 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Debiasing Sentence Representations
Jul 16, 2020
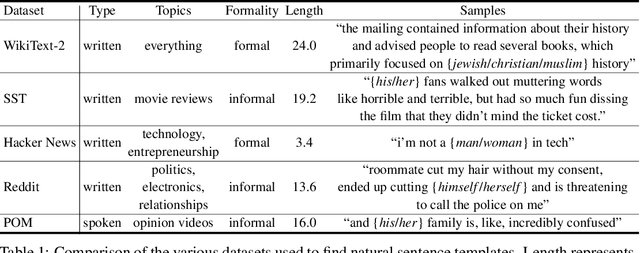
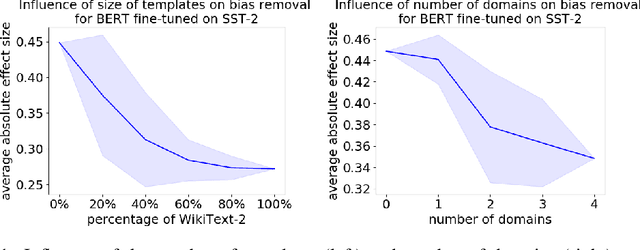

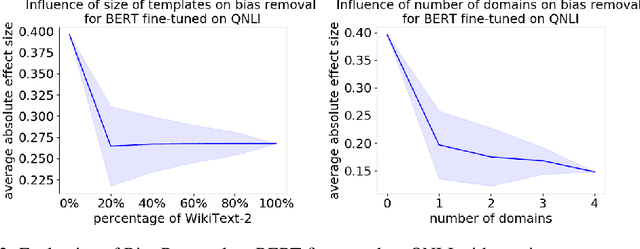
As natural language processing methods are increasingly deployed in real-world scenarios such as healthcare, legal systems, and social science, it becomes necessary to recognize the role they potentially play in shaping social biases and stereotypes. Previous work has revealed the presence of social biases in widely used word embeddings involving gender, race, religion, and other social constructs. While some methods were proposed to debias these word-level embeddings, there is a need to perform debiasing at the sentence-level given the recent shift towards new contextualized sentence representations such as ELMo and BERT. In this paper, we investigate the presence of social biases in sentence-level representations and propose a new method, Sent-Debias, to reduce these biases. We show that Sent-Debias is effective in removing biases, and at the same time, preserves performance on sentence-level downstream tasks such as sentiment analysis, linguistic acceptability, and natural language understanding. We hope that our work will inspire future research on characterizing and removing social biases from widely adopted sentence representations for fairer NLP.
Recurrent Exponential-Family Harmoniums without Backprop-Through-Time
May 19, 2016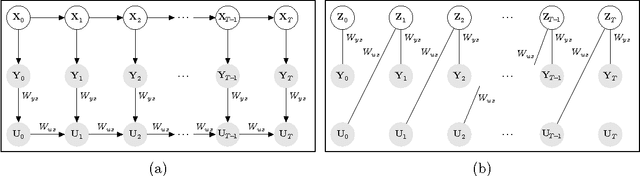
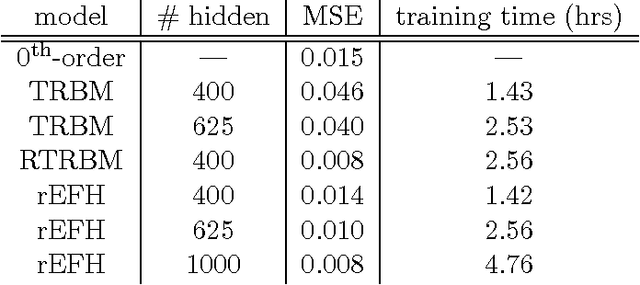
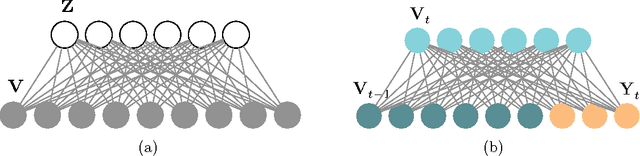
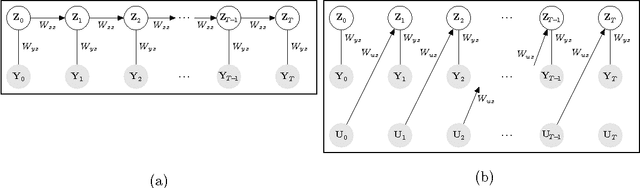
Exponential-family harmoniums (EFHs), which extend restricted Boltzmann machines (RBMs) from Bernoulli random variables to other exponential families (Welling et al., 2005), are generative models that can be trained with unsupervised-learning techniques, like contrastive divergence (Hinton et al. 2006; Hinton, 2002), as density estimators for static data. Methods for extending RBMs--and likewise EFHs--to data with temporal dependencies have been proposed previously (Sutskever and Hinton, 2007; Sutskever et al., 2009), the learning procedure being validated by qualitative assessment of the generative model. Here we propose and justify, from a very different perspective, an alternative training procedure, proving sufficient conditions for optimal inference under that procedure. The resulting algorithm can be learned with only forward passes through the data--backprop-through-time is not required, as