 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Output Gaussian Processes with Functional Data: A Study on Coastal Flood Hazard Assessment
Jul 28, 2020
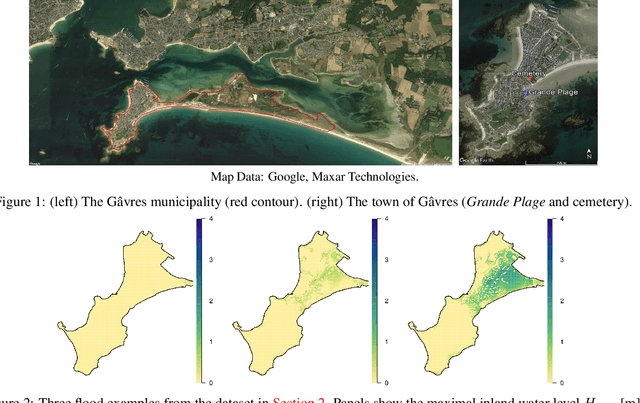

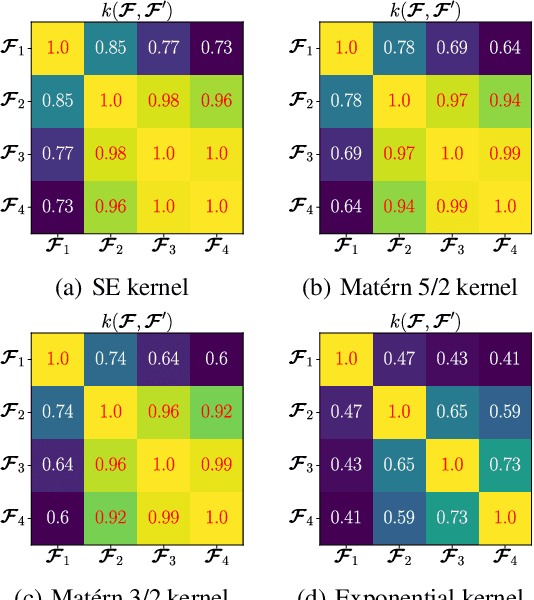
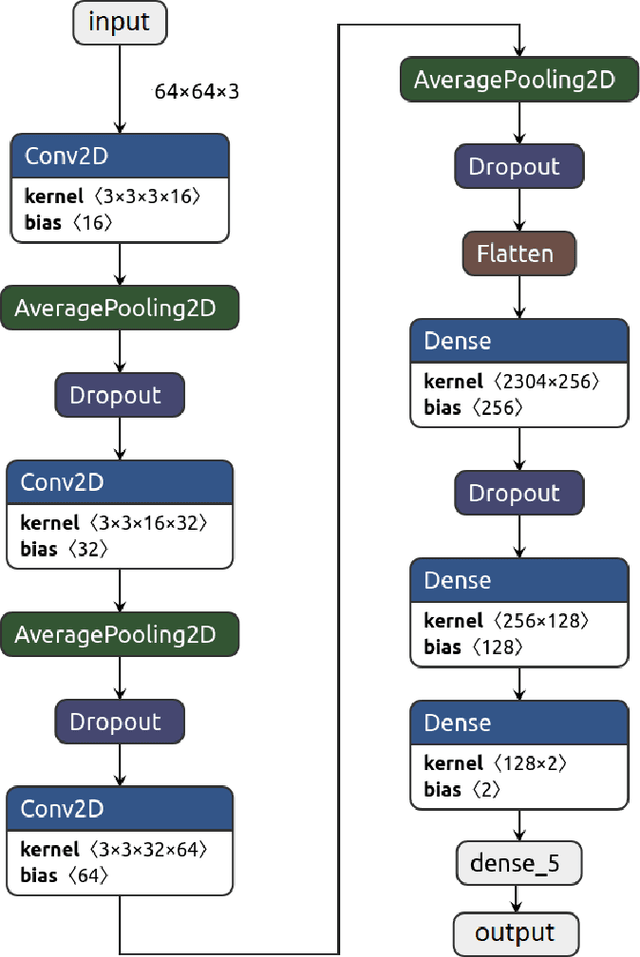
Most of the existing coastal flood Forecast and Early-Warning Systems do not model the flood, but instead, rely on the prediction of hydrodynamic conditions at the coast and on expert judgment. Recent scientific contributions are now capable to precisely model flood events, even in situations where wave overtopping plays a significant role. Such models are nevertheless costly-to-evaluate and surrogate ones need to be exploited for substantial computational savings. For the latter models, the hydro-meteorological forcing conditions (inputs) or flood events (outputs) are conveniently parametrised into scalar representations. However, they neglect the fact that inputs are actually functions (more precisely, time series), and that floods spatially propagate inland. Here, we introduce a multi-output Gaussian process model accounting for both criteria. On various examples, we test its versatility for both learning spatial maps and inferring unobserved ones. We demonstrate that efficient implementations are obtained by considering tensor-structured data and/or sparse-variational approximations. Finally, the proposed framework is applied on a coastal application aiming at predicting flood events. We conclude that accurate predictions are obtained in the order of minutes rather than the couples of days required by dedicated hydrodynamic simulators.
