 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Test-Time Augmentation for 3D Point Cloud Classification and Segmentation
Nov 22, 2023
Data augmentation is a powerful technique to enhance the performance of a deep learning task but has received less attention in 3D deep learning. It is well known that when 3D shapes are sparsely represented with low point density, the performance of the downstream tasks drops significantly. This work explores test-time augmentation (TTA) for 3D point clouds. We are inspired by the recent revolution of learning implicit representation and point cloud upsampling, which can produce high-quality 3D surface reconstruction and proximity-to-surface, respectively. Our idea is to leverage the implicit field reconstruction or point cloud upsampling techniques as a systematic way to augment point cloud data. Mainly, we test both strategies by sampling points from the reconstructed results and using the sampled point cloud as test-time augmented data. We show that both strategies are effective in improving accuracy. We observed that point cloud upsampling for test-time augmentation can lead to more significant performance improvement on downstream tasks such as object classification and segmentation on the ModelNet40, ShapeNet, ScanObjectNN, and SemanticKITTI datasets, especially for sparse point clouds.
An Adaptive Framework of Geographical Group-Specific Network on O2O Recommendation
Dec 28, 2023Online to offline recommendation strongly correlates with the user and service's spatiotemporal information, therefore calling for a higher degree of model personalization. The traditional methodology is based on a uniform model structure trained by collected centralized data, which is unlikely to capture all user patterns over different geographical areas or time periods. To tackle this challenge, we propose a geographical group-specific modeling method called GeoGrouse, which simultaneously studies the common knowledge as well as group-specific knowledge of user preferences. An automatic grouping paradigm is employed and verified based on users' geographical grouping indicators. Offline and online experiments are conducted to verify the effectiveness of our approach, and substantial business improvement is achieved.
Tissue Artifact Segmentation and Severity Analysis for Automated Diagnosis Using Whole Slide Images
Jan 01, 2024Traditionally, pathological analysis and diagnosis are performed by manually eyeballing glass slide specimens under a microscope by an expert. The whole slide image is the digital specimen produced from the glass slide. Whole slide image enabled specimens to be observed on a computer screen and led to computational pathology where computer vision and artificial intelligence are utilized for automated analysis and diagnosis. With the current computational advancement, the entire whole slide image can be analyzed autonomously without human supervision. However, the analysis could fail or lead to wrong diagnosis if the whole slide image is affected by tissue artifacts such as tissue fold or air bubbles depending on the severity. Existing artifact detection methods rely on experts for severity assessment to eliminate artifact affected regions from the analysis. This process is time consuming, exhausting and undermines the goal of automated analysis or removal of artifacts without evaluating their severity, which could result in the loss of diagnostically important data. Therefore, it is necessary to detect artifacts and then assess their severity automatically. In this paper, we propose a system that incorporates severity evaluation with artifact detection utilizing convolutional neural networks. The proposed system uses DoubleUNet to segment artifacts and an ensemble network of six fine tuned convolutional neural network models to determine severity. This method outperformed current state of the art in accuracy by 9 percent for artifact segmentation and achieved a strong correlation of 97 percent with the evaluation of pathologists for severity assessment. The robustness of the system was demonstrated using our proposed heterogeneous dataset and practical usability was ensured by integrating it with an automated analysis system.
* 60 pages, 21 figures, 16 tables
A Computational Framework for Behavioral Assessment of LLM Therapists
Jan 01, 2024The emergence of ChatGPT and other large language models (LLMs) has greatly increased interest in utilizing LLMs as therapists to support individuals struggling with mental health challenges. However, due to the lack of systematic studies, our understanding of how LLM therapists behave, i.e., ways in which they respond to clients, is significantly limited. Understanding their behavior across a wide range of clients and situations is crucial to accurately assess their capabilities and limitations in the high-risk setting of mental health, where undesirable behaviors can lead to severe consequences. In this paper, we propose BOLT, a novel computational framework to study the conversational behavior of LLMs when employed as therapists. We develop an in-context learning method to quantitatively measure the behavior of LLMs based on 13 different psychotherapy techniques including reflections, questions, solutions, normalizing, and psychoeducation. Subsequently, we compare the behavior of LLM therapists against that of high- and low-quality human therapy, and study how their behavior can be modulated to better reflect behaviors observed in high-quality therapy. Our analysis of GPT and Llama-variants reveals that these LLMs often resemble behaviors more commonly exhibited in low-quality therapy rather than high-quality therapy, such as offering a higher degree of problem-solving advice when clients share emotions, which is against typical recommendations. At the same time, unlike low-quality therapy, LLMs reflect significantly more upon clients' needs and strengths. Our analysis framework suggests that despite the ability of LLMs to generate anecdotal examples that appear similar to human therapists, LLM therapists are currently not fully consistent with high-quality care, and thus require additional research to ensure quality care.