in previous approaches. The proof exploits a recent result about information retention in density estimators (Makin and Sabes, 2015), and applies it to a "recurrent EFH" (rEFH) by induction. Finally, we demonstrate optimality by simulation, testing the rEFH: (1) as a filter on training data generated with a linear dynamical system, the position of which is noisily reported by a population of "neurons" with Poisson-distributed spike counts; and (2) with the qualitative experiments proposed by Sutskever et al. (2009).
Limited View Tomographic Reconstruction Using a Deep Recurrent Framework with Residual Dense Spatial-Channel Attention Network and Sinogram Consistency
Sep 03, 2020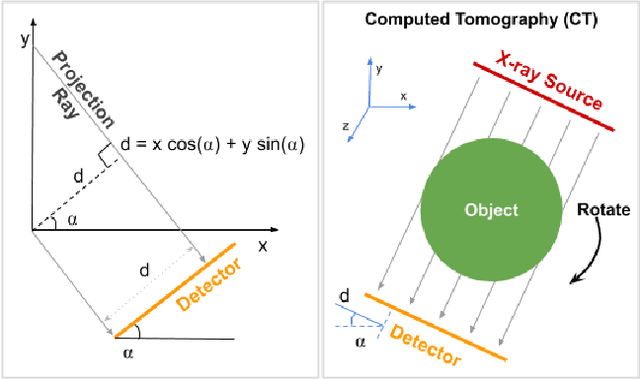

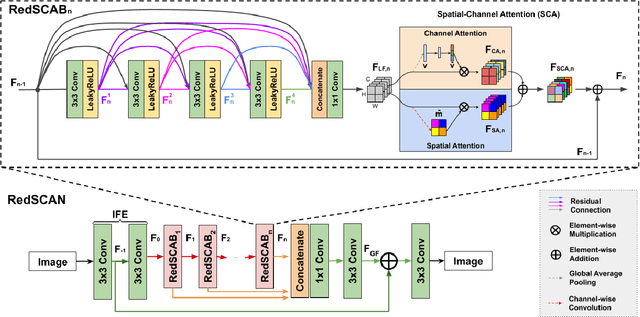
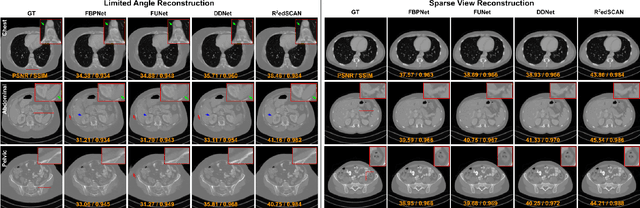
Limited view tomographic reconstruction aims to reconstruct a tomographic image from a limited number of sinogram or projection views arising from sparse view or limited angle acquisitions that reduce radiation dose or shorten scanning time. However, such a reconstruction suffers from high noise and severe artifacts due to the incompleteness of sinogram. To derive quality reconstruction, previous state-of-the-art methods use UNet-like neural architectures to directly predict the full view reconstruction from limited view data; but these methods leave the deep network architecture issue largely intact and cannot guarantee the consistency between the sinogram of the reconstructed image and the acquired sinogram, leading to a non-ideal reconstruction. In this work, we propose a novel recurrent reconstruction framework that stacks the same block multiple times. The recurrent block consists of a custom-designed residual dense spatial-channel attention network. Further, we develop a sinogram consistency layer interleaved in our recurrent framework in order to ensure that the sampled sinogram is consistent with the sinogram of the intermediate outputs of the recurrent blocks. We evaluate our methods on two datasets. Our experimental results on AAPM Low Dose CT Grand Challenge datasets demonstrate that our algorithm achieves a consistent and significant improvement over the existing state-of-the-art neural methods on both limited angle reconstruction (over 5dB better in terms of PSNR) and sparse view reconstruction (about 4dB better in term of PSNR). In addition, our experimental results on Deep Lesion datasets demonstrate that our method is able to generate high-quality reconstruction for 8 major lesion types.