FireNet: A Specialized Lightweight Fire & Smoke Detection Model for Real-Time IoT Applications
May 28, 2019

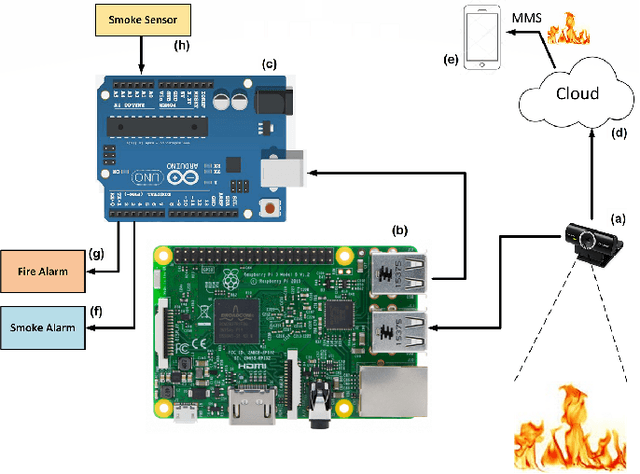
Fire disasters typically result in lot of loss to life and property. It is therefore imperative that precise, fast, and possibly portable solutions to detect fire be made readily available to the masses at reasonable prices. There have been several research attempts to design effective and appropriately priced fire detection systems with varying degrees of success. However, most of them demonstrate a trade-off between performance and model size (which decides the model's ability to be installed on portable devices). The work presented in this paper is an attempt to deal with both the performance and model size issues in one design. Toward that end, a `designed-from-scratch' neural network, named FireNet, is proposed which is worthy on both the counts: (i) it has better performance than existing counterparts, and (ii) it is lightweight enough to be deploy-able on embedded platforms like Raspberry Pi. Performance evaluations on a standard dataset, as well as our own newly introduced custom-compiled fire dataset, are extremely encouraging.
Real-Time Action Detection in Video Surveillance using Sub-Action Descriptor with Multi-CNN
Oct 10, 2017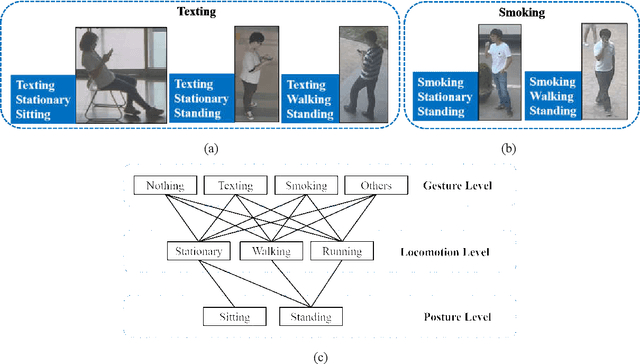

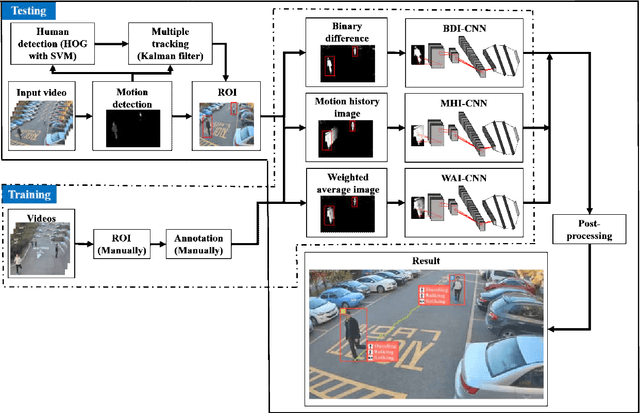
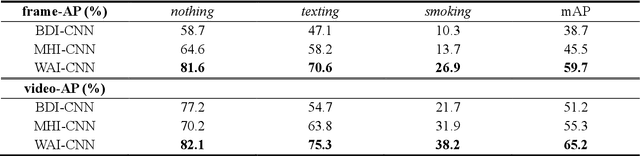
When we say a person is texting, can you tell the person is walking or sitting? Emphatically, no. In order to solve this incomplete representation problem, this paper presents a sub-action descriptor for detailed action detection. The sub-action descriptor consists of three levels: the posture, the locomotion, and the gesture level. The three levels give three sub-action categories for one action to address the representation problem. The