Detecting the presence of sperm whales echolocation clicks in noisy environments
Dec 31, 2023Sperm whales (Physeter macrocephalus) navigate underwater with a series of impulsive, click-like sounds known as echolocation clicks. These clicks are characterized by a multipulse structure (MPS) that serves as a distinctive pattern. In this work, we use the stability of the MPS as a detection metric for recognizing and classifying the presence of clicks in noisy environments. To distinguish between noise transients and to handle simultaneous emissions from multiple sperm whales, our approach clusters a time series of MPS measures while removing potential clicks that do not fulfil the limits of inter-click interval, duration and spectrum. As a result, our approach can handle high noise transients and low signal-to-noise ratio. The performance of our detection approach is examined using three datasets: seven months of recordings from the Mediterranean Sea containing manually verified ambient noise; several days of manually labelled data collected from the Dominica Island containing approximately 40,000 clicks from multiple sperm whales; and a dataset from the Bahamas containing 1,203 labelled clicks from a single sperm whale. Comparing with the results of two benchmark detectors, a better trade-off between precision and recall is observed as well as a significant reduction in false detection rates, especially in noisy environments. To ensure reproducibility, we provide our database of labelled clicks along with our implementation code.
GPS-Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis
Dec 04, 2023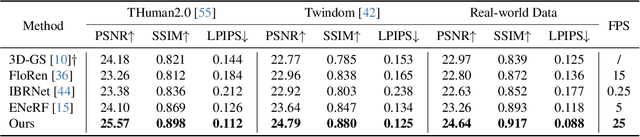
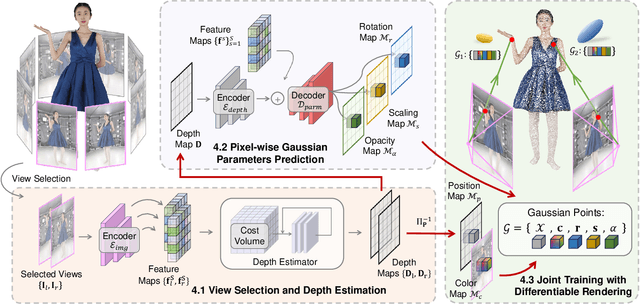
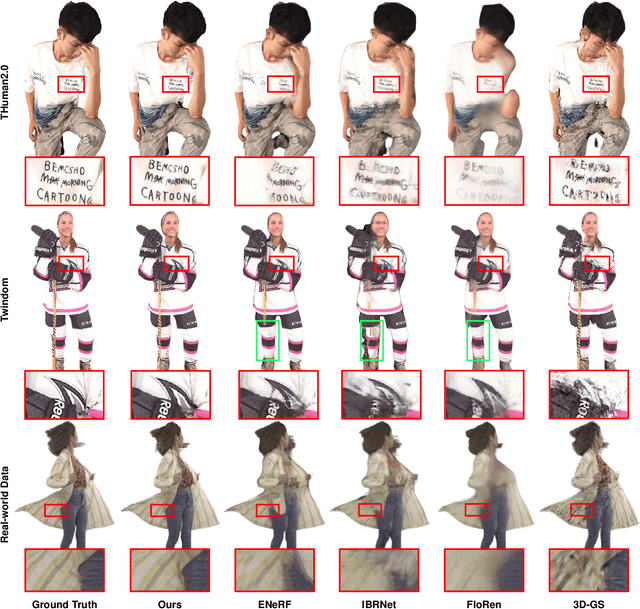
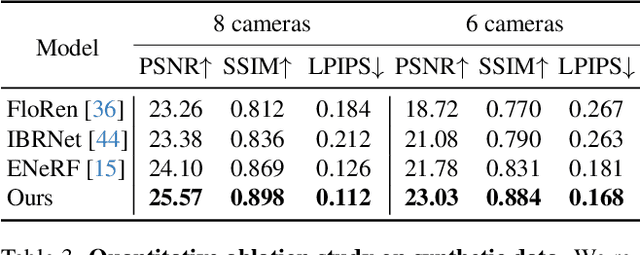
We present a new approach, termed GPS-Gaussian, for synthesizing novel views of a character in a real-time manner. The proposed method enables 2K-resolution rendering under a sparse-view camera setting. Unlike the original Gaussian Splatting or neural implicit rendering methods that necessitate per-subject optimizations, we introduce Gaussian parameter maps defined on the source views and regress directly Gaussian Splatting properties for instant novel view synthesis without any fine-tuning or optimization. To this end, we train our Gaussian parameter regression module on a large amount of human scan data, jointly with a depth estimation module to lift 2D parameter maps to 3D space. The proposed framework is fully differentiable and experiments on several datasets demonstrate that our method outperforms state-of-the-art methods while achieving an exceeding rendering speed.