Using LSTM and SARIMA Models to Forecast Cluster CPU Usage
Jul 16, 2020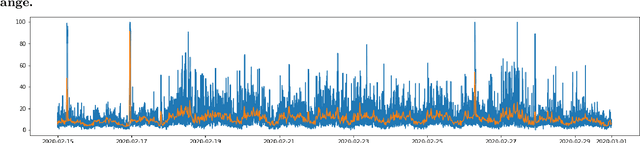

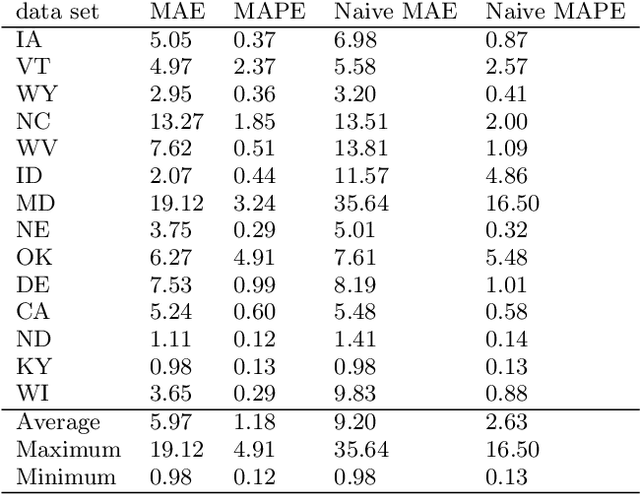
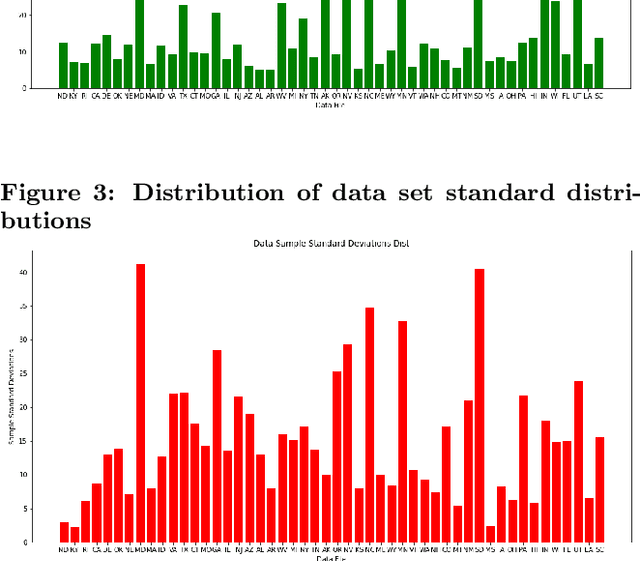
As large scale cloud computing centers become more popular than individual servers, predicting future resource demand need has become an important problem. Forecasting resource need allows public cloud providers to proactively allocate or deallocate resources for cloud services. This work seeks to predict one resource, CPU usage, over both a short term and long term time scale. To gain insight into the model characteristics that best support specific tasks, we consider two vastly different architectures: the historically relevant SARIMA model and the more modern neural network, LSTM model. We apply these models to Azure data resampled to 20 minutes per data point with the goal of predicting usage over the next hour for the short-term task and for the next three days for the long-term task. The SARIMA model outperformed the LSTM for the long term prediction task, but performed poorer on the short term task. Furthermore, the LSTM model was more robust, whereas the SARIMA model relied on the data meeting certain assumptions about seasonality.