proposed action detection model simultaneously localizes and recognizes the actions of multiple individuals in video surveillance using appearance-based temporal features with multi-CNN. The proposed approach achieved a mean average precision (mAP) of 76.6% at the frame-based and 83.5% at the video-based measurement on the new large-scale ICVL video surveillance dataset that the authors introduce and make available to the community with this paper. Extensive experiments on the benchmark KTH dataset demonstrate that the proposed approach achieved better performance, which in turn boosts the action recognition performance over the state-of-the-art. The action detection model can run at around 25 fps on the ICVL and more than 80 fps on the KTH dataset, which is suitable for real-time surveillance applications.
Consistency Guided Scene Flow Estimation
Jun 19, 2020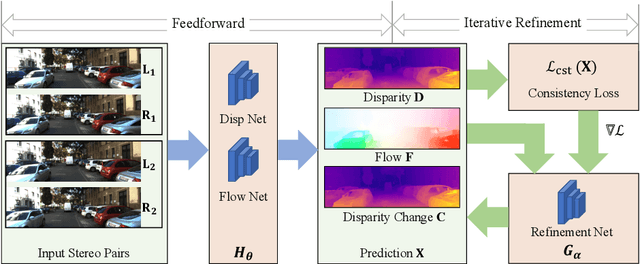


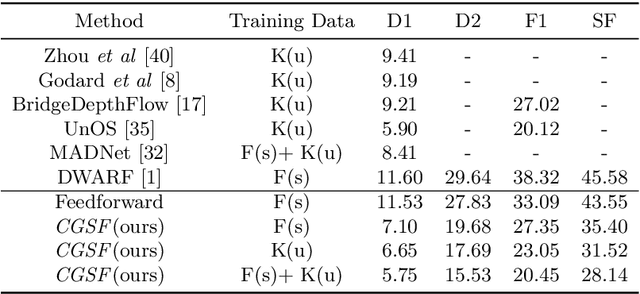
We present Consistency Guided Scene Flow Estimation (CGSF), a framework for joint estimation of 3D scene structure and motion from stereo videos. The model takes two temporal stereo pairs as input, and predicts disparity and scene flow. The model self-adapts at test time by iteratively refining its predictions. The refinement process is guided by a consistency loss, which combines stereo and temporal photo-consistency with a geometric term that couples the disparity and 3D motion. To handle the noise in the consistency loss, we further propose a learned, output refinement network, which takes the initial predictions, the loss, and the gradient as input, and efficiently predicts a correlated output update. We demonstrate with extensive experiments that the proposed model can reliably predict disparity and scene flow in many challenging scenarios, and achieves better generalization than the state-of-the-arts.
