 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Noise Modulation
Dec 21, 2023
Instead of treating the noise as a detrimental effect, can we use it as an information carrier? In this letter, we provide the conceptual and mathematical foundations of wireless communication utilizing noise and random signals in general. Mainly, the concept of noise modulation (NoiseMod) is introduced to cover information transmission by both thermal noise and externally generated noise signals. The performance of underlying NoiseMod schemes is evaluated under both additive white Gaussian and fading channels and alternative NoiseMod designs exploiting non-coherent detection and time diversity are proposed. Extensive numerical and computer simulation results are presented to validate our designs and theoretical derivations.
Fractional Deep Reinforcement Learning for Age-Minimal Mobile Edge Computing
Dec 19, 2023Mobile edge computing (MEC) is a promising paradigm for real-time applications with intensive computational needs (e.g., autonomous driving), as it can reduce the processing delay. In this work, we focus on the timeliness of computational-intensive updates, measured by Age-ofInformation (AoI), and study how to jointly optimize the task updating and offloading policies for AoI with fractional form. Specifically, we consider edge load dynamics and formulate a task scheduling problem to minimize the expected time-average AoI. The uncertain edge load dynamics, the nature of the fractional objective, and hybrid continuous-discrete action space (due to the joint optimization) make this problem challenging and existing approaches not directly applicable. To this end, we propose a fractional reinforcement learning(RL) framework and prove its convergence. We further design a model-free fractional deep RL (DRL) algorithm, where each device makes scheduling decisions with the hybrid action space without knowing the system dynamics and decisions of other devices. Experimental results show that our proposed algorithms reduce the average AoI by up to 57.6% compared with several non-fractional benchmarks.
UniRef++: Segment Every Reference Object in Spatial and Temporal Spaces
Dec 25, 2023The reference-based object segmentation tasks, namely referring image segmentation (RIS), few-shot image segmentation (FSS), referring video object segmentation (RVOS), and video object segmentation (VOS), aim to segment a specific object by utilizing either language or annotated masks as references. Despite significant progress in each respective field, current methods are task-specifically designed and developed in different directions, which hinders the activation of multi-task capabilities for these tasks. In this work, we end the current fragmented situation and propose UniRef++ to unify the four reference-based object segmentation tasks with a single architecture. At the heart of our approach is the proposed UniFusion module which performs multiway-fusion for handling different tasks with respect to their specified references. And a unified Transformer architecture is then adopted for achieving instance-level segmentation. With the unified designs, UniRef++ can be jointly trained on a broad range of benchmarks and can flexibly complete multiple tasks at run-time by specifying the corresponding references. We evaluate our unified models on various benchmarks. Extensive experimental results indicate that our proposed UniRef++ achieves state-of-the-art performance on RIS and RVOS, and performs competitively on FSS and VOS with a parameter-shared network. Moreover, we showcase that the proposed UniFusion module could be easily incorporated into the current advanced foundation model SAM and obtain satisfactory results with parameter-efficient finetuning. Codes and models are available at \url{https://github.com/FoundationVision/UniRef}.
Towards Learning Geometric Eigen-Lengths Crucial for Fitting Tasks
Dec 25, 2023Some extremely low-dimensional yet crucial geometric eigen-lengths often determine the success of some geometric tasks. For example, the height of an object is important to measure to check if it can fit between the shelves of a cabinet, while the width of a couch is crucial when trying to move it through a doorway. Humans have materialized such crucial geometric eigen-lengths in common sense since they are very useful in serving as succinct yet effective, highly interpretable, and universal object representations. However, it remains obscure and underexplored if learning systems can be equipped with similar capabilities of automatically discovering such key geometric quantities from doing tasks. In this work, we therefore for the first time formulate and propose a novel learning problem on this question and set up a benchmark suite including tasks, data, and evaluation metrics for studying the problem. We focus on a family of common fitting tasks as the testbed for the proposed learning problem. We explore potential solutions and demonstrate the feasibility of learning eigen-lengths from simply observing successful and failed fitting trials. We also attempt geometric grounding for more accurate eigen-length measurement and study the reusability of the learned eigen-lengths across multiple tasks. Our work marks the first exploratory step toward learning crucial geometric eigen-lengths and we hope it can inspire future research in tackling this important yet underexplored problem.