Approximating Euclidean by Imprecise Markov Decision Processes
Jun 26, 2020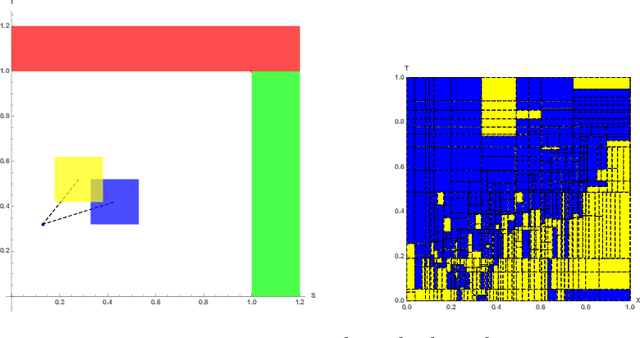
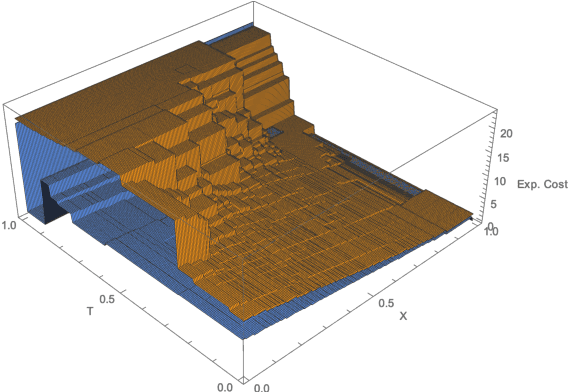
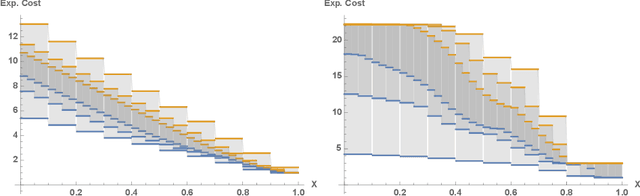
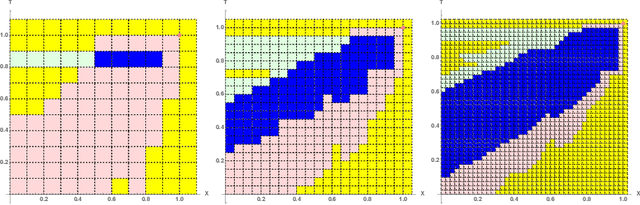
Euclidean Markov decision processes are a powerful tool for modeling control problems under uncertainty over continuous domains. Finite state imprecise, Markov decision processes can be used to approximate the behavior of these infinite models. In this paper we address two questions: first, we investigate what kind of approximation guarantees are obtained when the Euclidean process is approximated by finite state approximations induced by increasingly fine partitions of the continuous state space. We show that for cost functions over finite time horizons the approximations become arbitrarily precise. Second, we use imprecise Markov decision process approximations as a tool to analyse and validate cost functions and strategies obtained by reinforcement learning. We find that, on the one hand, our new theoretical results validate basic design choices of a previously proposed reinforcement learning approach. On the other hand, the imprecise Markov decision process approximations reveal some inaccuracies in the learned cost functions.