Self-Supervised Nuclei Segmentation in Histopathological Images Using Attention
Jul 16, 2020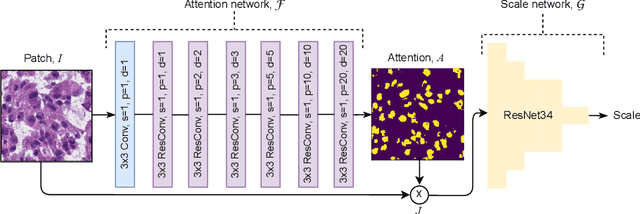
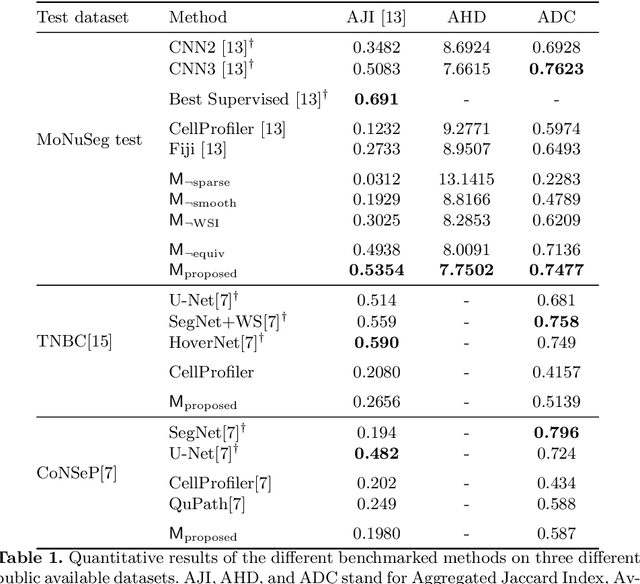

Segmentation and accurate localization of nuclei in histopathological images is a very challenging problem, with most existing approaches adopting a supervised strategy. These methods usually rely on manual annotations that require a lot of time and effort from medical experts. In this study, we present a self-supervised approach for segmentation of nuclei for whole slide histopathology images. Our method works on the assumption that the size and texture of nuclei can determine the magnification at which a patch is extracted. We show that the identification of the magnification level for tiles can generate a preliminary self-supervision signal to locate nuclei. We further show that by appropriately constraining our model it is possible to retrieve meaningful segmentation maps as an auxiliary output to the primary magnification identification task. Our experiments show that with standard post-processing, our method can outperform other unsupervised nuclei segmentation approaches and report similar performance with supervised ones on the publicly available MoNuSeg dataset. Our code and models are available online to facilitate further research.
Self-supervision on Unlabelled OR Data for Multi-person 2D/3D Human Pose Estimation
Jul 16, 2020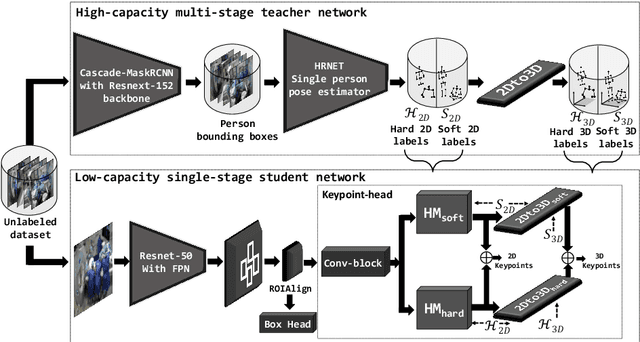
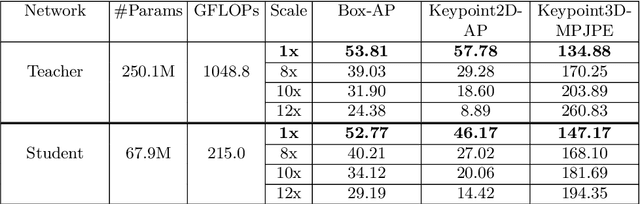

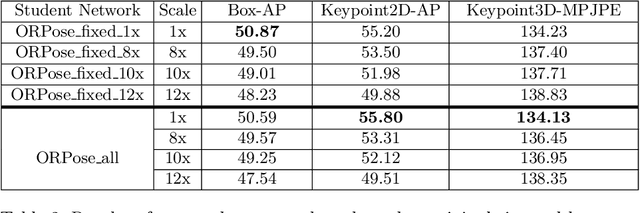
2D/3D human pose estimation is needed to develop novel intelligent tools for the operating room that can analyze and support the clinical activities. The lack of annotated data and the complexity of state-of-the-art pose estimation approaches limit, however, the deployment of such techniques inside the OR. In this work, we propose to use knowledge distillation in a teacher/student framework to harness the knowledge present in a large-scale non-annotated dataset and in an accurate but complex multi-stage teacher network to train a lightweight network for joint 2D/3D pose estimation. The teacher network also exploits the unlabeled data to generate both hard and soft labels useful in improving the student predictions. The easily deployable network trained using this effective self-supervision strategy performs on par with the teacher network on \emph{MVOR+}, an extension of the public MVOR dataset where all persons have been fully annotated, thus providing a viable solution for real-time 2D/3D human pose estimation in the OR.
