 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
$μ$GUIDE: a framework for microstructure imaging via generalized uncertainty-driven inference using deep learning
Dec 28, 2023
This work proposes $\mu$GUIDE: a general Bayesian framework to estimate posterior distributions of tissue microstructure parameters from any given biophysical model or MRI signal representation, with exemplar demonstration in diffusion-weighted MRI. Harnessing a new deep learning architecture for automatic signal feature selection combined with simulation-based inference and efficient sampling of the posterior distributions, $\mu$GUIDE bypasses the high computational and time cost of conventional Bayesian approaches and does not rely on acquisition constraints to define model-specific summary statistics. The obtained posterior distributions allow to highlight degeneracies present in the model definition and quantify the uncertainty and ambiguity of the estimated parameters.
Explainability-Based Adversarial Attack on Graphs Through Edge Perturbation
Dec 28, 2023Despite the success of graph neural networks (GNNs) in various domains, they exhibit susceptibility to adversarial attacks. Understanding these vulnerabilities is crucial for developing robust and secure applications. In this paper, we investigate the impact of test time adversarial attacks through edge perturbations which involve both edge insertions and deletions. A novel explainability-based method is proposed to identify important nodes in the graph and perform edge perturbation between these nodes. The proposed method is tested for node classification with three different architectures and datasets. The results suggest that introducing edges between nodes of different classes has higher impact as compared to removing edges among nodes within the same class.
RIDE: Real-time Intrusion Detection via Explainable Machine Learning Implemented in a Memristor Hardware Architecture
Nov 27, 2023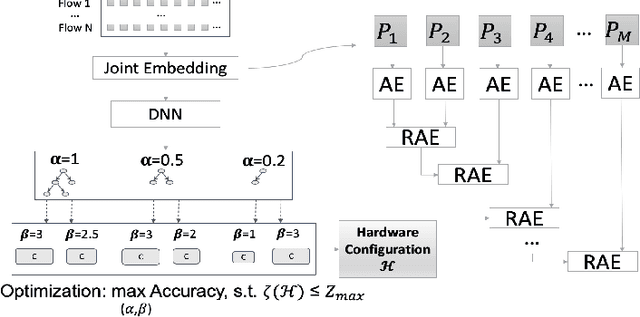
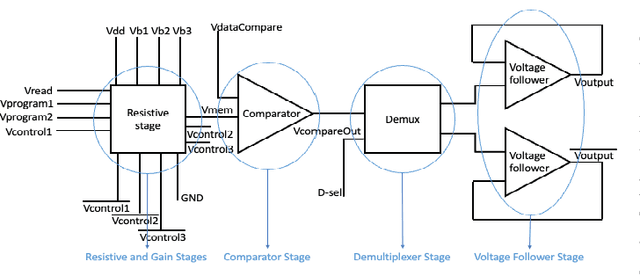
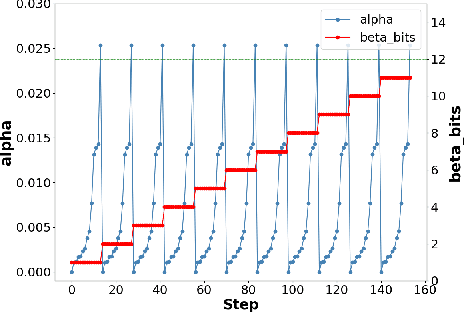
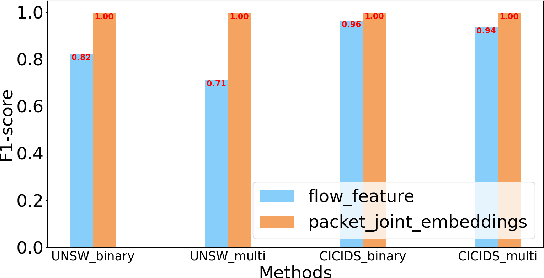
Deep Learning (DL) based methods have shown great promise in network intrusion detection by identifying malicious network traffic behavior patterns with high accuracy, but their applications to real-time, packet-level detections in high-speed communication networks are challenging due to the high computation time and resource requirements of Deep Neural Networks (DNNs), as well as lack of explainability. To this end, we propose a packet-level network intrusion detection solution that makes novel use of Recurrent Autoencoders to integrate an arbitrary-length sequence of packets into a more compact joint feature embedding, which is fed into a DNN-based classifier. To enable explainability and support real-time detections at micro-second speed, we further develop a Software-Hardware Co-Design approach to efficiently realize the proposed solution by converting the learned detection policies into decision trees and implementing them using an emerging architecture based on memristor devices. By jointly optimizing associated software and hardware constraints, we show that our approach leads to an extremely efficient, real-time solution with high detection accuracy at the packet level. Evaluation results on real-world datasets (e.g., UNSW and CIC-IDS datasets) demonstrate nearly three-nines detection accuracy with a substantial speedup of nearly four orders of magnitude.