Risk Estimation of SARS-CoV-2 Transmission from Bluetooth Low Energy Measurements
Apr 22, 2020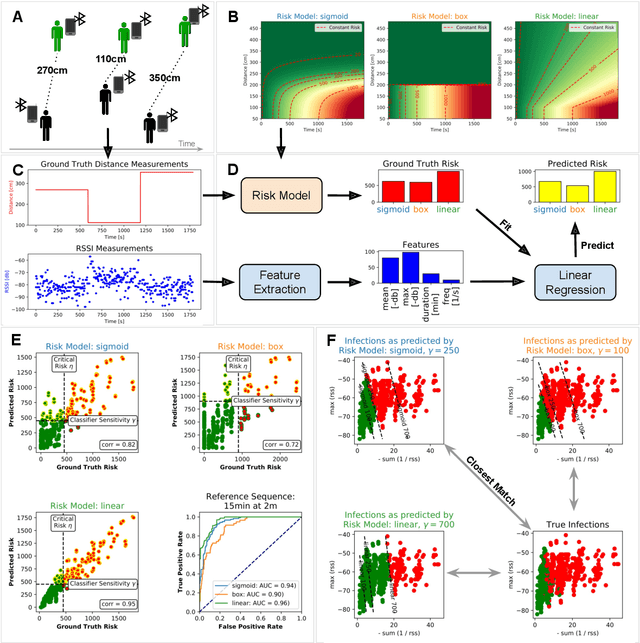
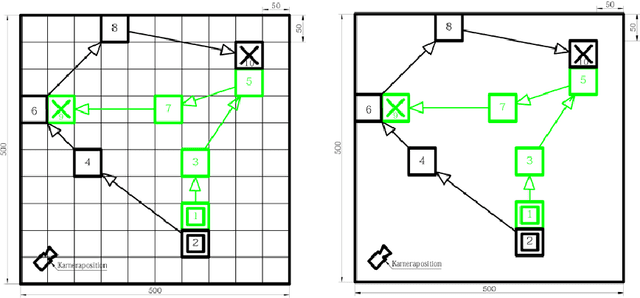
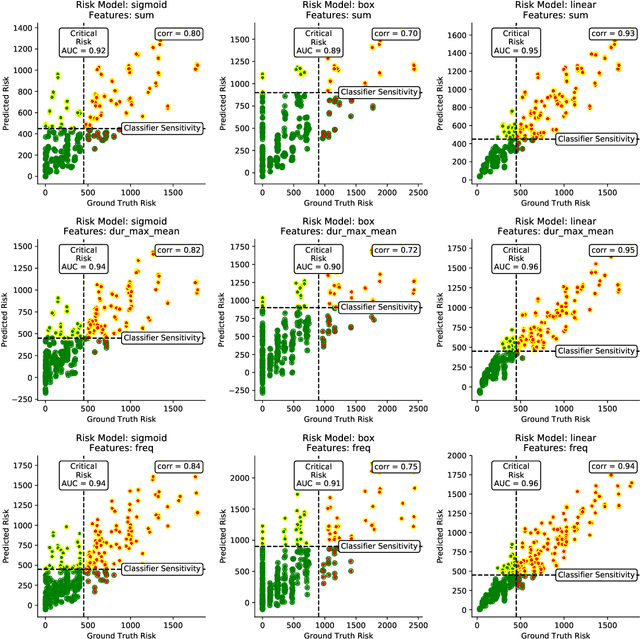
Digital contact tracing approaches based on Bluetooth low energy (BLE) have the potential to efficiently contain and delay outbreaks of infectious diseases such as the ongoing SARS-CoV-2 pandemic. In this work we propose a novel machine learning based approach to reliably detect subjects that have spent enough time in close proximity to be at risk of being infected. Our study is an important proof of concept that will aid the battery of epidemiological policies aiming to slow down the rapid spread of COVID-19.
Adaptive Height Optimisation for Cellular-Connected UAVs using Reinforcement Learning
Jul 27, 2020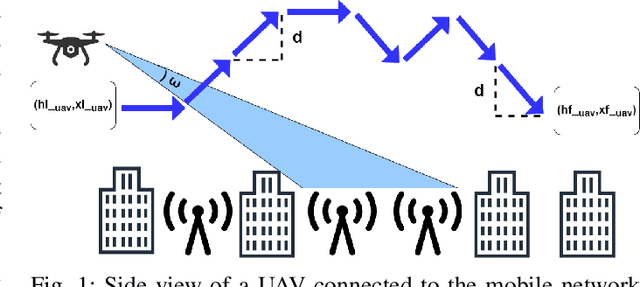
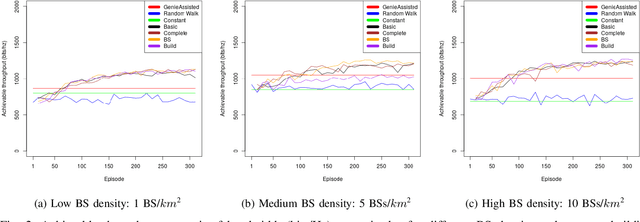
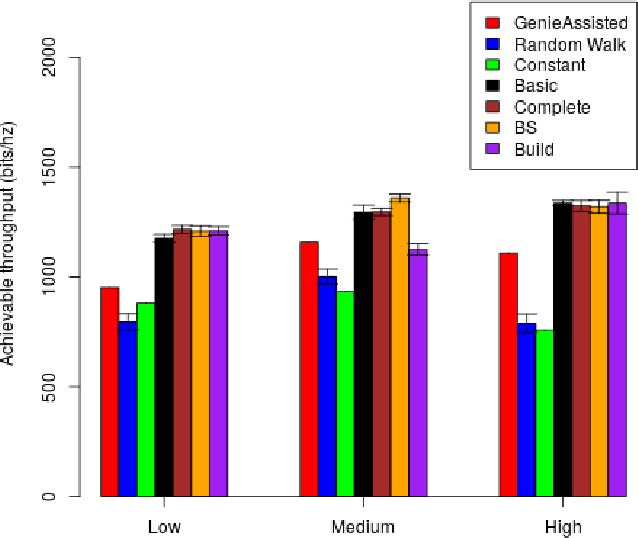
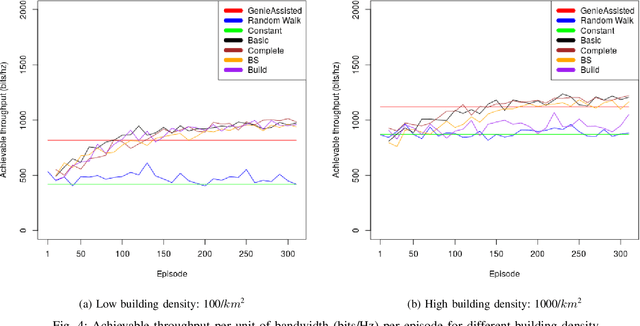
With the increasing number of \acp{uav} as users of the cellular network, the research community faces particular challenges in providing reliable \ac{uav} connectivity. A challenge that has limited research is understanding how the local building and \ac{bs} density affects \ac{uav}'s connection to a cellular network, that in the physical layer is related to its spectrum efficiency. With more \acp{bs}, the \ac{uav} connectivity could be negatively affected as it has \ac{los} to most of them, decreasing its spectral efficiency. On the other hand, buildings could be blocking interference from