MutaGAN: A Seq2seq GAN Framework to Predict Mutations of Evolving Protein Populations
Aug 26, 2020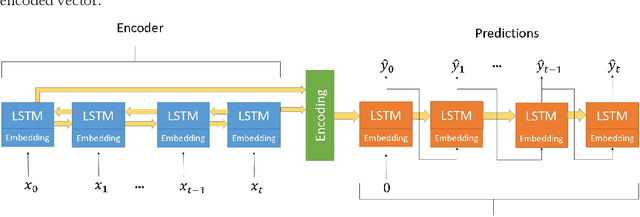
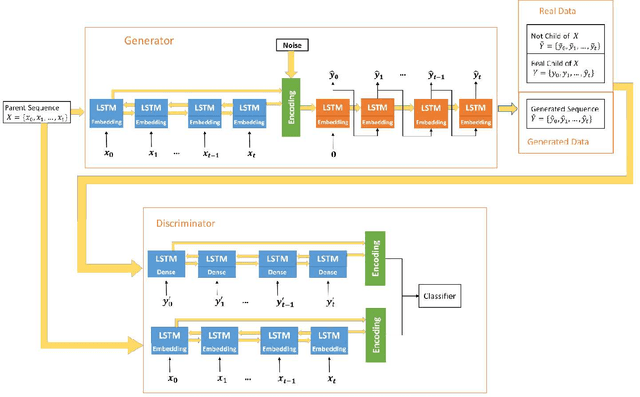
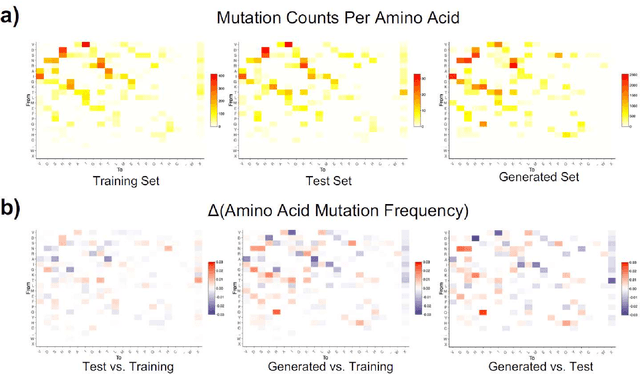
The ability to predict the evolution of a pathogen would significantly improve the ability to control, prevent, and treat disease. Despite significant progress in other problem spaces, deep learning has yet to contribute to the issue of predicting mutations of evolving populations. To address this gap, we developed a novel machine learning framework using generative adversarial networks (GANs) with recurrent neural networks (RNNs) to accurately predict genetic mutations and evolution of future biological populations. Using a generalized time-reversible phylogenetic model of protein evolution with bootstrapped maximum likelihood tree estimation, we trained a sequence-to-sequence generator within an adversarial framework, named MutaGAN, to generate complete protein sequences augmented with possible mutations of future virus populations. Influenza virus sequences were identified as an ideal test case for this deep learning framework because it is a significant human pathogen with new strains emerging annually and global surveillance efforts have generated a large amount of publicly available data from the National Center for Biotechnology Information's (NCBI) Influenza Virus Resource (IVR). MutaGAN generated "child" sequences from a given "parent" protein sequence with a median Levenshtein distance of 2.00 amino acids. Additionally, the generator was able to augment the majority of parent proteins with at least one mutation identified within the global influenza virus population. These results demonstrate the power of the MutaGAN framework to aid in pathogen forecasting with implications for broad utility in evolutionary prediction for any protein population.