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Dec 01, 2023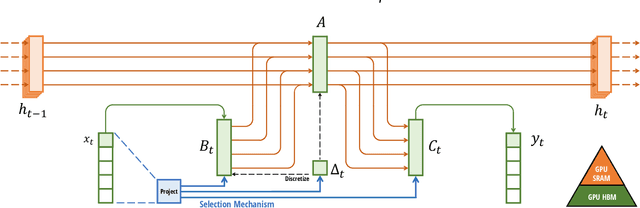
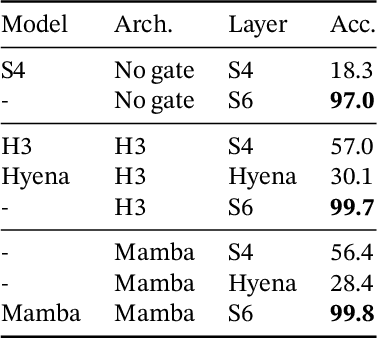
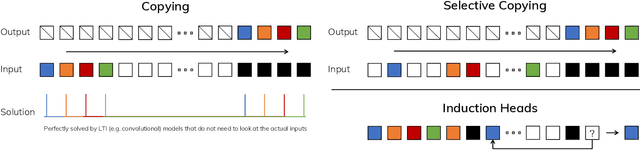
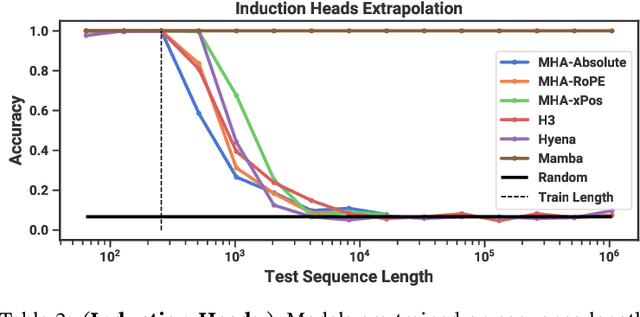
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5$\times$ higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
FSGS: Real-Time Few-shot View Synthesis using Gaussian Splatting
Dec 01, 2023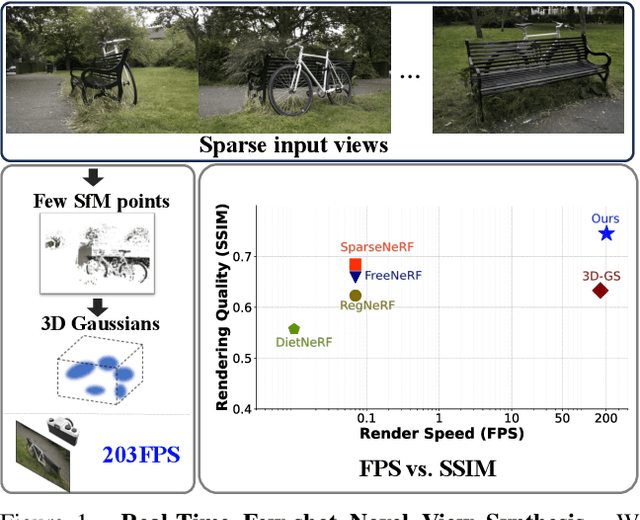
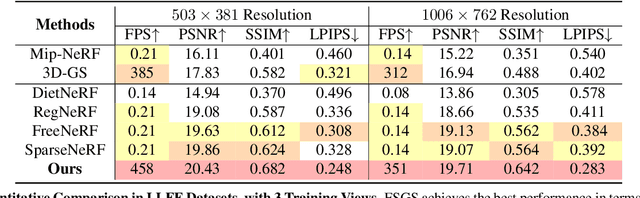
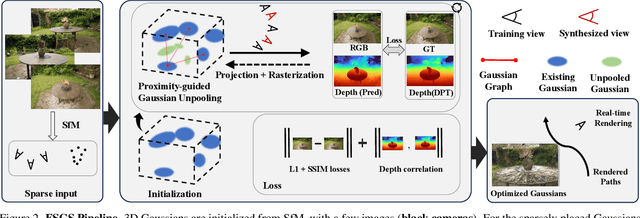
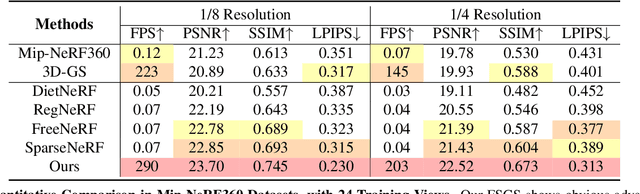
Novel view synthesis from limited observations remains an important and persistent task. However, high efficiency in existing NeRF-based few-shot view synthesis is often compromised to obtain an accurate 3D representation. To address this challenge, we propose a few-shot view synthesis framework based on 3D Gaussian Splatting that enables real-time and photo-realistic view synthesis with as few as three training views. The proposed method, dubbed FSGS, handles the extremely sparse initialized SfM points with a thoughtfully designed Gaussian Unpooling process. Our method iteratively distributes new Gaussians around the most representative locations, subsequently infilling local details in vacant areas. We also integrate a large-scale pre-trained monocular depth estimator within the Gaussians optimization process, leveraging online augmented views to guide the geometric optimization towards an optimal solution. Starting from sparse points observed from limited input viewpoints, our FSGS can accurately grow into unseen regions, comprehensively covering the scene and boosting the rendering quality of novel views. Overall, FSGS achieves state-of-the-art performance in both accuracy and rendering efficiency across diverse datasets, including LLFF, Mip-NeRF360, and Blender. Project website: https://zehaozhu.github.io/FSGS/.
HybridGait: A Benchmark for Spatial-Temporal Cloth-Changing Gait Recognition with Hybrid Explorations