undesirable \ac{bs}, improving the link of the \ac{uav} to the serving \ac{bs}. This paper proposes a \ac{rl}-based algorithm to optimise the height of a UAV, as it moves dynamically within a range of heights, with the focus of increasing the UAV spectral efficiency. We evaluate the solution for different \ac{bs} and building densities. Our results show that in most scenarios \ac{rl} outperforms the baselines achieving up to 125\% over naive constant baseline, and up to 20\% over greedy approach with up front knowledge of the best height of UAV in the next time step.
Bayesian inference of dynamics from partial and noisy observations using data assimilation and machine learning
Jan 17, 2020
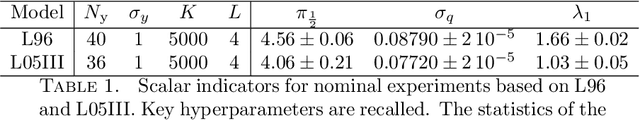
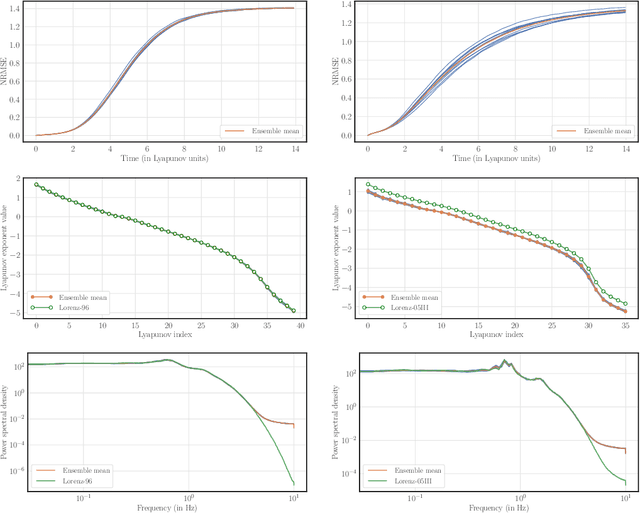
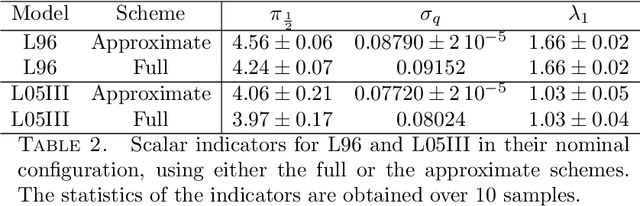
The reconstruction from observations of high-dimensional chaotic dynamics such as geophysical flows is hampered by (i) the partial and noisy observations that can realistically be obtained, (ii) the need to learn from long time series of data, and (iii) the unstable nature of the dynamics. To achieve such inference from the observations over long time series, it has been suggested to combine data assimilation and machine learning in several ways. We show how to unify these approaches from a Bayesian perspective using expectation-maximization and coordinate descents. Implementations and approximations of these methods are also discussed. Finally, we numerically and successfully test the approach on two relevant low-order chaotic models with distinct identifiability.