L^2-GCN: Layer-Wise and Learned Efficient Training of Graph Convolutional Networks
Apr 04, 2020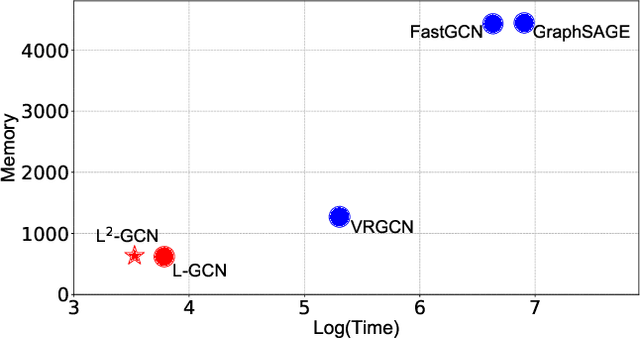

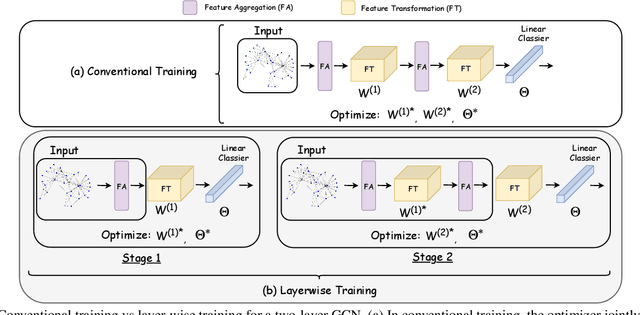
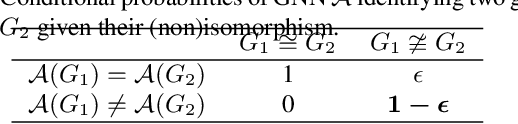
Graph convolution networks (GCN) are increasingly popular in many applications, yet remain notoriously hard to train over large graph datasets. They need to compute node representations recursively from their neighbors. Current GCN training algorithms suffer from either high computational costs that grow exponentially with the number of layers, or high memory usage for loading the entire graph and node embeddings. In this paper, we propose a novel efficient layer-wise training framework for GCN (L-GCN), that disentangles feature aggregation and feature transformation during training, hence greatly reducing time and memory complexities. We present theoretical analysis for L-GCN under the graph isomorphism framework, that L-GCN leads to as powerful GCNs as the more costly conventional training algorithm does, under mild conditions. We further propose L^2-GCN, which learns a controller for each layer that can automatically adjust the training epochs per layer in L-GCN. Experiments show that L-GCN is faster than state-of-the-arts by at least an order of magnitude, with a consistent of memory usage not dependent on dataset size, while maintaining comparable prediction performance. With the learned controller, L^2-GCN can further cut the training time in half. Our codes are available at https://github.com/Shen-Lab/L2-GCN.
Human-like Energy Management Based on Deep Reinforcement Learning and Historical Driving Experiences
Jul 16, 2020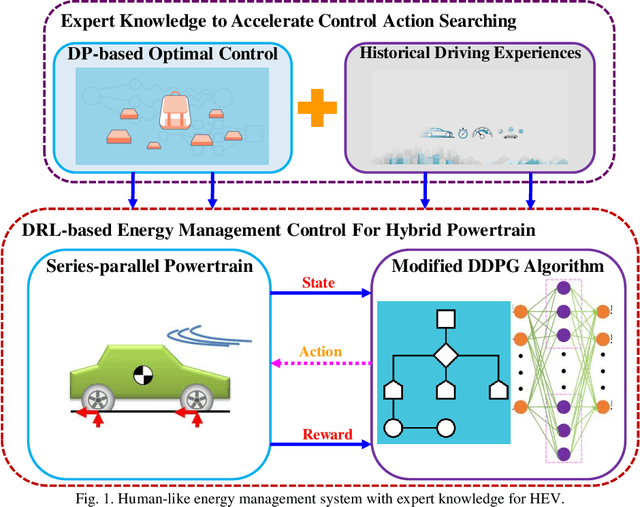
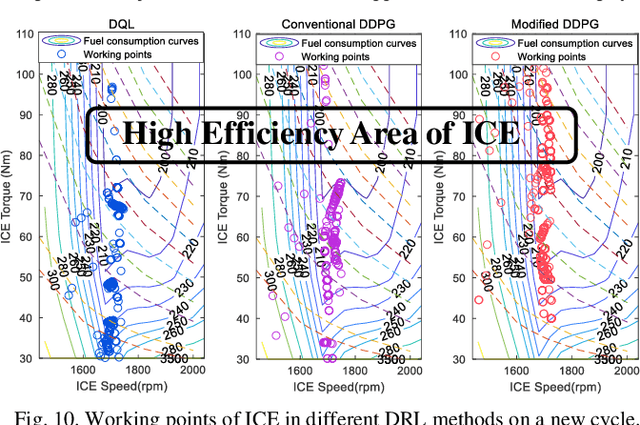
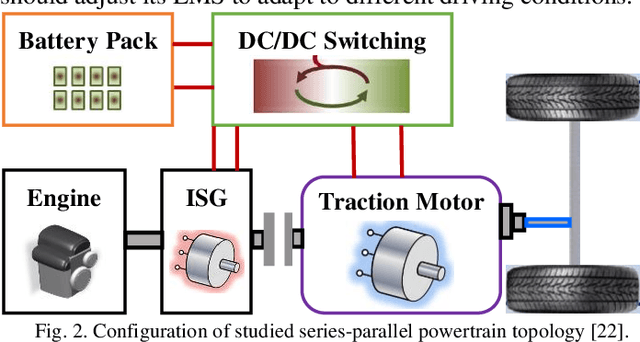