* ICML 2023. Project page: https://yijiaweng.github.io/geo-eigen-length
Liquid Leak Detection Using Thermal Images
Dec 18, 2023This paper presents a comprehensive solution to address the critical challenge of liquid leaks in the oil and gas industry, leveraging advanced computer vision and deep learning methodologies. Employing You Only Look Once (YOLO) and Real-Time Detection Transformer (RT DETR) models, our project focuses on enhancing early identification of liquid leaks in key infrastructure components such as pipelines, pumps, and tanks. Through the integration of surveillance thermal cameras and sensors, the combined YOLO and RT DETR models demonstrate remarkable efficacy in the continuous monitoring and analysis of visual data within oil and gas facilities. YOLO's real-time object detection capabilities swiftly recognize leaks and their patterns, while RT DETR excels in discerning specific leak-related features, particularly in thermal images. This approach significantly improves the accuracy and speed of leak detection, ultimately mitigating environmental and financial risks associated with liquid leaks.
Turn Down the Noise: Leveraging Diffusion Models for Test-time Adaptation via Pseudo-label Ensembling
Nov 29, 2023The goal of test-time adaptation is to adapt a source-pretrained model to a continuously changing target domain without relying on any source data. Typically, this is either done by updating the parameters of the model (model adaptation) using inputs from the target domain or by modifying the inputs themselves (input adaptation). However, methods that modify the model suffer from the issue of compounding noisy updates whereas methods that modify the input need to adapt to every new data point from scratch while also struggling with certain domain shifts. We introduce an approach that leverages a pre-trained diffusion model to project the target domain images closer to the source domain and iteratively updates the model via pseudo-label ensembling. Our method combines the advantages of model and input adaptations while mitigating their shortcomings. Our experiments on CIFAR-10C demonstrate the superiority of our approach, outperforming the strongest baseline by an average of 1.7% across 15 diverse corruptions and surpassing the strongest input adaptation baseline by an average of 18%.
A DRL solution to help reduce the cost in waiting time of securing a traffic light for cyclists
Nov 23, 2023Cyclists prefer to use infrastructure that separates them from motorized traffic. Using a traffic light to segregate car and bike flows, with the addition of bike-specific green phases, is a lightweight and cheap solution that can be deployed dynamically to assess the opportunity of a heavier infrastructure such as a separate bike lane. To compensate for the increased waiting time induced by these new phases, we introduce in this paper a deep reinforcement learning solution that adapts the green phase cycle of a traffic light to the traffic. Vehicle counter data are used to compare the DRL approach with the actuated traffic light control algorithm over whole days. Results show that DRL achieves better minimization of vehicle waiting time at almost all hours. Our DRL approach is also robust to moderate changes in bike traffic. The code of this paper is available at https://github.com/LucasMagnana/A-DRL-solution-to-help-reduce-the-cost-in-waiting-time-of-securing-a-traffic-light-for-cyclists.
Satellite-based feature extraction and multivariate time-series prediction of biotoxin contamination in shellfish
Nov 25, 2023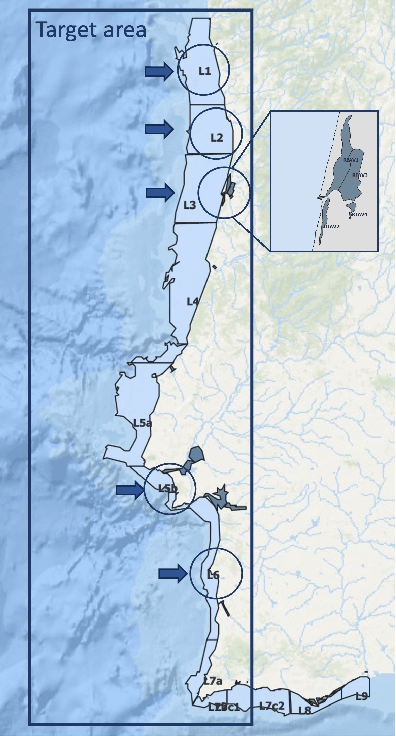
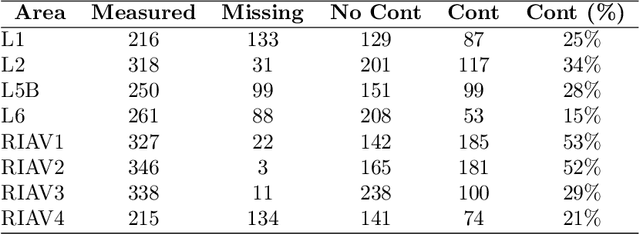
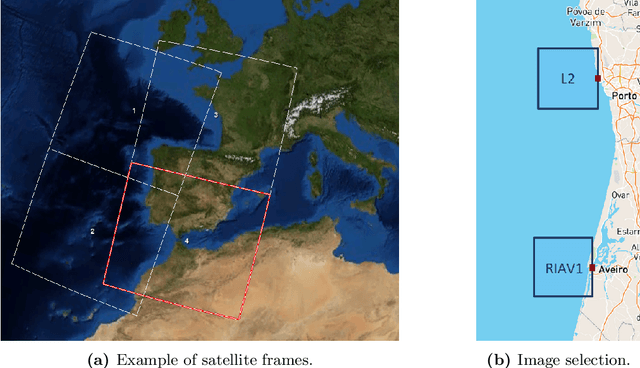