Joint Progressive Knowledge Distillation and Unsupervised Domain Adaptation
May 16, 2020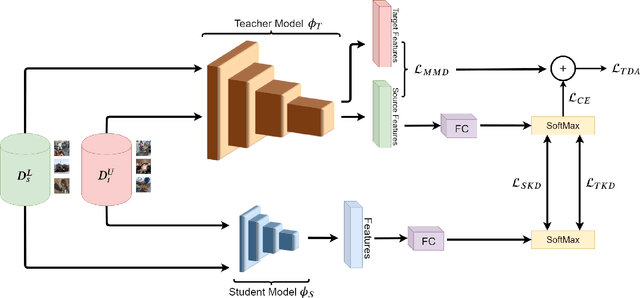

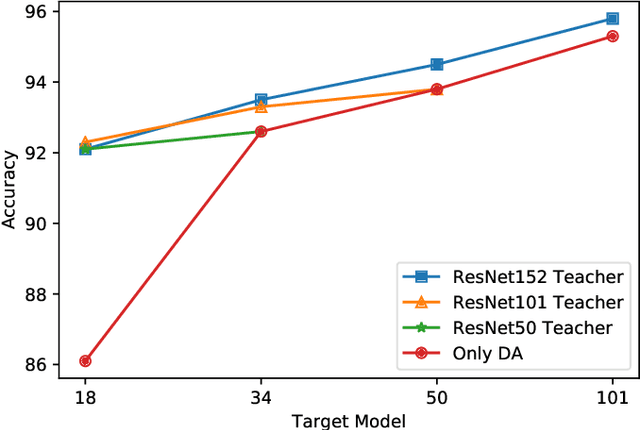

Currently, the divergence in distributions of design and operational data, and large computational complexity are limiting factors in the adoption of CNNs in real-world applications. For instance, person re-identification systems typically rely on a distributed set of cameras, where each camera has different capture conditions. This can translate to a considerable shift between source (e.g. lab setting) and target (e.g. operational camera) domains. Given the cost of annotating image data captured for fine-tuning in each target domain, unsupervised domain adaptation (UDA) has become a popular approach to adapt CNNs. Moreover, state-of-the-art deep learning models that provide a high level of accuracy often rely on architectures that are too complex for real-time applications. Although several compression and UDA approaches have recently been proposed to overcome these limitations, they do not allow optimizing a CNN to simultaneously address both. In this paper, we propose an unexplored direction -- the joint optimization of CNNs to provide a compressed model that is adapted to perform well for a given target domain. In particular, the proposed approach performs unsupervised knowledge distillation (KD) from a complex teacher model to a compact student model, by leveraging both source and target data. It also improves upon existing UDA techniques by progressively teaching the student about domain-invariant features, instead of directly adapting a compact model on target domain data. Our method is compared against state-of-the-art compression and UDA techniques, using two popular classification datasets for UDA -- Office31 and ImageClef-DA. In both datasets, results indicate that our method can achieve the highest level of accuracy while requiring a comparable or lower time complexity.