Development of hybrid electric vehicles depends on an advanced and efficient energy management strategy (EMS). With online and real-time requirements in mind, this article presents a human-like energy management framework for hybrid electric vehicles according to deep reinforcement learning methods and collected historical driving data. The hybrid powertrain studied has a series-parallel topology, and its control-oriented modeling is founded first. Then, the distinctive deep reinforcement learning (DRL) algorithm, named deep deterministic policy gradient (DDPG), is introduced. To enhance the derived power split controls in the DRL framework, the global optimal control trajectories obtained from dynamic programming (DP) are regarded as expert knowledge to train the DDPG model. This operation guarantees the optimality of the proposed control architecture. Moreover, the collected historical driving data based on experienced drivers are employed to replace the DP-based controls, and thus construct the human-like EMSs. Finally, different categories of experiments are executed to estimate the optimality and adaptability of the proposed human-like EMS. Improvements in fuel economy and convergence rate indicate the effectiveness of the constructed control structure.
Bayesian inference of dynamics from partial and noisy observations using data assimilation and machine learning
Jan 17, 2020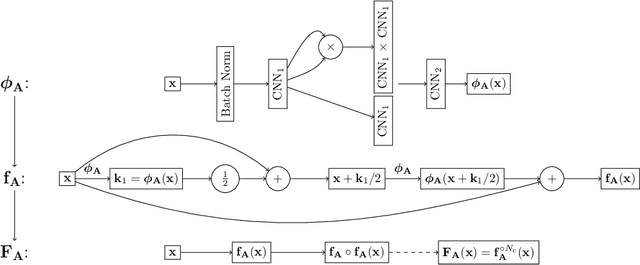
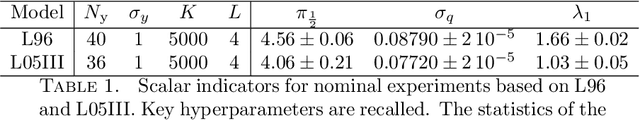
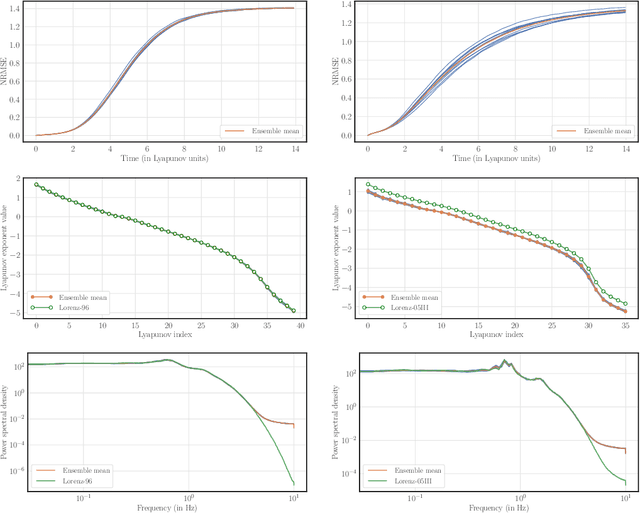
The reconstruction from observations of high-dimensional chaotic dynamics such as geophysical flows is hampered by (i) the partial and noisy observations that can realistically be obtained, (ii) the need to learn from long time series of data, and (iii) the unstable nature of the dynamics. To achieve such inference from the observations over long time series, it has been suggested to combine data assimilation and machine learning in several ways. We show how to unify these approaches from a Bayesian perspective using expectation-maximization and coordinate descents. Implementations and approximations of these methods are also discussed. Finally, we numerically and successfully test the approach on two relevant low-order chaotic models with distinct identifiability.