Dec 30, 2023Existing gait recognition benchmarks mostly include minor clothing variations in the laboratory environments, but lack persistent changes in appearance over time and space. In this paper, we propose the first in-the-wild benchmark CCGait for cloth-changing gait recognition, which incorporates diverse clothing changes, indoor and outdoor scenes, and multi-modal statistics over 92 days. To further address the coupling effect of clothing and viewpoint variations, we propose a hybrid approach HybridGait that exploits both temporal dynamics and the projected 2D information of 3D human meshes. Specifically, we introduce a Canonical Alignment Spatial-Temporal Transformer (CA-STT) module to encode human joint position-aware features, and fully exploit 3D dense priors via a Silhouette-guided Deformation with 3D-2D Appearance Projection (SilD) strategy. Our contributions are twofold: we provide a challenging benchmark CCGait that captures realistic appearance changes across an expanded and space, and we propose a hybrid framework HybridGait that outperforms prior works on CCGait and Gait3D benchmarks. Our project page is available at https://github.com/HCVLab/HybridGait.
WildGEN: Long-horizon Trajectory Generation for Wildlife
Dec 30, 2023Trajectory generation is an important concern in pedestrian, vehicle, and wildlife movement studies. Generated trajectories help enrich the training corpus in relation to deep learning applications, and may be used to facilitate simulation tasks. This is especially significant in the wildlife domain, where the cost of obtaining additional real data can be prohibitively expensive, time-consuming, and bear ethical considerations. In this paper, we introduce WildGEN: a conceptual framework that addresses this challenge by employing a Variational Auto-encoders (VAEs) based method for the acquisition of movement characteristics exhibited by wild geese over a long horizon using a sparse set of truth samples. A subsequent post-processing step of the generated trajectories is performed based on smoothing filters to reduce excessive wandering. Our evaluation is conducted through visual inspection and the computation of the Hausdorff distance between the generated and real trajectories. In addition, we utilize the Pearson Correlation Coefficient as a way to measure how realistic the trajectories are based on the similarity of clusters evaluated on the generated and real trajectories.