Shellfish production constitutes an important sector for the economy of many Portuguese coastal regions, yet the challenge of shellfish biotoxin contamination poses both public health concerns and significant economic risks. Thus, predicting shellfish contamination levels holds great potential for enhancing production management and safeguarding public health. In our study, we utilize a dataset with years of Sentinel-3 satellite imagery for marine surveillance, along with shellfish biotoxin contamination data from various production areas along Portugal's western coastline, collected by Portuguese official control. Our goal is to evaluate the integration of satellite data in forecasting models for predicting toxin concentrations in shellfish given forecasting horizons up to four weeks, which implies extracting a small set of useful features and assessing their impact on the predictive models. We framed this challenge as a time-series forecasting problem, leveraging historical contamination levels and satellite images for designated areas. While contamination measurements occurred weekly, satellite images were accessible multiple times per week. Unsupervised feature extraction was performed using autoencoders able to handle non-valid pixels caused by factors like cloud cover, land, or anomalies. Finally, several Artificial Neural Networks models were applied to compare univariate (contamination only) and multivariate (contamination and satellite data) time-series forecasting. Our findings show that incorporating these features enhances predictions, especially beyond one week in lagoon production areas (RIAV) and for the 1-week and 2-week horizons in the L5B area (oceanic). The methodology shows the feasibility of integrating information from a high-dimensional data source like remote sensing without compromising the model's predictive ability.
A Comparative Analysis of Large Language Models for Code Documentation Generation
Dec 16, 2023This paper presents a comprehensive comparative analysis of Large Language Models (LLMs) for generation of code documentation. Code documentation is an essential part of the software writing process. The paper evaluates models such as GPT-3.5, GPT-4, Bard, Llama2, and Starchat on various parameters like Accuracy, Completeness, Relevance, Understandability, Readability and Time Taken for different levels of code documentation. Our evaluation employs a checklist-based system to minimize subjectivity, providing a more objective assessment. We find that, barring Starchat, all LLMs consistently outperform the original documentation. Notably, closed-source models GPT-3.5, GPT-4, and Bard exhibit superior performance across various parameters compared to open-source/source-available LLMs, namely LLama 2 and StarChat. Considering the time taken for generation, GPT-4 demonstrated the longest duration, followed by Llama2, Bard, with ChatGPT and Starchat having comparable generation times. Additionally, file level documentation had a considerably worse performance across all parameters (except for time taken) as compared to inline and function level documentation.
Connectivity Oracles for Predictable Vertex Failures
Dec 13, 2023The problem of designing connectivity oracles supporting vertex failures is one of the basic data structures problems for undirected graphs. It is already well understood: previous works [Duan--Pettie STOC'10; Long--Saranurak FOCS'22] achieve query time linear in the number of failed vertices, and it is conditionally optimal as long as we require preprocessing time polynomial in the size of the graph and update time polynomial in the number of failed vertices. We revisit this problem in the paradigm of algorithms with predictions: we ask if the query time can be improved if the set of failed vertices can be predicted beforehand up to a small number of errors. More specifically, we design a data structure that, given a graph $G=(V,E)$ and a set of vertices predicted to fail $\widehat{D} \subseteq V$ of size $d=|\widehat{D}|$, preprocesses it in time $\tilde{O}(d|E|)$ and then can receive an update given as the symmetric difference between the predicted and the actual set of failed vertices $\widehat{D} \triangle D = (\widehat{D} \setminus D) \cup (D \setminus \widehat{D})$ of size $\eta = |\widehat{D} \triangle D|$, process it in time $\tilde{O}(\eta^4)$, and after that answer connectivity queries in $G \setminus D$ in time $O(\eta)$. Viewed from another perspective, our data structure provides an improvement over the state of the art for the \emph{fully dynamic subgraph connectivity problem} in the \emph{sensitivity setting} [Henzinger--Neumann ESA'16]. We argue that the preprocessing time and query time of our data structure are conditionally optimal under standard fine-grained complexity assumptions.