generate a dense point cloud. We justify that the implicit field is naturally continuous, which inherently enables the application of arbitrary-scale upsampling without necessarily retraining for various scales. We conduct comprehensive experiments on both synthetic data and real scans, and report state-of-the-art results under widely used benchmarks.