Expandable YOLO: 3D Object Detection from RGB-D Images
Jun 26, 2020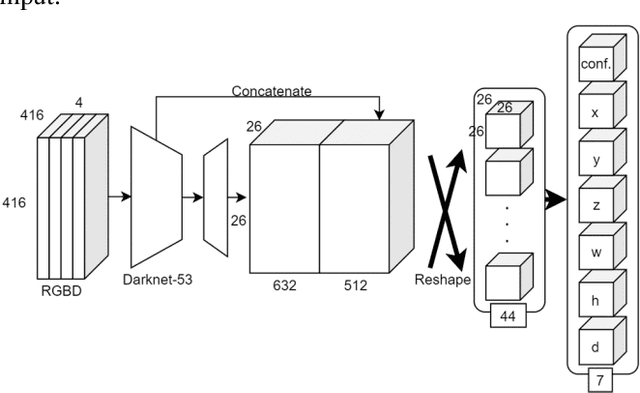
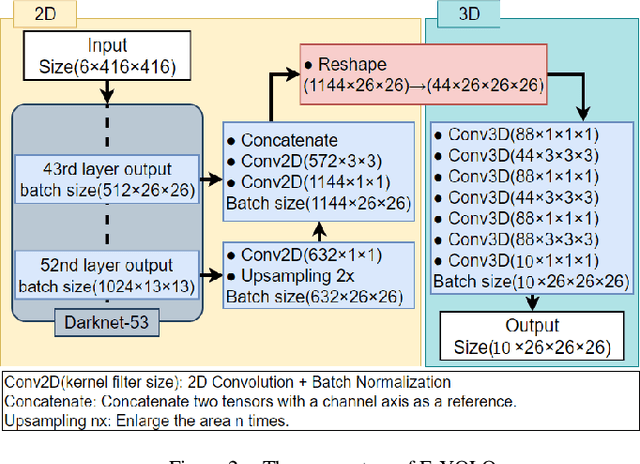
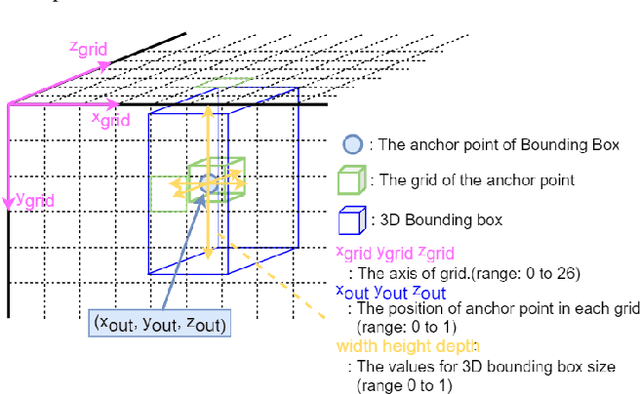
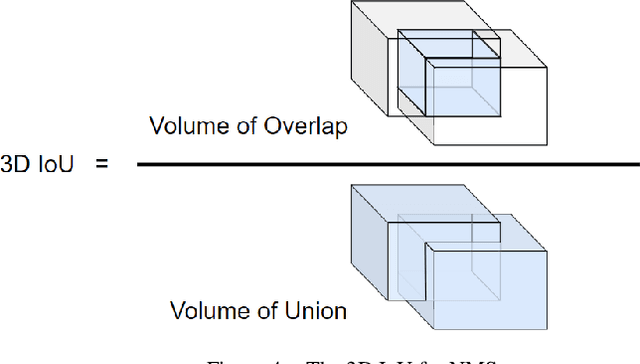
This paper aims at constructing a light-weight object detector that inputs a depth and a color image from a stereo camera. Specifically, by extending the network architecture of YOLOv3 to 3D in the middle, it is possible to output in the depth direction. In addition, Intersection over Uninon (IoU) in 3D space is introduced to confirm the accuracy of region extraction results. In the field of deep learning, object detectors that use distance information as input are actively studied for utilizing automated driving. However, the conventional detector has a large network structure, and the real-time property is impaired. The effectiveness of the detector constructed as described above is verified using datasets. As a result of this experiment, the proposed model is able to output 3D bounding boxes and detect people whose part of the body is hidden. Further, the processing speed of the model is 44.35 fps.