Investigating the Effects of Sparse Attention on Cross-Encoders
Dec 29, 2023Cross-encoders are effective passage and document re-rankers but less efficient than other neural or classic retrieval models. A few previous studies have applied windowed self-attention to make cross-encoders more efficient. However, these studies did not investigate the potential and limits of different attention patterns or window sizes. We close this gap and systematically analyze how token interactions can be reduced without harming the re-ranking effectiveness. Experimenting with asymmetric attention and different window sizes, we find that the query tokens do not need to attend to the passage or document tokens for effective re-ranking and that very small window sizes suffice. In our experiments, even windows of 4 tokens still yield effectiveness on par with previous cross-encoders while reducing the memory requirements to at most 78% / 41% and being 1% / 43% faster at inference time for passages / documents.
Exact Consistency Tests for Gaussian Mixture Filters using Normalized Deviation Squared Statistics
Dec 29, 2023We consider the problem of evaluating dynamic consistency in discrete time probabilistic filters that approximate stochastic system state densities with Gaussian mixtures. Dynamic consistency means that the estimated probability distributions correctly describe the actual uncertainties. As such, the problem of consistency testing naturally arises in applications with regards to estimator tuning and validation. However, due to the general complexity of the density functions involved, straightforward approaches for consistency testing of mixture-based estimators have remained challenging to define and implement. This paper derives a new exact result for Gaussian mixture consistency testing within the framework of normalized deviation squared (NDS) statistics. It is shown that NDS test statistics for generic multivariate Gaussian mixture models exactly follow mixtures of generalized chi-square distributions, for which efficient computational tools are available. The accuracy and utility of the resulting consistency tests are numerically demonstrated on static and dynamic mixture estimation examples.
ARTrackV2: Prompting Autoregressive Tracker Where to Look and How to Describe
Dec 29, 2023We present ARTrackV2, which integrates two pivotal aspects of tracking: determining where to look (localization) and how to describe (appearance analysis) the target object across video frames. Building on the foundation of its predecessor, ARTrackV2 extends the concept by introducing a unified generative framework to "read out" object's trajectory and "retell" its appearance in an autoregressive manner. This approach fosters a time-continuous methodology that models the joint evolution of motion and visual features, guided by previous estimates. Furthermore, ARTrackV2 stands out for its efficiency and simplicity, obviating the less efficient intra-frame autoregression and hand-tuned parameters for appearance updates. Despite its simplicity, ARTrackV2 achieves state-of-the-art performance on prevailing benchmark datasets while demonstrating remarkable efficiency improvement. In particular, ARTrackV2 achieves AO score of 79.5\% on GOT-10k, and AUC of 86.1\% on TrackingNet while being $3.6 \times$ faster than ARTrack. The code will be released.
SparseGS: Real-Time 360° Sparse View Synthesis using Gaussian Splatting
Nov 30, 2023The problem of novel view synthesis has grown significantly in popularity recently with the introduction of Neural Radiance Fields (NeRFs) and other implicit scene representation methods. A recent advance, 3D Gaussian Splatting (3DGS), leverages an explicit representation to achieve real-time rendering with high-quality results. However, 3DGS still requires an abundance of training views to generate a coherent scene representation. In few shot settings, similar to NeRF, 3DGS tends to overfit to training views, causing background collapse and excessive floaters, especially as the number of training views are reduced. We propose a method to enable training coherent 3DGS-based radiance fields of 360 scenes from sparse training views. We find that using naive depth priors is not sufficient and integrate depth priors with generative and explicit constraints to reduce background collapse, remove floaters, and enhance consistency from unseen viewpoints. Experiments show that our method outperforms base 3DGS by up to 30.5% and NeRF-based methods by up to 15.6% in LPIPS on the MipNeRF-360 dataset with substantially less training and inference cost.