Inherently Interpretable Time Series Classification via Multiple Instance Learning
Nov 23, 2023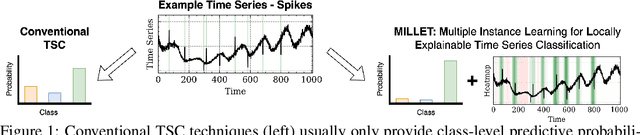

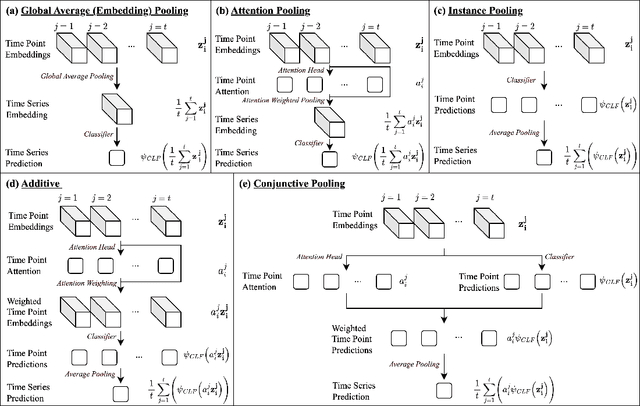
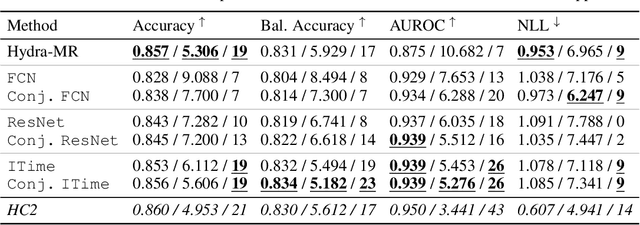
Conventional Time Series Classification (TSC) methods are often black boxes that obscure inherent interpretation of their decision-making processes. In this work, we leverage Multiple Instance Learning (MIL) to overcome this issue, and propose a new framework called MILLET: Multiple Instance Learning for Locally Explainable Time series classification. We apply MILLET to existing deep learning TSC models and show how they become inherently interpretable without compromising (and in some cases, even improving) predictive performance. We evaluate MILLET on 85 UCR TSC datasets and also present a novel synthetic dataset that is specially designed to facilitate interpretability evaluation. On these datasets, we show MILLET produces sparse explanations quickly that are of higher quality than other well-known interpretability methods. To the best of our knowledge, our work with MILLET, which is available on GitHub (https://github.com/JAEarly/MILTimeSeriesClassification), is the first to develop general MIL methods for TSC and apply them to an extensive variety of domains
Integrating Edges into U-Net Models with Explainable Activation Maps for Brain Tumor Segmentation using MR Images
Jan 02, 2024Manual delineation of tumor regions from magnetic resonance (MR) images is time-consuming, requires an expert, and is prone to human error. In recent years, deep learning models have been the go-to approach for the segmentation of brain tumors. U-Net and its' variants for semantic segmentation of medical images have achieved good results in the literature. However, U-Net and its' variants tend to over-segment tumor regions and may not accurately segment the tumor edges. The edges of the tumor are as important as the tumor regions for accurate diagnosis, surgical precision, and treatment planning. In the proposed work, the authors aim to extract edges from the ground truth using a derivative-like filter followed by edge reconstruction to obtain an edge ground truth in addition to the brain tumor ground truth. Utilizing both ground truths, the author studies several U-Net and its' variant architectures with and without tumor edges ground truth as a target along with the tumor ground truth for brain tumor segmentation. The author used the BraTS2020 benchmark dataset to perform the study and the results are tabulated for the dice and Hausdorff95 metrics. The mean and median metrics are calculated for the whole tumor (WT), tumor core (TC), and enhancing tumor (ET) regions. Compared to the baseline U-Net and its variants, the models that learned edges along with the tumor regions performed well in core tumor regions in both training and validation datasets. The improved performance of edge-trained models trained on baseline models like U-Net and V-Net achieved performance similar to baseline state-of-the-art models like Swin U-Net and hybrid MR-U-Net. The edge-target trained models are capable of generating edge maps that can be useful for treatment planning. Additionally, for further explainability of the results, the activation map generated by the hybrid MR-U-Net has been studied.
MossFormer2: Combining Transformer and RNN-Free Recurrent Network for Enhanced Time-Domain Monaural Speech Separation
Dec 19, 2023Our previously proposed MossFormer has achieved promising performance in monaural speech separation. However, it predominantly adopts a self-attention-based MossFormer module, which tends to emphasize longer-range, coarser-scale dependencies, with a deficiency in effectively modelling finer-scale recurrent patterns. In this paper, we introduce a novel hybrid model that provides the capabilities to model both long-range, coarse-scale dependencies and fine-scale recurrent patterns by integrating a recurrent module into the MossFormer framework. Instead of applying the recurrent neural networks (RNNs) that use traditional recurrent connections, we present a recurrent module based on a feedforward sequential memory network (FSMN), which is considered "RNN-free" recurrent network due to the ability to capture recurrent patterns without using recurrent connections. Our recurrent module mainly comprises an enhanced dilated FSMN block by using gated convolutional units (GCU) and dense connections. In addition, a bottleneck layer and an output layer are also added for controlling information flow. The recurrent module relies on linear projections and convolutions for seamless, parallel processing of the entire sequence. The integrated MossFormer2 hybrid model demonstrates remarkable enhancements over MossFormer and surpasses other state-of-the-art methods in WSJ0-2/3mix, Libri2Mix, and WHAM!/WHAMR! benchmarks.